Contents
9 月 1 日の記事との違い、実行環境、参考サイト 複合型(以上、昨日) - 配列
JSON(明日) 補足(状態遷移関数の NULL 判定を不要にする)、まとめ(明日)
配列
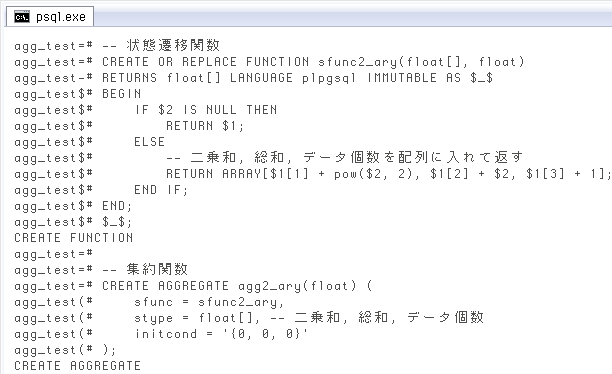
昨日と同じ結果を出す集約関数を、今日は遷移状態に配列を使って作ると ↓ こんな感じ。複合型は事前に型の定義が必要でしたが、それと違い二つの関数だけ作れば済みます。でもデータの取り出しを全て添字で行うため、各要素の内容をコメント等で残しておかないと後で意味不明になりそう。また各要素のデータ型は同じでないといけないので(それが
-- 状態遷移関数
CREATE OR REPLACE FUNCTION sfunc2_ary(float[], float)
RETURNS float[] LANGUAGE plpgsql IMMUTABLE AS $_$
BEGIN
IF $2 IS NULL THEN
RETURN $1;
ELSE
-- 二乗和, 総和, データ個数を配列に入れて返す
RETURN ARRAY[$1[1] + pow($2, 2), $1[2] + $2, $1[3] + 1];
END IF;
END;
$_$;
-- 集約関数
CREATE AGGREGATE agg2_ary(float) (
sfunc = sfunc2_ary,
stype = float[], -- 二乗和, 総和, データ個数
initcond = '{0, 0, 0}'
);
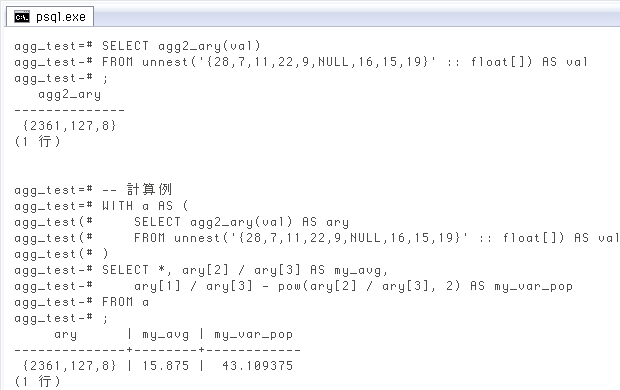
↓ 使用例。数値は昨日と同様、「統計計算の方法:個別データの分散、標準偏差など」(明星大学 船津好明先生)から拝借し、途中に
-- 使用例
SELECT agg2_ary(val)
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val;
agg2_ary
--------------
{2361,127,8}
(1 行)
-- 計算例(相加平均と母分散)
WITH a AS (
SELECT agg2_ary(val) AS ary
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val
)
SELECT *, ary[2] / ary[3] AS my_avg,
ary[1] / ary[3] - pow(ary[2] / ary[3], 2) AS my_var_pop
FROM a;
ary | my_avg | my_var_pop
--------------+--------+------------
{2361,127,8} | 15.875 | 43.109375
(1 行)
昨日の複合型を使った場合は ↓ こんな感じ。列名があると計算内容が格段に分かりやすくなります。
WITH a AS (
SELECT (agg2_rec(val)).*
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val
)
SELECT *, sum / cnt AS my_avg,
sum2 / cnt - pow(sum / cnt, 2) AS my_var_pop
FROM a;
sum2 | sum | cnt | my_avg | my_var_pop
------+-----+-----+--------+------------
2361 | 127 | 8 | 15.875 | 43.109375
(1 行)
というわけで、配列を状態遷移関数に一応使えるものの、要素数が増えると厳しい。また最終出力も配列にした場合、その後の使い勝手が非常に悪いです。複合型に対する唯一のメリットは、事前の型の定義が不要ということくらい。
ただ、今回初めて試した方法なので、もしかしたら有益な場面があるかも。その際は追記します。明日は三つ目の方法で