Windows標準の文字コード表(charmap.exe)が使いにくいので、PostgreSQLのascii関数とchr関数などでクエリを作り、pgAdminで動作確認しました。実行環境はWindows7 32bit + PostgreSQL Portable 9.4.1 + pgAdmin 1.20、データベースの文字コードはUTF-8です。下のクエリのテキストはこちら。
charmap.exeの使いにくい点
Windows7の場合です。アプリケーション名は「文字コード表」だけど、一覧できるのはコードでなく文字本体で、実質「文字パレット」的な(記号や文字などを探して他のアプリに持っていく)存在だと思います。これがまぁ、そもそもOSの添付アプリに期待するのが無理かもしれませんが、
- 文字サイズが小さく、変えられない。
- 選択中の文字だけ大きく表示されるけど、その上下左右が隠れる。(下の画像のように)
- 選択中にCtrl+Cを押してもコビーされない。また複数の文字選択ができない。
- 文字検索できない。検索に使えるのはUnicodeコードポイントか「文字の名前」(?)だけ。
- フォントにない文字は飛ばされるので、同じ文字でもフォントによって位置が異なる。
- フォントを変えると、最初の文字に戻る。
などなど、パレットとして使いづらいこと…。下のように記号を選んだり、➀~➉の丸付き数字を入力するとか、ちょっとしたフォルダ構造の説明用に罫線文字を入力する際、charmapを使わず、複数の文字拡大&選択&コピーができるといいな~と前から思ってました。
 そう言えばPostgreSQLでは、ascii関数とchr関数で「文字⇔Unicodeコードポイント」の相互変換ができ、pgAdminはクエリ結果を自由に拡大縮小できるので(Ctrl+マウスホイール)、簡単な文字パレットを表示するクエリを作り、よく検索する文字等と一緒に保存しておけば使えそう。というのが動機です。
そう言えばPostgreSQLでは、ascii関数とchr関数で「文字⇔Unicodeコードポイント」の相互変換ができ、pgAdminはクエリ結果を自由に拡大縮小できるので(Ctrl+マウスホイール)、簡単な文字パレットを表示するクエリを作り、よく検索する文字等と一緒に保存しておけば使えそう。というのが動機です。
クエリの原型
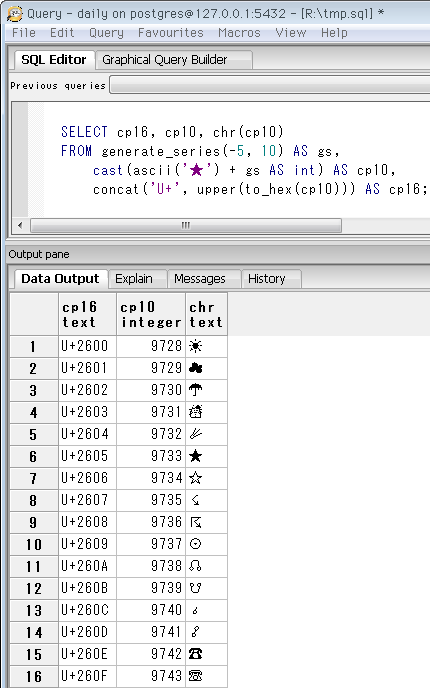
まず、ある文字を入力して、当該文字およびUnicodeコードポイントが近い文字を抽出するクエリは ↓ こんな感じ。例として「★」を入力し、コードポイントの前5個・後10個の文字を表示します。列のcp16は16進コードポイント、cp10が10進。これをHTMLの数値文字参照に使うこともでき、例えば16進は「☀」が☀、10進は「☂」が☂。( ← フォントによっては文字化けするかも)
SELECT cp16, cp10, chr(cp10)
FROM generate_series(-5, 10) AS gs,
cast(ascii('★') + gs AS int) AS cp10,
concat('U+', upper(to_hex(cp10))) AS cp16;
 クエリ中、下から2行目のcastに実質的な意味はなく、FROM句の後に式をそのまま書けないので「何もしない関数」の代わりです。
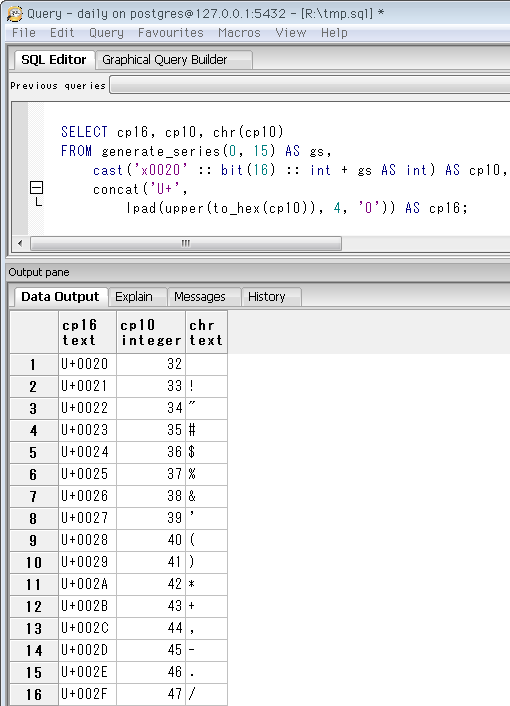
上記クエリの16進コードポイントは、2桁・3桁の場合を考慮していません。下のクエリはそれを考慮に入れ、さらに入力する文字を16進コードポイントで指定(ここではx0020、半角空白)する例。当該文字と、続く15字を表示しています。コードポイントから検索したい場合用。
クエリ中、下から2行目のcastに実質的な意味はなく、FROM句の後に式をそのまま書けないので「何もしない関数」の代わりです。
上記クエリの16進コードポイントは、2桁・3桁の場合を考慮していません。下のクエリはそれを考慮に入れ、さらに入力する文字を16進コードポイントで指定(ここではx0020、半角空白)する例。当該文字と、続く15字を表示しています。コードポイントから検索したい場合用。
SELECT cp16, cp10, chr(cp10)
FROM generate_series(0, 15) AS gs,
cast('x0020' :: bit(16) :: int + gs AS int) AS cp10,
concat('U+',
lpad(upper(to_hex(cp10)), 4, '0')) AS cp16;
 以上の「ある文字/16進コードポイントを指定して、それと連続する文字をまとめて取得する」クエリが原型になります。次に、この結果の文字だけを縦・横に並べて「文字コード表」に近づけます。
以上の「ある文字/16進コードポイントを指定して、それと連続する文字をまとめて取得する」クエリが原型になります。次に、この結果の文字だけを縦・横に並べて「文字コード表」に近づけます。
クエリ2:何文字かずつ1行にまとめる
前項で得た「連続する文字」を先頭から一つの文字列にし、指定した「1行当たりの文字数」で区切って表示します。クエリは ↓ こんな感じ。先頭aブロックがいわばパラメータ部分で、行数(nrow)、1行当たりの文字数(ncol)、先頭の文字(start)を指定し、残りの部分は常に共通。下の例は「●よりも20個前から、1行当たり20字で10行分の文字を表示する」ことになります。
WITH a (nrow, ncol, start) AS (
SELECT 10, 20, to_hex(ascii('●') - 20)
), b AS (
SELECT string_agg(chr(code0 + nrow2 * ncol + ncol2), '') AS str
FROM a, cast(concat('x', start) :: bit(16) AS int) AS code0,
generate_series(0, nrow - 1) AS nrow2,
generate_series(0, ncol - 1) AS ncol2
)
SELECT (regexp_matches(str, reg, 'g'))[1]
FROM a, b, concat('.{', a.ncol, '}') AS reg;
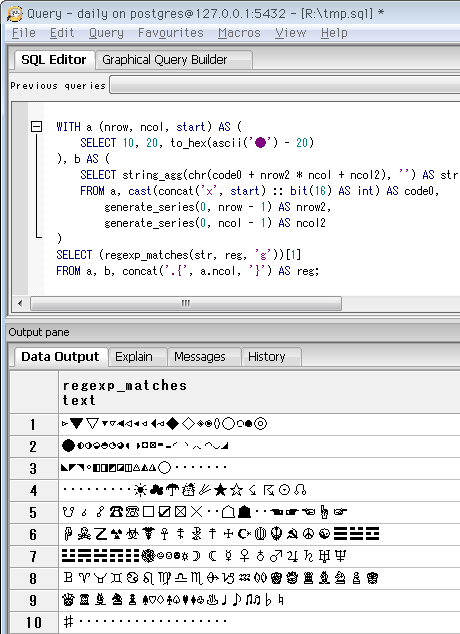 普通のプログラミング言語ならFORループ等でもっと単純に書けそうな気がしますが、SQLなのでちょっと分かりにくくなりました。WITH句のブロックbが、string_agg関数で一つながりの文字列を作っている所。最後のregexp_matches関数で、正規表現の「.{1行の文字数}」で行ごとに区切っています。
検索対象を、文字でなく16進コードポイントで指定すると ↓ こんな感じ。先頭aブロック以外は、上のクエリと同一です。
普通のプログラミング言語ならFORループ等でもっと単純に書けそうな気がしますが、SQLなのでちょっと分かりにくくなりました。WITH句のブロックbが、string_agg関数で一つながりの文字列を作っている所。最後のregexp_matches関数で、正規表現の「.{1行の文字数}」で行ごとに区切っています。
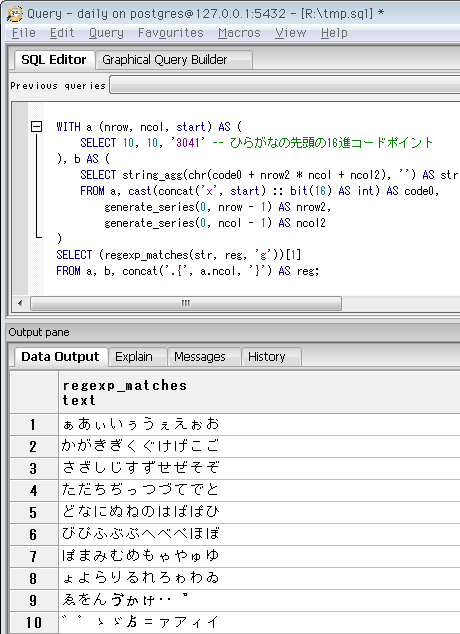
検索対象を、文字でなく16進コードポイントで指定すると ↓ こんな感じ。先頭aブロック以外は、上のクエリと同一です。
WITH a (nrow, ncol, start) AS (
SELECT 10, 10, '3041' -- ひらがなの先頭の16進コードポイント
), b AS (
SELECT string_agg(chr(code0 + nrow2 * ncol + ncol2), '') AS str
FROM a, cast(concat('x', start) :: bit(16) AS int) AS code0,
generate_series(0, nrow - 1) AS nrow2,
generate_series(0, ncol - 1) AS ncol2
)
SELECT (regexp_matches(str, reg, 'g'))[1]
FROM a, b, concat('.{', a.ncol, '}') AS reg;
クエリ3:1文字ずつ列に分けて完成
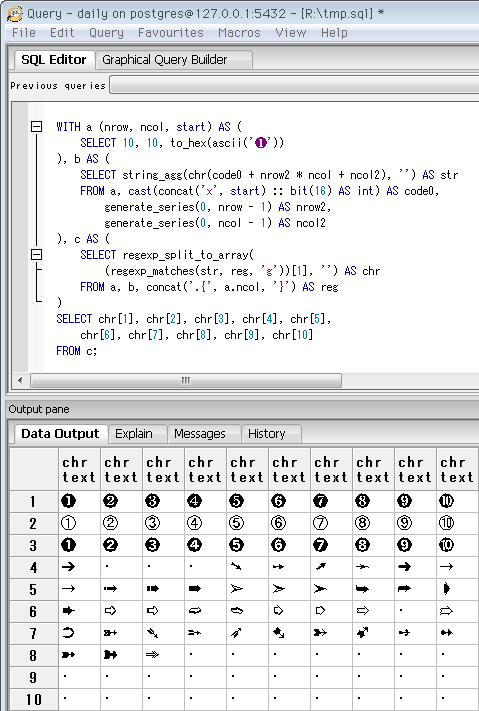
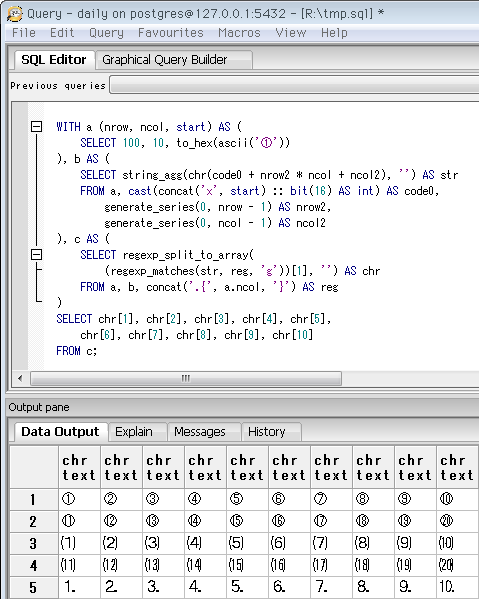
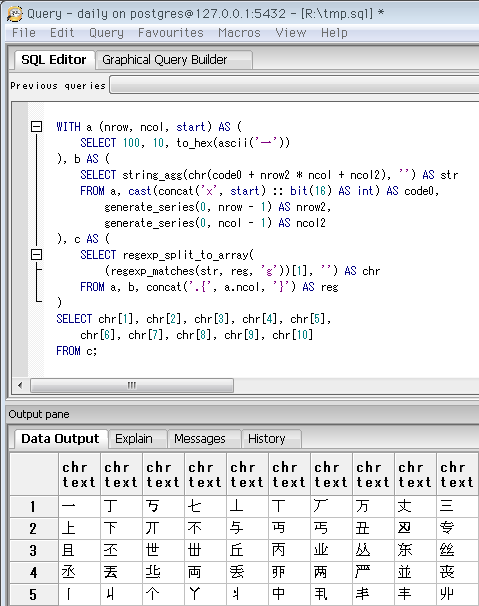
前項のクエリで「行に分ける」処理ができ、あとは各行を1文字ずつ1列に分ければ表形式の「文字パレット」風になります。↓ がそのクエリで、下が実行時の画像(冒頭の再掲)。
WITH a (nrow, ncol, start) AS (
SELECT 10, 10, to_hex(ascii('❶'))
), b AS (
SELECT string_agg(chr(code0 + nrow2 * ncol + ncol2), '') AS str
FROM a, cast(concat('x', start) :: bit(16) AS int) AS code0,
generate_series(0, nrow - 1) AS nrow2,
generate_series(0, ncol - 1) AS ncol2
), c AS (
SELECT regexp_split_to_array(
(regexp_matches(str, reg, 'g'))[1], '') AS chr
FROM a, b, concat('.{', a.ncol, '}') AS reg
)
SELECT chr[1], chr[2], chr[3], chr[4], chr[5],
chr[6], chr[7], chr[8], chr[9], chr[10]
FROM c;
WITH句のブロックbまでは前項と同じ。ブロックcのregexp_split_to_array関数で、1文字ずつ配列の1要素にしています(空文字をデリミタに指定)。最後に、配列の要素一つずつを1列に変換。ここが、出力する列数を動的に指定できないSQLの面倒な点ですが、とりあえず簡単な文字パレットの出来上がり。
この出力ペインは、セル一つ・行全体・列全体・ブロックのいずれでも選択とコピーでき、他のアプリに簡単に持っていけます。また(少なくともWindowsでは)Ctrl+マウスホイールで文字の拡大縮小が可能。なおコピー時は列間に区切り文字が入るので、それを避けたい時は前項の、列を分けないクエリの方が便利。
いろんな文字パレット例(罫線、装飾記号、数学記号、ギリシャ文字、他)
前項のクエリから、開始文字を変えるだけで様々な文字種のパレットができます。以下、その例。コードは、変更したWITH句のaブロック内だけ示しています。
SELECT 10, 10, to_hex(ascii('①'))
-- Unicodeカテゴリ「囲み英数字」の先頭。最初が丸数字、続いてカッコ付数字。
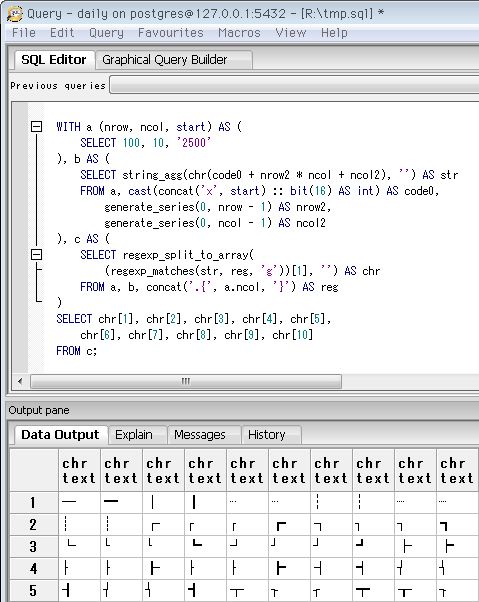
SELECT 10, 10, '2500'
-- 罫線は「コードポイント2500」で始まり、覚えやすいかも
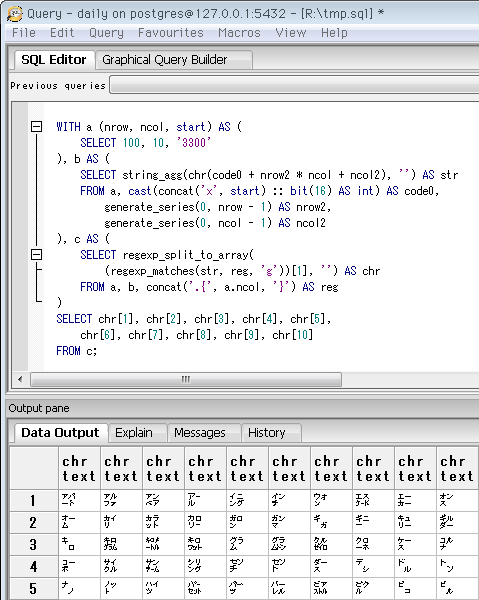
SELECT 10, 10, '3300'
-- 「キロ」「トン」など、小さい字の単位は「コードポイント3300」から。
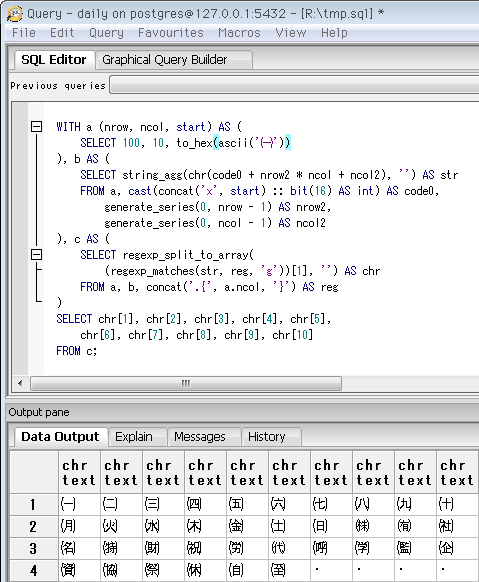
SELECT 10, 10, to_hex(ascii('㈠'))
-- Unicodeカテゴリでいう「記号」の先頭。
-- 記号というより略号という感じ。あまり記号ぽくない
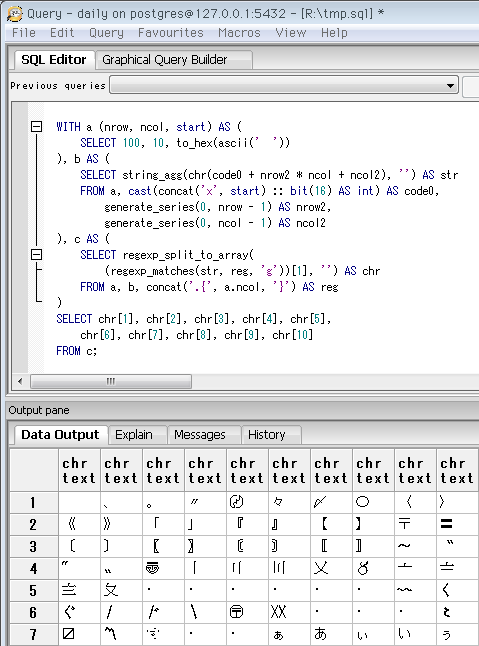
SELECT 10, 10, to_hex(ascii(' '))
-- Unicodeカテゴリ「CJK用の記号および分音記号」の先頭
-- 全角の、文章中によく使う記号。先頭はたぶん全角スペース
SELECT 10, 10, to_hex(ascii('☀'))
-- Unicodeカテゴリ「記号および装飾記号」の先頭。
-- こちらは割とマーク、ワンポイント的なもの。
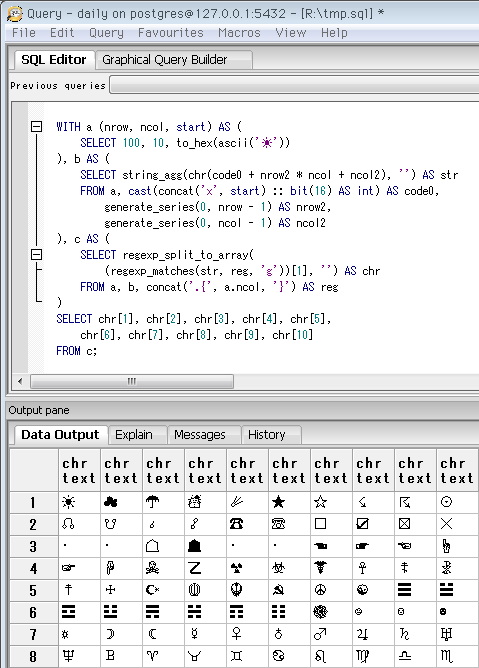
SELECT 10, 10, to_hex(ascii('▀'))
-- Unicodeカテゴリ「ブロック要素および幾何学模様」の先頭。
-- 四角形や黒丸などは、ここ。
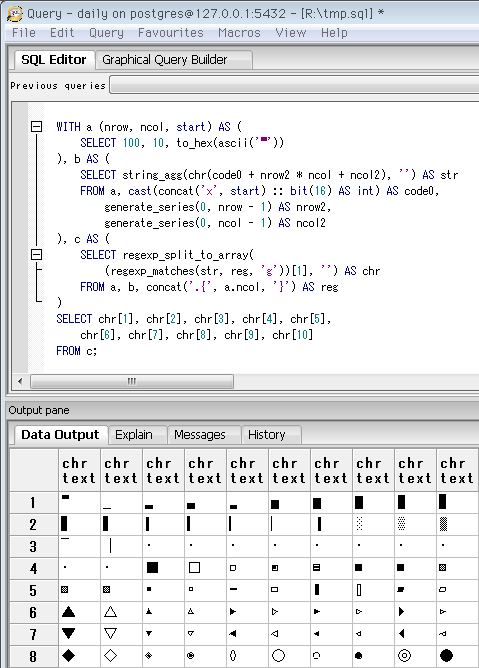
SELECT 10, 10, to_hex(ascii('℀'))
-- Unicodeカテゴリ「文字種記号」の先頭。
-- ℃やÅ(オングストローム)など、単位はここらしい
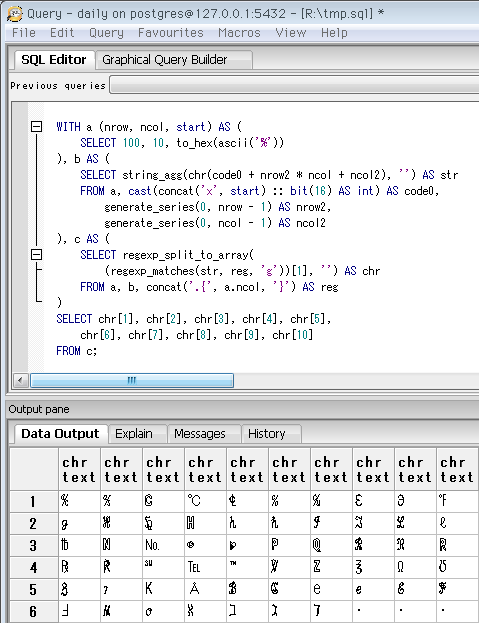
SELECT 10, 10, to_hex(ascii('∀'))
-- Unicodeカテゴリ「数学記号」のうち、+ < = > ± × ÷ 以外の先頭。
-- 上の七つのコードポイントは、これより前方の離れた所にある
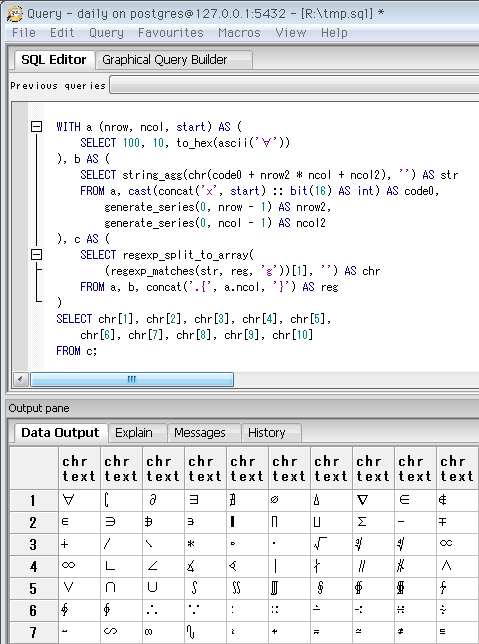
SELECT 10, 10, to_hex(ascii('⌂'))
-- Unicodeカテゴリ「その他の技術用記号」の先頭。
-- 対応しているフォントはまだ少ない
-- MSゴシックにもほとんどの字形がないが、Macの⌘はある
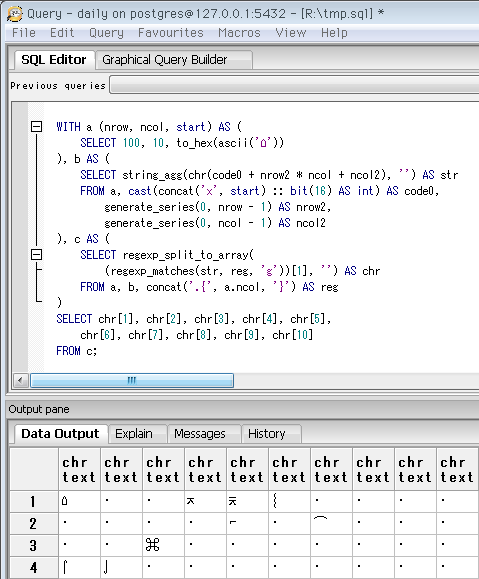
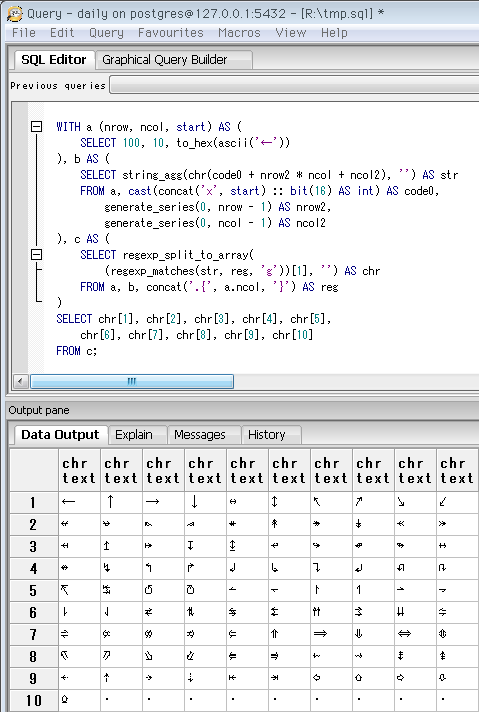
SELECT 10, 10, to_hex(ascii('←'))
-- Unicodeカテゴリ「矢印」の先頭。記号とは別扱いになってた
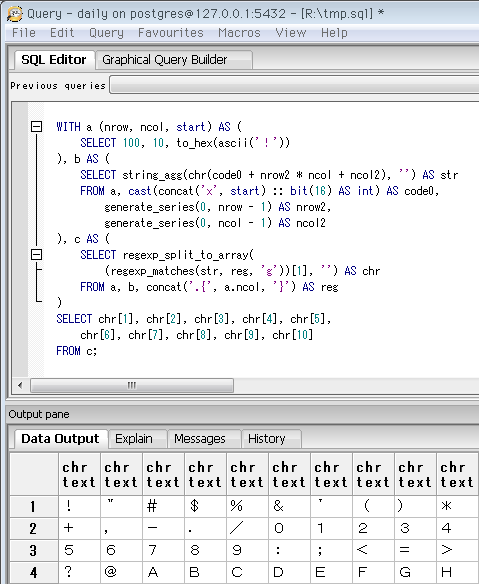
SELECT 10, 10, to_hex(ascii('!'))
-- Unicodeカテゴリ「全角形」の先頭。
-- ここにも「全角記号」と言えるような字が入ってる
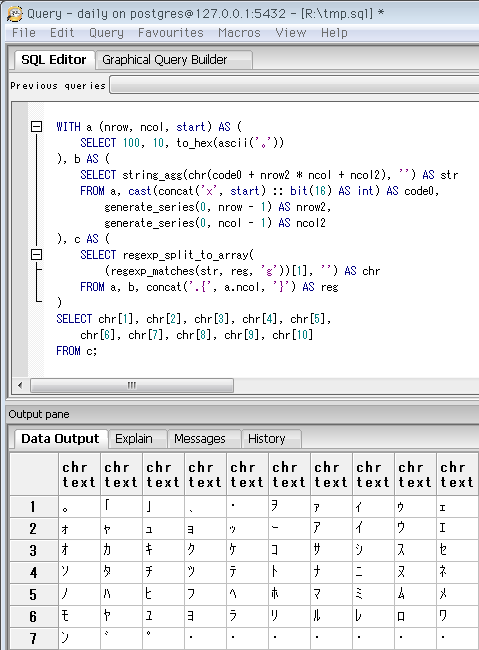
SELECT 10, 10, to_hex(ascii('。'))
-- Unicodeカテゴリ「半角形」の先頭。
-- いわゆる半角カナはここ。
SELECT 10, 10, '0' || to_hex(ascii('ʹ'))
-- Unicodeカテゴリ「ギリシャ語」の先頭。
-- 16進コードポイントが3桁なのでゼロ埋めする
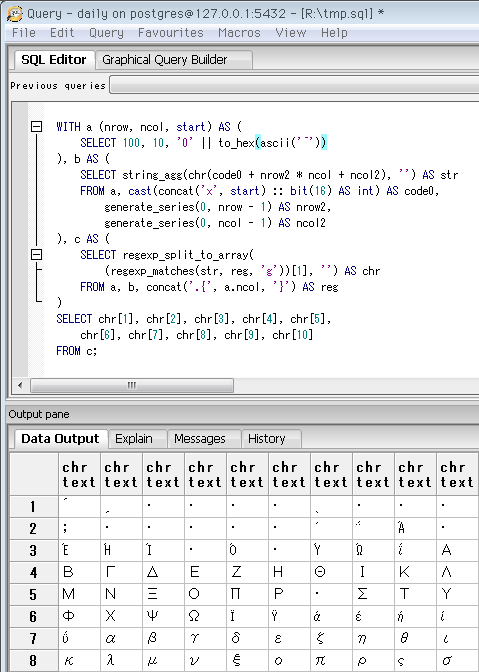
SELECT 10, 10, '0' || to_hex(ascii('Ё'))
-- Unicodeカテゴリ「キリル言語」の先頭。ロシア語の文字。
-- 16進コードポイントが3桁なのでゼロ埋めする

SELECT 10, 10, to_hex(ascii('⁰'))
-- Unicodeカテゴリ「上付き/下付きの文字」の先頭。
-- 上付きの 1, 2, 3 だけ、コードポイントが離れている
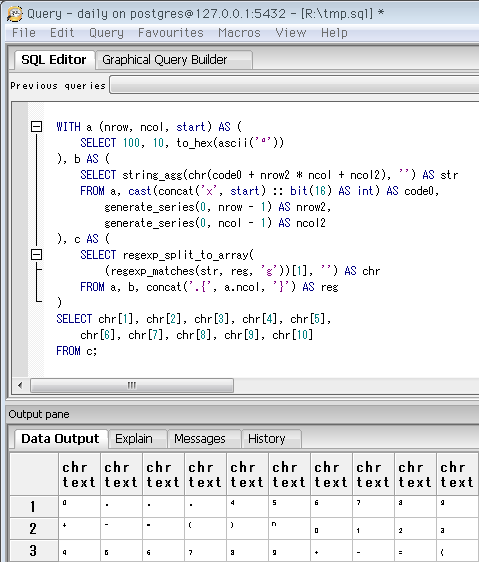
SELECT 10, 10, '00' || to_hex(ascii(' '))
-- 最初から表示する場合、半角スペースから。
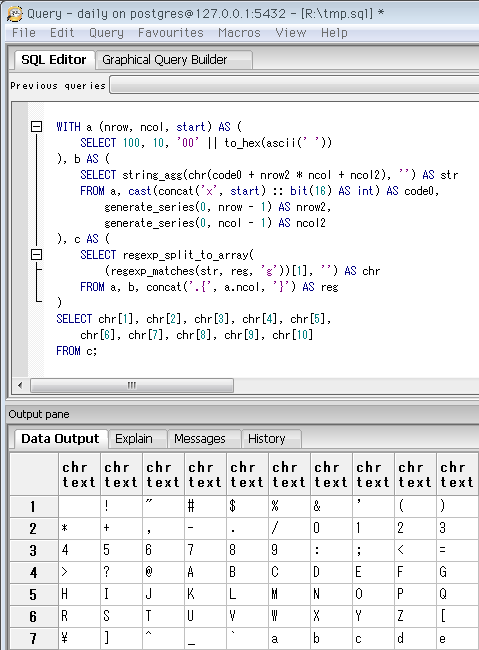
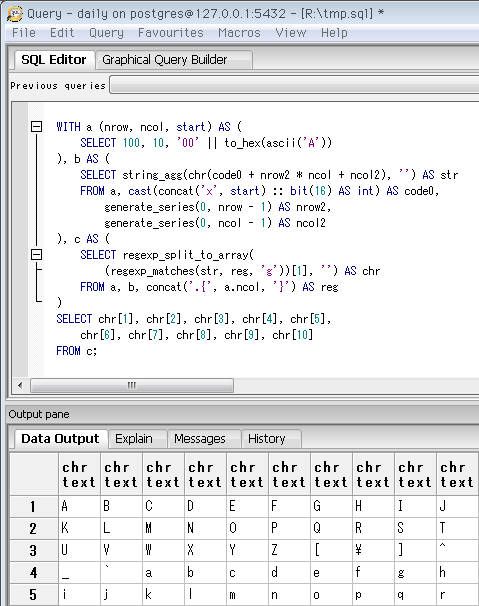
SELECT 10, 10, '00' || to_hex(ascii('A'))
-- Unicodeカテゴリ「ラテン」の先頭。いわゆるアルファベット。
SELECT 10, 10, to_hex(ascii('一'))
-- Unicodeカテゴリ「CJK漢字」の先頭
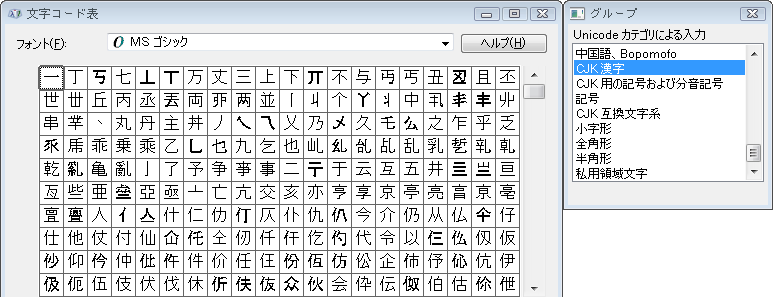
 上のクエリ結果では「万」の前に「丆」という字がある一方、Windowsの文字コード表で「CJK漢字」を表示すると ↓「丆」がありません。MSゴシックに字体がないので飛ばしたようです。pgAdminの方も表示フォントはMSゴシックに設定していますが、別のフォントから自動的に字を持ってくるのか、それともWindowsのフォントリンクが機能しているのか、今のところ不明。
上のクエリ結果では「万」の前に「丆」という字がある一方、Windowsの文字コード表で「CJK漢字」を表示すると ↓「丆」がありません。MSゴシックに字体がないので飛ばしたようです。pgAdminの方も表示フォントはMSゴシックに設定していますが、別のフォントから自動的に字を持ってくるのか、それともWindowsのフォントリンクが機能しているのか、今のところ不明。
参考、今後
Unicode全般とコードポイントについて、下記が参考になりました。とくに、後半にある項目「コードポイントが紛らわしい」の説明が分かりやすいです。
» 文字コードの考え方から理解するUnicodeとUTF-8の違い
JavaScriptでも、今回と同様に文字とコードポイントを相互変換できそうなので(関数fromCharCode, charCodeAtというのがあるらしい)HTMLで簡単な文字パレットを作りたい。そうすればPostgreSQLやpgAdminを起動していなくても、記号や罫線を簡単に使えるので。出来上がったら記事にします。