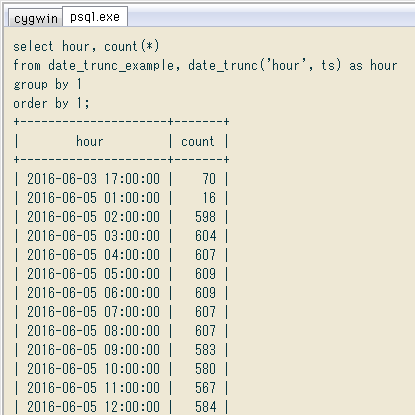
昔からある関数で基本ですが、昨日time型を使ったついでに。時系列集計で1時間とか1日単位など単純な場合、↓ こんな風にdate_trunc関数で丸めて集計するのが手軽です。関数名はdateとあるけど時刻単位も可。ドキュメントはこちら。
select hour, count(*)
from date_trunc_example, date_trunc('hour', ts) as hour
group by 1
order by 1;
+---------------------+-------+
| hour | count |
+---------------------+-------+
| 2016-06-03 17:00:00 | 70 |
| 2016-06-05 01:00:00 | 16 |
| 2016-06-05 02:00:00 | 598 |
| 2016-06-05 03:00:00 | 604 |
| 2016-06-05 04:00:00 | 607 |
| 2016-06-05 05:00:00 | 609 |
| 2016-06-05 06:00:00 | 609 |
| 2016-06-05 07:00:00 | 607 |
| 2016-06-05 08:00:00 | 607 |
| 2016-06-05 09:00:00 | 583 |
...
 ↓ date_trunc関数の動作の確認。数で言えば切り捨てで、「○時~○時」などの範囲を表すのではなくその起点です。
↓ date_trunc関数の動作の確認。数で言えば切り捨てで、「○時~○時」などの範囲を表すのではなくその起点です。
select hour, ts :: time
from date_trunc_example,
date_trunc('hour', ts) as hour;
+---------------------+-----------------+
| hour | ts |
+---------------------+-----------------+
| 2016-06-03 17:00:00 | 17:11:50.481619 |
| 2016-06-03 17:00:00 | 17:26:40.752305 |
| 2016-06-03 17:00:00 | 17:27:27.756976 |
| 2016-06-03 17:00:00 | 17:29:07.201976 |
| 2016-06-03 17:00:00 | 17:29:33.727976 |
...
↓ 日単位の例。時刻は不要なので日付型にキャストしてます。
select day :: date, count(*)
from date_trunc_example, date_trunc('day', ts) as day
group by 1
order by 1;
+------------+-------+
| day | count |
+------------+-------+
| 2016-06-03 | 70 |
| 2016-06-05 | 9516 |
| 2016-06-06 | 1575 |
| 2016-06-07 | 147 |
| 2016-06-08 | 3923 |
| 2016-06-09 | 2842 |
+------------+-------+
(6 rows)
↓ 週単位の例。月曜日始まりの括りになります。
select week :: date,
extract(dow from week), count(*)
from date_trunc_example, date_trunc('week', ts) as week
group by 1, 2
order by 1;
+------------+-----------+-------+
| week | date_part | count |
+------------+-----------+-------+
| 2016-05-30 | 1 | 9586 |
| 2016-06-06 | 1 | 8487 |
+------------+-----------+-------+
(2 rows)
↓ 用いたサンプルデータ。タイムスタンプと数値の2列のみ、約18,000行のタブ区切りテキスト。必要なら自由に使って下さい。適当なテーブルを作ってCOPYコマンドでインポートする例が、下のクエリです。
» date_trunc_example.tsv.zip (168kb)
create table date_trunc_example (
ts timestamp, val numeric(9,2));
copy date_trunc_example from '/date_trunc_example.tsv'
(format csv, delimiter E'\t', header true);
select * from date_trunc_example;
+----------------------------+---------+
| ts | val |
+----------------------------+---------+
| 2016-06-03 17:11:50.481619 | 79280.3 |
| 2016-06-03 17:26:40.752305 | 73544.0 |
| 2016-06-03 17:27:27.756976 | 73767.6 |
| 2016-06-03 17:29:07.201976 | 73270.7 |
| 2016-06-03 17:29:33.727976 | 70783.2 |
| 2016-06-03 17:29:51.441976 | 70286.2 |
| 2016-06-03 17:30:08.496976 | 72505.6 |
| 2016-06-03 17:30:17.230976 | 70834.9 |
| 2016-06-03 17:30:38.500976 | 70561.5 |
| 2016-06-03 17:30:51.788976 | 70109.1 |
...
Rとかでグラフ化するのが分かっている場合、時刻の起点でなく「時刻範囲の中間」になってると軸の調整が不要かも。そのために「範囲の半分」を足す例です。↓
select hour + '30minutes', count(*)
from date_trunc_example, date_trunc('hour', ts) as hour
group by 1
order by 1;
+---------------------+-------+
| ?column? | count |
+---------------------+-------+
| 2016-06-03 17:30:00 | 70 |
| 2016-06-05 01:30:00 | 16 |
| 2016-06-05 02:30:00 | 598 |
| 2016-06-05 03:30:00 | 604 |
| 2016-06-05 04:30:00 | 607 |
| 2016-06-05 05:30:00 | 609 |
| 2016-06-05 06:30:00 | 609 |
| 2016-06-05 07:30:00 | 607 |
| 2016-06-05 08:30:00 | 607 |
| 2016-06-05 09:30:00 | 583 |
...
サンプルデータは「値が存在した時だけ」の記録なので集計単位が不連続になります。一方、値が存在しなかった時も含めて「最初から最後まで」の集計が必要なら ↓ こんな感じ。generate_series関数で全体の時間単位を発生させ、それと結合します。
with a as (
select hour, val
from date_trunc_example,
date_trunc('hour', ts) as hour
), b as (
select generate_series(
min(hour), max(hour), '1hour') as hour
from a
)
select hour, count(val)
from a right join b using (hour)
group by 1
order by 1;
+---------------------+-------+
| hour | count |
+---------------------+-------+
| 2016-06-03 17:00:00 | 70 |
| 2016-06-03 18:00:00 | 0 |
| 2016-06-03 19:00:00 | 0 |
| 2016-06-03 20:00:00 | 0 |
| 2016-06-03 21:00:00 | 0 |
| 2016-06-03 22:00:00 | 0 |
| 2016-06-03 23:00:00 | 0 |
| 2016-06-04 00:00:00 | 0 |
| 2016-06-04 01:00:00 | 0 |
| 2016-06-04 02:00:00 | 0 |
|...
| 2016-06-08 08:00:00 | 0 |
| 2016-06-08 09:00:00 | 0 |
| 2016-06-08 10:00:00 | 0 |
| 2016-06-08 11:00:00 | 39 |
| 2016-06-08 12:00:00 | 807 |
| 2016-06-08 13:00:00 | 657 |
| 2016-06-08 14:00:00 | 0 |
| 2016-06-08 15:00:00 | 0 |
| 2016-06-08 16:00:00 | 0 |
| 2016-06-08 17:00:00 | 0 |
| 2016-06-08 18:00:00 | 227 |
| 2016-06-08 19:00:00 | 787 |
| 2016-06-08 20:00:00 | 117 |
| 2016-06-08 21:00:00 | 523 |
| 2016-06-08 22:00:00 | 657 |
| 2016-06-08 23:00:00 | 109 |
| 2016-06-09 00:00:00 | 834 |
| 2016-06-09 01:00:00 | 808 |
| 2016-06-09 02:00:00 | 838 |
| 2016-06-09 03:00:00 | 362 |
+---------------------+-------+
(131 rows)
今回は簡単のため集約関数をcountに限りましたが、もちろん他の集約関数や計算もクエリ内で可能です。