Contents
9 月 1 日の記事との違い、実行環境、参考サイト 複合型(以上、一昨日) 配列(昨日) - JSON
- 補足(状態遷移関数の
NULL 判定を不要にする)、まとめ
JSON
一昨日、昨日と同じ結果を出す集約関数を、今日は遷移状態にまた昨日までは、集計対象レコードの中に
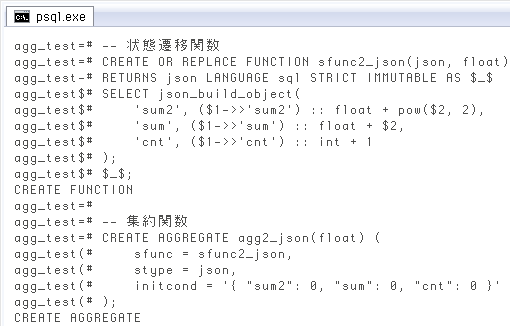
-- 状態遷移関数
CREATE OR REPLACE FUNCTION sfunc2_json(json, float)
RETURNS json LANGUAGE sql STRICT IMMUTABLE AS $_$
SELECT json_build_object(
'sum2', ($1->>'sum2') :: float + pow($2, 2),
'sum', ($1->>'sum') :: float + $2,
'cnt', ($1->>'cnt') :: int + 1
);
$_$;
-- 集約関数
CREATE AGGREGATE agg2_json(float) (
sfunc = sfunc2_json,
stype = json,
initcond = '{ "sum2": 0, "sum": 0, "cnt": 0 }'
);
以下、使用例。数値は昨日と同様、「統計計算の方法:個別データの分散、標準偏差など」(明星大学 船津好明先生)から拝借し、途中に
-- 使用例
SELECT agg2_json(val)
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val;
agg2_json
-----------------------------------------
{"sum2" : 2361, "sum" : 127, "cnt" : 8}
(1 行)
-- 使用例(JSONをヨコに展開)
WITH a AS (
SELECT agg2_json(val) json
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val
)
SELECT sum2, sum, cnt
FROM a, json_to_record(json) AS x(sum2 float, sum float, cnt int);
sum2 | sum | cnt
------+-----+-----
2361 | 127 | 8
(1 行)
-- 使用例(JSONを縦に展開)
SELECT json_each(agg2_json(val))
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val;
json_each
-------------
(sum2,2361)
(sum,127)
(cnt,8)
(3 行)
-- 使用例(JSONを縦に展開 & 列にばらす)
SELECT (json_each(agg2_json(val))).*
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val;
key | value
------+-------
sum2 | 2361
sum | 127
cnt | 8
(3 行)

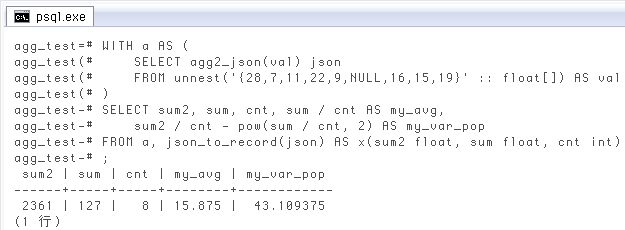
↓ 一昨日、昨日と同じ計算例。json_to_record
WITH a AS (
SELECT agg2_json(val) json
FROM unnest('{28,7,11,22,9,NULL,16,15,19}' :: float[]) AS val
)
SELECT sum2, sum, cnt, sum / cnt AS my_avg,
sum2 / cnt - pow(sum / cnt, 2) AS my_var_pop
FROM a, json_to_record(json) AS x(sum2 float, sum float, cnt int);
補足(状態遷移関数の
先ほど書いた状態遷移関数に-- 複合型での状態遷移関数(ビフォー)
CREATE OR REPLACE FUNCTION sfunc2_rec(sum2_sum_cnt, float)
RETURNS sum2_sum_cnt LANGUAGE plpgsql IMMUTABLE AS $_$
BEGIN
IF $2 IS NULL THEN
RETURN $1;
ELSE
RETURN ($1.sum2 + pow($2, 2), $1.sum + $2, $1.cnt + 1);
END IF;
END;
$_$;
-- 複合型での状態遷移関数(アフター)
CREATE OR REPLACE FUNCTION sfunc2_rec(sum2_sum_cnt, float)
RETURNS sum2_sum_cnt LANGUAGE plpgsql STRICT IMMUTABLE AS $_$
BEGIN
RETURN ($1.sum2 + pow($2, 2), $1.sum + $2, $1.cnt + 1);
END;
$_$;
-- 配列での状態遷移関数(ビフォー)
CREATE OR REPLACE FUNCTION sfunc2_ary(float[], float)
RETURNS float[] LANGUAGE plpgsql IMMUTABLE AS $_$
BEGIN
IF $2 IS NULL THEN
RETURN $1;
ELSE
RETURN ARRAY[$1[1] + pow($2, 2), $1[2] + $2, $1[3] + 1];
END IF;
END;
$_$;
-- 配列での状態遷移関数(アフター)
CREATE OR REPLACE FUNCTION sfunc2_ary(float[], float)
RETURNS float[] LANGUAGE sql STRICT IMMUTABLE AS $_$
SELECT ARRAY[$1[1] + pow($2, 2), $1[2] + $2, $1[3] + 1];
$_$;
以上、簡単な例ですが三つの型で複数の値を遷移させる集約関数を作ってみました。印象として、正攻法なら複合型。でも型の定義が面倒だったり既存のユーザ定義型と混乱しかねない場合は、JSON
JSON