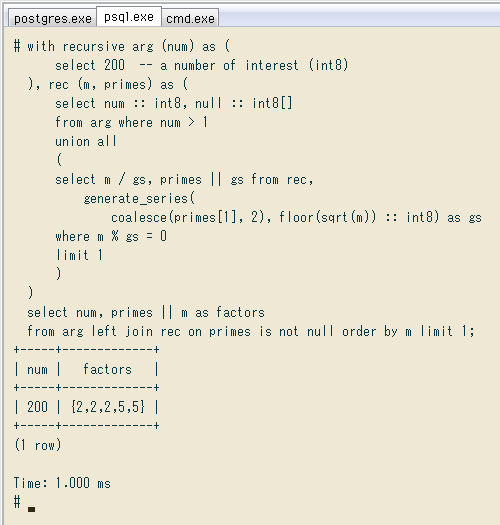
with recursive arg (num) as (
select 200 -- a number of interest (int8)
), rec (m, primes) as (
select num :: int8, null :: int8[]
from arg where num > 1
union all
(
select m / gs, primes || gs from rec,
generate_series(
coalesce(primes[1], 2), floor(sqrt(m)) :: int8) as gs
where m % gs = 0
limit 1
)
)
select num, primes || m as factors
from arg left join rec on primes is not null order by m limit 1;
+-----+-------------+
| num | factors |
+-----+-------------+
| 200 | {2,2,2,5,5} |
+-----+-------------+
↓ ストアド化。上の
create or replace function prime_factors(
in int8, out num int8, out factors int8[])
language sql immutable as
$$
with recursive arg (num) as (
select $1
-- select 200 -- for test
), rec (m, primes) as (
select num :: int8, null :: int8[]
from arg where num > 1
union all
(
select m / gs, primes || gs from rec,
generate_series(
coalesce(primes[1], 2), floor(sqrt(m)) :: int8) as gs
where m % gs = 0
limit 1
)
)
select num, primes || m as factors
from arg left join rec on primes is not null order by m limit 1;
$$;
-- test
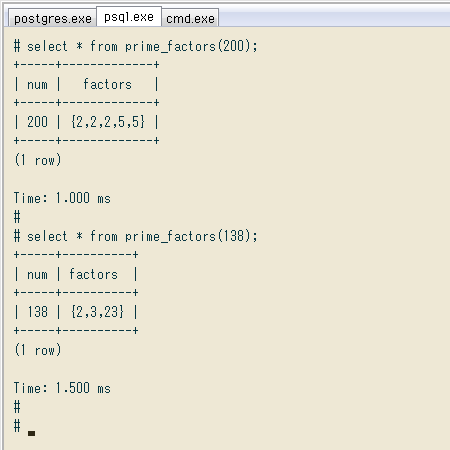
select * from prime_factors(200);
+-----+-------------+
| num | factors |
+-----+-------------+
| 200 | {2,2,2,5,5} |
+-----+-------------+
select * from prime_factors(138);
+-----+----------+
| num | factors |
+-----+----------+
| 138 | {2,3,23} |
+-----+----------+
引数が
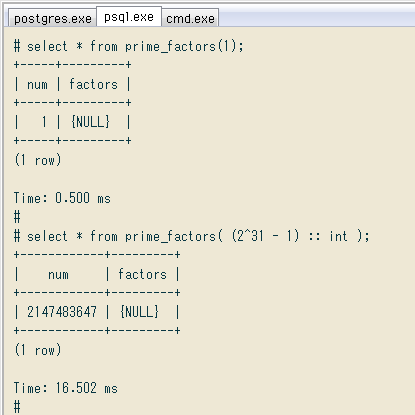
select * from prime_factors(1);
+-----+---------+
| num | factors |
+-----+---------+
| 1 | {NULL} |
+-----+---------+
select * from prime_factors( (2^31 - 1) :: int );
+------------+---------+
| num | factors |
+------------+---------+
| 2147483647 | {NULL} |
+------------+---------+
上のとおり
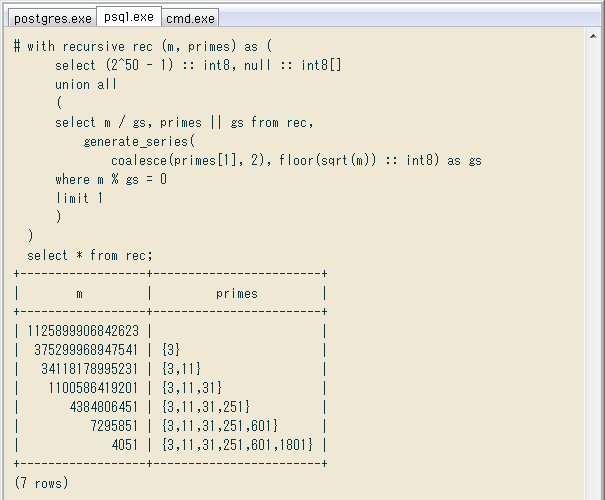
動作の流れを明示すると ↓ こんな感じで、「最小の約数を探し、見つかったらそれで割る」ことの再帰です。約数の探索は単純に
with recursive rec (m, primes) as (
select (2^50 - 1) :: int8, null :: int8[]
union all
(
select m / gs, primes || gs from rec,
generate_series(
coalesce(primes[1], 2), floor(sqrt(m)) :: int8) as gs
where m % gs = 0
limit 1
)
)
select * from rec;
+------------------+------------------------+
| m | primes |
+------------------+------------------------+
| 1125899906842623 | |
| 375299968947541 | {3} |
| 34118178995231 | {3,11} |
| 1100586419201 | {3,11,31} |
| 4384806451 | {3,11,31,251} |
| 7295851 | {3,11,31,251,601} |
| 4051 | {3,11,31,251,601,1801} |
+------------------+------------------------+
(7 rows)
このように無駄があるのと、そもそも
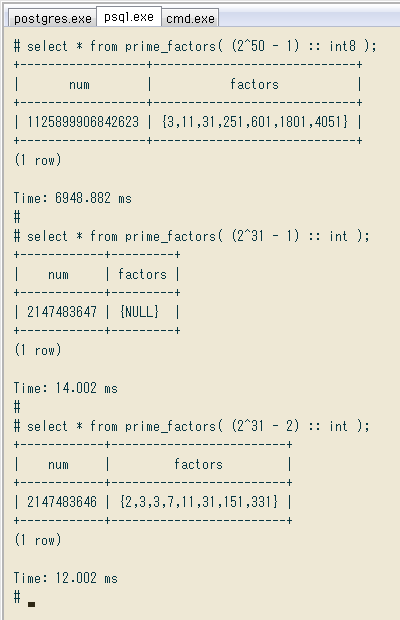
# \timing on
# select * from prime_factors( (2^50 - 1) :: int8 );
+------------------+-----------------------------+
| num | factors |
+------------------+-----------------------------+
| 1125899906842623 | {3,11,31,251,601,1801,4051} |
+------------------+-----------------------------+
(1 row)
Time: 6948.882 ms
# select * from prime_factors( (2^31 - 1) :: int );
+------------+---------+
| num | factors |
+------------+---------+
| 2147483647 | {NULL} |
+------------+---------+
(1 row)
Time: 14.002 ms
# select * from prime_factors( (2^31 - 2) :: int );
+------------+-------------------------+
| num | factors |
+------------+-------------------------+
| 2147483646 | {2,3,3,7,11,31,151,331} |
+------------+-------------------------+
(1 row)
Time: 12.002 ms
速度だけ考えたら再帰クエリでやる意味はなく、自分としては