8月17日から始めた旧ブログのアーカイブ化の続きです。WebページやHTMLをPDF化するコマンドラインツールwkhtmltopdfを使い(Perlスクリプトから)、寝てる間に全693記事をPDF化できました。
実行環境
• Windows7 x64 + Cygwin 2.5.1 + ConEmu 150813g
• Windows版wkhtmltopdf 0.12.3.2
• 管理者権限ユーザ
コマンドラインツールwkhtmltopdfの準備&テスト
WebページをPDF化する製品やツールはいくつかありますが、いま自分にとって決定版がこれ。オープンソースのコマンドラインツールで、Windows用バイナリもあって導入が簡単。公式サイト ↓ではHTMLファイルからの変換ツールに見えながら、実はWebページをほぼそのまま(ブラウザで印刷するのと同様に)PDF化できます。
 公式サイトのDownload → wkhtmltox-0.12.3.2_msvc2013-win64.exeをインストール。ポータブル版は無いですが、インストール後にプログラムフォルダごとコピーすれば普通に使用可(元はアンインストールしてOK)。最低限、プログラムフォルダ ↓ のbin下のwkhtmltopdf.exeとDLLの2ファイルで今回の用途に足ります。
公式サイトのDownload → wkhtmltox-0.12.3.2_msvc2013-win64.exeをインストール。ポータブル版は無いですが、インストール後にプログラムフォルダごとコピーすれば普通に使用可(元はアンインストールしてOK)。最低限、プログラムフォルダ ↓ のbin下のwkhtmltopdf.exeとDLLの2ファイルで今回の用途に足ります。
wkhtmltopdf
|-- bin/
| |-- wkhtmltoimage.exe
| |-- wkhtmltopdf.exe
| +-- wkhtmltox.dll
|
|-- include/
+-- lib/
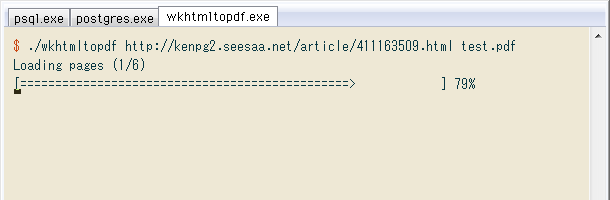
↓ 早速テスト。旧ブログの1記事をtest.pdfに変換します。普通にコマンドプロンプト上で使えますが、後工程に合わせてCygwin on ConEmuで実行。起動に少し時間がかかり、やがてWebからのダウンロードが始まり…
$ ./wkhtmltopdf http://kenpg2.seesaa.net/article/411163509.html test.pdf
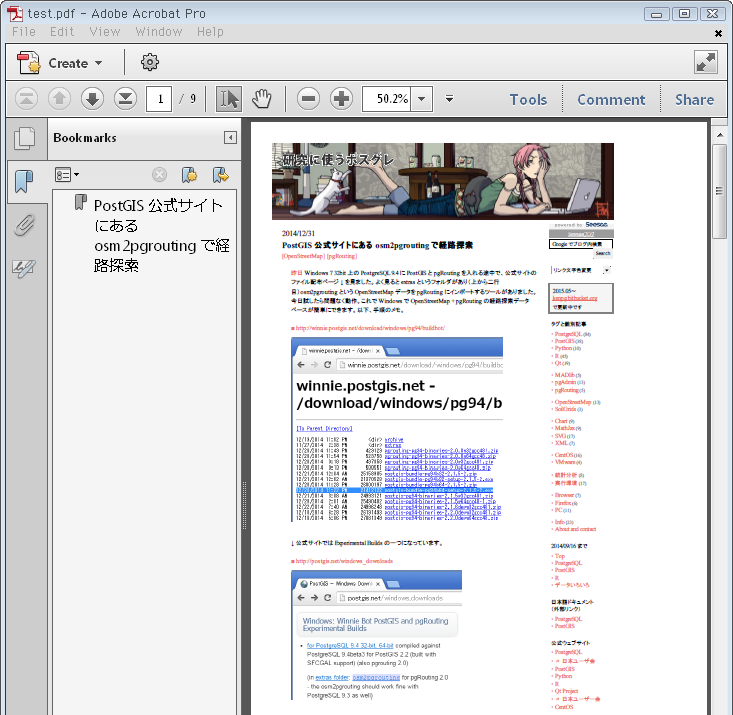
 ↓ 正常終了した様子と、実際出力されたPDF(468kB)
↓ 正常終了した様子と、実際出力されたPDF(468kB)
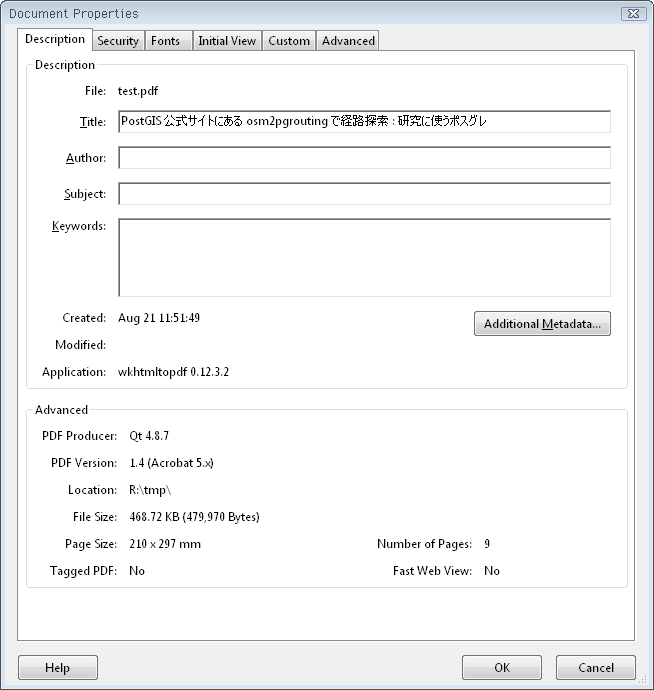
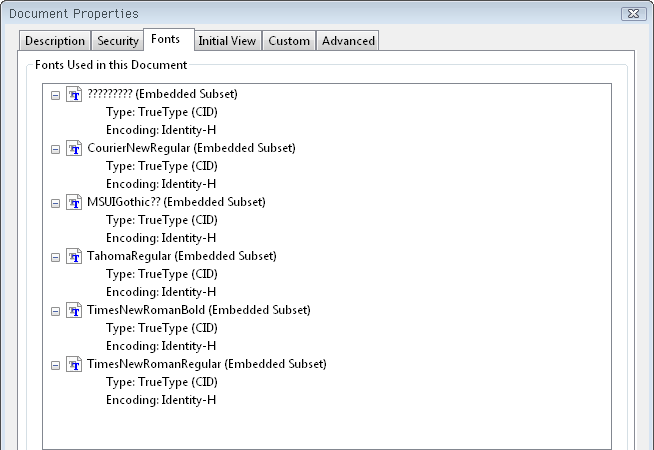
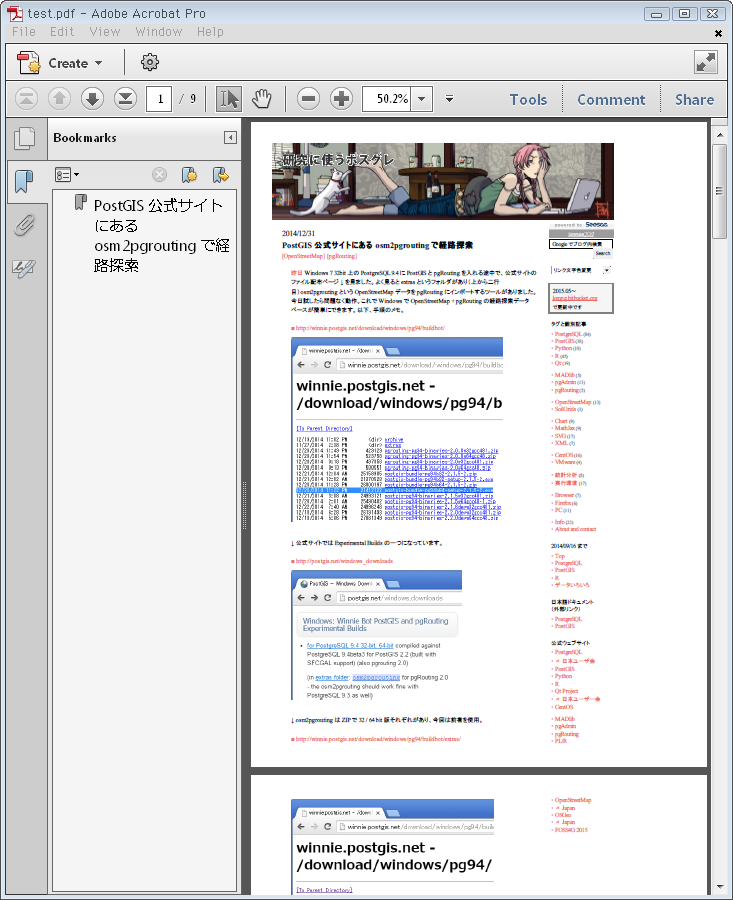 ↓ WebページのタイトルがそのままPDFのタイトルになってます。フォントは全て埋め込み&画像は無劣化、とアーカイブにぴったり。これらはオプションで変更できます。
↓ WebページのタイトルがそのままPDFのタイトルになってます。フォントは全て埋め込み&画像は無劣化、とアーカイブにぴったり。これらはオプションで変更できます。
 詳細は省きますがリンクもきちんと反映されてました。動画はさすがに埋め込まれてませんが、代替テキストと画像はあり。
↓ Webアクセス時のデフォルトのUA。wkhtmltopdfという語が入ってます。UAはオプション--custom-headerで変更可能。
詳細は省きますがリンクもきちんと反映されてました。動画はさすがに埋め込まれてませんが、代替テキストと画像はあり。
↓ Webアクセス時のデフォルトのUA。wkhtmltopdfという語が入ってます。UAはオプション--custom-headerで変更可能。
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/534.34 (KHTML, like Gecko) wkhtmltopdf Safari/534.34
全てのオプションはドキュメント(auto generated documentation)参照。ただしコマンドラインヘルプと同じもので、余り見やすくないです。
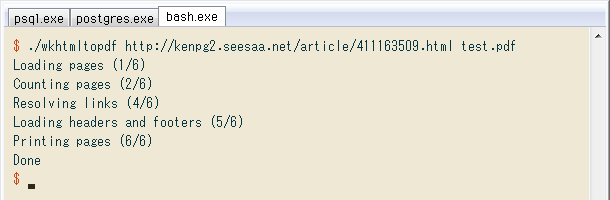
他の記事をいくつかテストしたところローマ数字等が文字化けしましたが、Webサイトの文字コードに合わせてオプション --encoding sjis を追加して解決。またブログ運営側が挿入するIFRAME(たぶん広告)読み込みが時々エラーになり、そのままではPDFが出力されないところ、オプション --load-error-handling ignore を付けてスルーすれば良いと分かりました。
PerlスクリプトでWeb上の全693記事をPDF変換
前項で一つのURL→PDF保存の準備が整ったので、後は単純に旧ブログ(Seesaa)の全記事リストTSV(8月17日に作成済)でループするだけ。TSVを再掲します。↓
» kenpg_seesaa_lists.tsv.txt(693 rows, 78.4 kB)
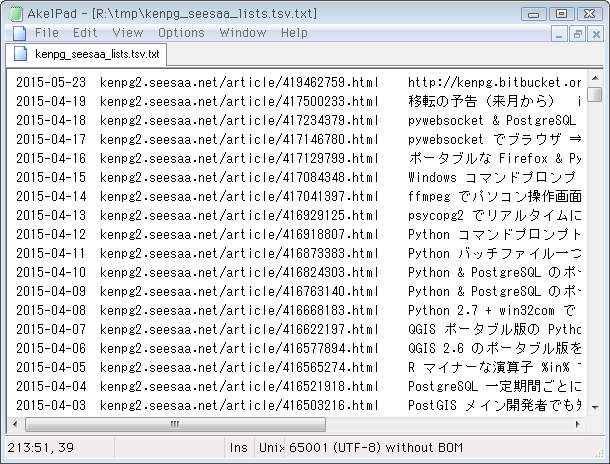 ↓ 適当な作業ディレクトリに、使うもの一式を入れました。上のTSV、wkhtmltopdf、実行用のPerlスクリプト(後掲)、ファイル保存用ディレクトリ。この際PDFだけでなくHTMLも取得します(記事本文の検索用)。
↓ 適当な作業ディレクトリに、使うもの一式を入れました。上のTSV、wkhtmltopdf、実行用のPerlスクリプト(後掲)、ファイル保存用ディレクトリ。この際PDFだけでなくHTMLも取得します(記事本文の検索用)。
working_dir
|-- kenpg_seesaa_lists.tsv.txt
|-- wkhtmltopdf.exe
|-- wkhtmltox.dll
|-- tmp.pl
|-- html/
+-- pdf/
↓ 作成したPerlスクリプト。中断&再開した時のため、保存ファイルがあればスキップします。wkhtmltopdfとは別にHTMLだけcURLで取得、iconvで文字コードをUTF-8にして保存。wkhtmltopdfのオプションで、PDFのタイトルをURLに変えました。
open F, "kenpg_seesaa_lists.tsv.txt";
while(<F>) {
/^([^\t]+)\t([^\t]+?(\d+)\.html)/;
$url = "http://$2";
print("$url\n");
$cmd = "";
$html = "html/$1_$3.html";
if (! -f $html) {
$cmd .= "curl $url | iconv -f SHIFT_JISX0213 -t utf8 > $html;"
}
$pdf = "pdf/$1_$3.pdf";
if (! -f $pdf) {
$cmd .= "wkhtmltopdf";
$cmd .= " --encoding sjis ";
$cmd .= " --load-error-handling ignore ";
$cmd .= " --title $url ";
$cmd .= " $url $pdf";
}
system($cmd);
}
↓ 作業ディレクトリに移って開始。コンソールの画像が1記事分の処理で、最初にcURLの、続いてwkhtmltopdfの進捗表示が出てます。
$ cd 'r:/tmp'
$ mkdir -p html pdf
$ perl tmp.pl
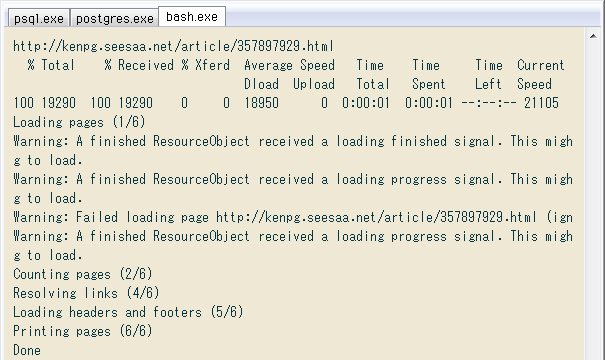 Warningは前項の最後で書いたIFRAME等の読み込みエラーで、オプション --load-error-handling ignore によってスルーするので問題なし。時々はWarningでなくErrorという別の表示があったものの、記事PDFは正常に保存されるようです。
昨夜寝る前にスクリプトを起動して、今朝見たら ↓ 無事に全693記事のHTML&PDF保存が終わってました。それぞれのファイルサイズ最小のを開いて、エラーが起きてないことを確認。本当の確認は全ファイルを開いて見ることですが、そんなに暇ではないのでとりあえず良しとします。
Warningは前項の最後で書いたIFRAME等の読み込みエラーで、オプション --load-error-handling ignore によってスルーするので問題なし。時々はWarningでなくErrorという別の表示があったものの、記事PDFは正常に保存されるようです。
昨夜寝る前にスクリプトを起動して、今朝見たら ↓ 無事に全693記事のHTML&PDF保存が終わってました。それぞれのファイルサイズ最小のを開いて、エラーが起きてないことを確認。本当の確認は全ファイルを開いて見ることですが、そんなに暇ではないのでとりあえず良しとします。
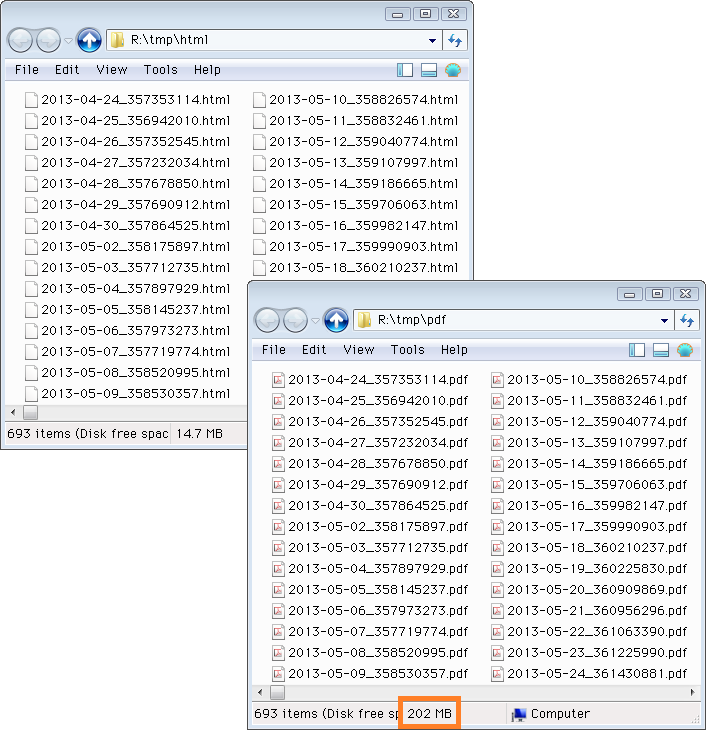 所要時間は2時間弱で、コンテンツや通信速度等によりますが概ね「1時間で350サイト」くらい。PDFは全てフォント埋め込み&画像無劣化なのでサイズが大きく、合計で202MBになりました(上の画像の囲み)。1ファイルに圧縮すると ↓ 約137MB。
所要時間は2時間弱で、コンテンツや通信速度等によりますが概ね「1時間で350サイト」くらい。PDFは全てフォント埋め込み&画像無劣化なのでサイズが大きく、合計で202MBになりました(上の画像の囲み)。1ファイルに圧縮すると ↓ 約137MB。
$ tar -acf ../pdf.tar.xz *.pdf
$ ls ../pdf.tar.xz
-rwxrwx---+ 1 Administrators None 137087996 Aug 21 13:14 ../pdf.tar.xz
次はHTML全文検索の準備
今回、HTMLはダウンロードしただけ。これを元に、記事本文を全文検索できるようにします。Biubucketには静的コンテンツしか置けないから、外部サーバも用意して。PDFの置き場所(個々の202MB+一括の137MB)も含め、少し考えます。