↓ こんなの。「符号化方式"UTF8"における0xe3 0x82 0x94バイトシーケンスを持つ文字は"SJIS"符号化方式では等しくありません」とか意味不明のメッセージが出て困った (>_<)昔の経験から、対策をメモしておきます。使ったpsqlはWindows版の9.5.0(以前のバージョンでも同様)。似たエラー「符号化方式"SJIS"における~」や「符号化方式"UTF8"で無効なバイトシーケンスです」は主にCOPYコマンドで起きやすく、後半で書きました。
クエリ時に起きる時の原因、対策(Windowsコマンドプロンプト以外)
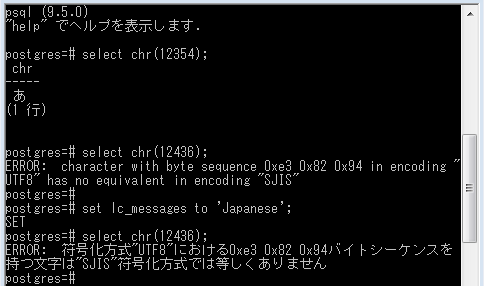
データベースの文字コードがUTF-8で、クエリ結果が「UTF-8固有の文字」(正確にはユニコード固有の文字。以下同じ)を含み、かつクエリを受け取る側(クライアント、ここではpsql)がUTF-8以外で受け取ろうとする場合に起きます。原因は単純で、PostgreSQLサーバがクエリ結果を送信する際、親切にクライアント側の文字コードに変換しようとする。だけどUTF-8固有の文字があるので上手く変換できない、そんな感じです。
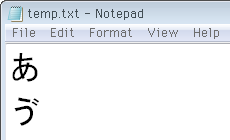
例えば上の画像では、最初に「あ」という文字をユニコードコードポイント(10進数で12354)でクエリしてます。これはUTF-8固有の字でないからOK。一方「う+濁点」をクエリすると(同じく12436)UTF-8にしかない文字で、psql側のShift JISには対応する字がなくてエラーになります。
このように事前に「クエリ結果にUTF-8固有の文字がある」のが分かってればいいけど、知らずにデータベースの一部にUTF-8固有の字が入っていると困ります。例えば地名とか固有名詞とか。ずっと普通に使えていたのに、ある日突然、クエリしたら意味不明のエラーが出て泣きたくなるかも。
とは言え、Windowsのコマンドプロンプト以外なら文字コードをUTF-8にすれば済みます。コンソールをUTF-8にしたのに直らない場合、psqlで ↓ クライアントエンコーディングを確認・変更してみて下さい。
(psqlメタコマンド)
\encoding -- 現在のクライアントエンコーディングを確認
\encoding utf8 -- 変更
WindowsでもpgAdminのクエリツールなら、デフォルトでUTF-8で接続するので普通は問題ないはず。もし遭遇したら ↓ 画像の下のコマンドのようにSQLでクライアントエンコーディングを確認・変更してみて下さい。
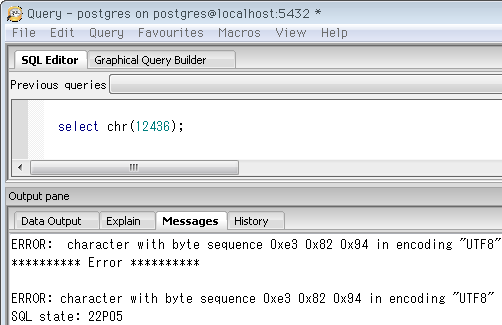
(SQLコマンド)
select current_setting('client_encoding'); -- 現在のクライアントエンコーディングを確認
set client_encoding to 'utf8'; -- 変更
対策(Windowsコマンドプロンプトの場合)
問題はこれ…。以前いろいろ試した結果、コマンドプロンプト上のpsqlでUTF-8を使うのは無理そうです。コードページ65001が一応UTF-8のコマンドプロンプトを意味するらしいけど、ページャのmore.comがエラーを起こすし、ページャを使わなくともサーバから返るUTF-8文字列がまともに表示されません。諦めて「エラーが出たクエリだけpgAdminを使う」のが一番の近道。
★ 追記 : ページャにWindows版lessを使うことで、一応UTF-8のクエリ結果を表示できました( → 6月24日)。対策としては不十分ですが参考まで。追記終わり ★
なおConEmuでコマンドプロンプトを使っても解決しません(変わるのは外観や操作性だけ)。最新のWindows10では確認してませんが、下の記事とか、Win10のコマンドプロンプトに関するはてなブックマークでのコメントを読む限り変わってなさそうです。
Windows 10のコマンドプロンプトでも、利用できる文字コードはANSI(英語モード)かShift-JIS(日本語モード)のみ。UTF-8などは特にサポートされていない。
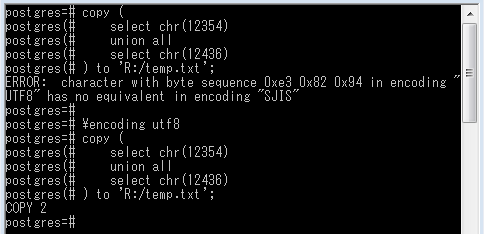
pgAdminも使えない最悪の場合は、クライアントエンコーディングをUTF-8にすればCOPYコマンドで結果をファイルに出力できるので ↓ それを開いて見るとか。ただし出力先はフルパスで指定し、かつPostgreSQLサーバを起動したユーザが書き込める場所でないといけないけど。出力ファイルは当然UTF-8になります。
-- クライアントエンコーディングがUTF-8でないと失敗
copy (
select chr(12354)
union all
select chr(12436)
) to 'R:/temp.txt';
ERROR: character with byte sequence 0xe3 0x82 0x94 in encoding "
UTF8" has no equivalent in encoding "SJIS"
-- クライアントエンコーディングをUTF-8にして成功
\encoding utf8
copy (
select chr(12354)
union all
select chr(12436)
) to 'R:/temp.txt';
COPY 2
COPYコマンドでのデータインポート時に起きる場合
クエリの時は「UTF-8固有の文字」がなければ無問題でしたが、COPYコマンドでは事情が違います。エラーメッセージが似てるので分かりにくい。原因はたいていインポート元ファイルの文字コードを指定しないことで、デフォルトまたは暗黙に前提される文字コードとくい違うため。UTF-8固有の文字がなくても起きます。
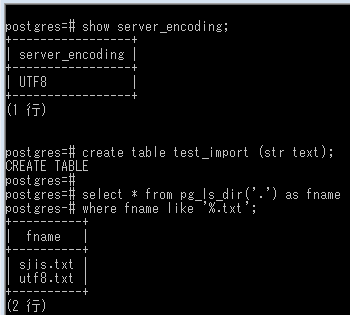
エラーの様子を簡単に再現するため ↓ こんな感じで準備。文字コードUTF-8のデータベース上に空のテーブル(文字型の列一つ)を作り、データフォルダにShift JISとUTF-8のテキストファイルを置きました。二つのテキストとも「あいうえお」一行だけの短いもの。
show server_encoding;
+-----------------+
| server_encoding |
+-----------------+
| UTF8 |
+-----------------+
(1 行)
create table test_import (str text);
select * from pg_ls_dir('.') as fname
where fname like '%.txt';
+----------+
| fname |
+----------+
| sjis.txt |
| utf8.txt |
+----------+
(2 行)
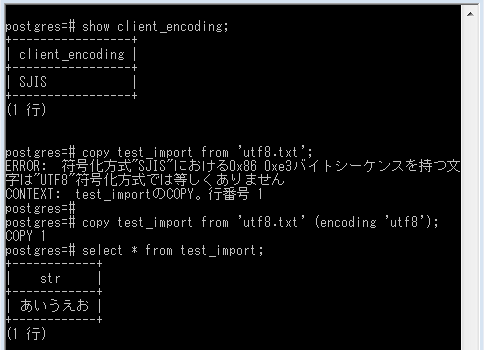
 ↓ クライアントエンコーディングがShift JISの状態で、COPYコマンドでUTF-8のファイルを文字コード指定なしでインポートすると、先ほどと似たエラー「符号化方式"SJIS"における0x86 0xe3バイトシーケンスを持つ文字は"UTF8"符号化方式では等しくありません」。COPYコマンドはファイルの文字コード指定がないと、クライアントエンコーディングと等しいと仮定するようです。で実際のファイルと矛盾してエラーになる。こちらの対策はコマンドプロンプトでも簡単で、(encoding 'utf8')とコマンドに明記すればOK。
↓ クライアントエンコーディングがShift JISの状態で、COPYコマンドでUTF-8のファイルを文字コード指定なしでインポートすると、先ほどと似たエラー「符号化方式"SJIS"における0x86 0xe3バイトシーケンスを持つ文字は"UTF8"符号化方式では等しくありません」。COPYコマンドはファイルの文字コード指定がないと、クライアントエンコーディングと等しいと仮定するようです。で実際のファイルと矛盾してエラーになる。こちらの対策はコマンドプロンプトでも簡単で、(encoding 'utf8')とコマンドに明記すればOK。
show client_encoding;
+-----------------+
| client_encoding |
+-----------------+
| SJIS |
+-----------------+
(1 行)
copy test_import from 'utf8.txt';
ERROR: 符号化方式"SJIS"における0x86 0xe3バイトシーケンスを持つ文
字は"UTF8"符号化方式では等しくありません
CONTEXT: test_importのCOPY。行番号 1
copy test_import from 'utf8.txt' (encoding 'utf8');
-- ファイルの文字コードを指定すればOK
select * from test_import;
+------------+
| str |
+------------+
| あいうえお |
+------------+
(1 行)
似たエラー「符号化方式"UTF8"で無効なバイトシーケンスです」が出る場合
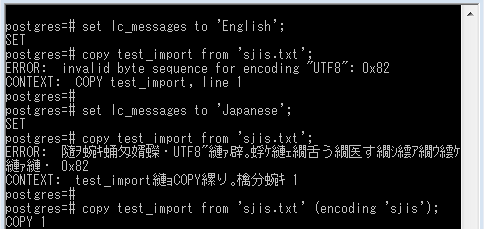
こちらは「ファイルがUTF-8以外、クライアントがUTF-8」と逆にして、COPYコマンドで文字コード指定を省いた場合です。例えばWindows以外のコンソールで、Excelから出力したCSVとかをインポートする際に起きがち。今回の再現 ↓ はコマンドプロンプト上なので日本語メッセージが文字化けしますが、英語のinvalid byte sequence for encoding "UTF8"のとおり。対策は前項と同様、COPYコマンドでファイルの文字コードを指定するだけ。
\encoding utf8
show client_encoding;
+-----------------+
| client_encoding |
+-----------------+
| UTF8 |
+-----------------+
(1 行)
set lc_messages to 'English';
copy test_import from 'sjis.txt';
ERROR: invalid byte sequence for encoding "UTF8": 0x82
CONTEXT: COPY test_import, line 1
set lc_messages to 'Japanese';
copy test_import from 'sjis.txt';
ERROR: 隨ヲ蜿キ蛹匁婿蠑・UTF8"縺ァ辟。蜉ケ縺ェ繝舌う繝医す繝シ繧ア繝ウ繧ケ
縺ァ縺・ 0x82
CONTEXT: test_import縺ョCOPY縲り。檎分蜿キ 1
copy test_import from 'sjis.txt' (encoding 'sjis');
-- ファイルの文字コードを指定すればOK
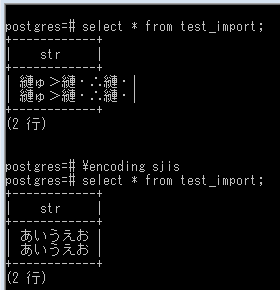
 ↓ 最後に、COPYコマンドで投入できた中身を確認。最初はクライアントエンコーディングがUTF-8の状態で、サーバから正常にUTF-8のデータが返りますがコマンドプロンプトのコードページがShift JISなので文字化けした様子。次にクライアントエンコーディングをShift JISに戻し、正常に表示できました。
↓ 最後に、COPYコマンドで投入できた中身を確認。最初はクライアントエンコーディングがUTF-8の状態で、サーバから正常にUTF-8のデータが返りますがコマンドプロンプトのコードページがShift JISなので文字化けした様子。次にクライアントエンコーディングをShift JISに戻し、正常に表示できました。
select * from test_import;
+------------+
| str |
+------------+
| 縺ゅ>縺・∴縺・|
| 縺ゅ>縺・∴縺・|
+------------+
(2 行)
\encoding sjis
select * from test_import;
+------------+
| str |
+------------+
| あいうえお |
| あいうえお |
+------------+
(2 行)