あるCSVをPostgreSQLで処理しようとしたら ↓ こんな風にデータ内にもカンマがあり、その列だけ二重引用符で囲まれてました。COPYコマンドで問題なくインポートできましたが、インポートでなく各行を配列にする等の場合、「列区切りとしてのカンマだけ」を取り出すのが面倒そう。備えとして方法を検討した結果、正規表現関数の肯定先読み/否定先読みが使えました。(下画像の説明とクエリはこちら)
Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"
ドキュメントの正規表現の箇所、関連リンク、実行環境
PostgreSQLにはregexp_matchesなど正規表現で検索・置換を行う関数があり、ドキュメントの文字列関数の項(上記リンク一つ目)で、他の関数と一緒にリスト化されてます。また使える正規表現や実例はパターンマッチの項(同二つ目)でLIKE演算子等の次にあり。肯定先読み/否定先読みは、先頭/末端一致という基本的な要素(^と$)と一緒にさらっと、「先行肯定検索」「先行否定検索」という用語で載っているだけなので、正直分かりにくいです。
分かりやすい説明は、例えば上に挙げた正規表現マスターを見て下さい。ここでは肯定/否定後読みという正規表現もありますが、現在のPostgreSQL(9.5まで)には実装されていません。一方、サードパーティによる拡張としてpgpcreというものがあり、Perl互換なので後読みも使えそうな気が。今回はWindows用のコンパイル済みライブラリがなかったのでスルーしました。
実行環境はWindows 7 64 bit + PostgreSQL 9.5.0ですが、正規表現の実装はかなり前から同じだと思います。
肯定先読みで、CSV中の「列区切りでないカンマ」を検索
今回、見やすさのためサンプル文字列の各カンマの後に半角空白を一つ付けており、以下ではそれを含めて「カンマ」と書き、処理対象にします。また二重引用符は「一部の列を囲む」だけに使われ、データ内には無い前提。
本来の目的は「列区切りのカンマだけ」を正確に取り出すことですが、「列区切りでない」方が二重引用符に囲まれたデータ内にあるので、むしろ捕捉しやすそう。そっちを先にカンマ以外(例えばBRタグ)に置換すれば、残るカンマ全部=列区切り全部なので簡単に処理できます。
まず準備体操。冒頭のサンプル文字列を対象として、すべてのカンマを正規表現関数regexp_replaceで適当な文字(ここでは改行)に置換するクエリ、および結果は ↓ のとおり。
-- すべてのカンマを改行に置換
select regexp_replace(
'Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"',
', ',
E'\n',
'g');
+----------------+
| regexp_replace |
+----------------+
| Database +|
| "postgres +|
| mysql +|
| sqlite" +|
| Programing +|
| "perl +|
| php +|
| python +|
| ruby" |
+----------------+
(1 row)
当然ながら「列区切りカンマ」と「データ内カンマ」が等しく置換されます。次に「データ内カンマ」だけBRタグに置換すべく、一般的な(先読み・後読みを使わない)正規表現だけで試した例。↓ データ両端にある二重引用符を手がかりに、何とかできそうな気もしますが、データ内に複数のカンマがあると上手くいきません。
-- データ内カンマだけ置換したいが、うまく行かない例
select regexp_replace(
'Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"',
'("[^"]*), ([^"]*")',
'\1<br>\2',
'g');
+--------------------------------------------------------------------------------+
| regexp_replace |
+--------------------------------------------------------------------------------+
| Database, "postgres, mysql<br>sqlite", Programing, "perl, php, python<br>ruby" |
+--------------------------------------------------------------------------------+
(1 row)
そこで「肯定先読み」を使い、後ろに「二重引用符以外の文字列+二重引用符+カンマ」が続くカンマを全て検索すれば ↓ データ内カンマが複数あっても捕捉できます。ただし最後の列だけまだ上手くいってません。なお「後方のパターンを指定する」のに「先読み」と言うのは、マッチ対象を「先に読む」から。
-- 肯定先読みの例、ただし最後の列だけ未処理
select regexp_replace(
'Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"',
', (?=[^"]*",)',
'<br>',
'g');
+--------------------------------------------------------------------------------+
| regexp_replace |
+--------------------------------------------------------------------------------+
| Database, "postgres<br>mysql<br>sqlite", Programing, "perl, php, python, ruby" |
+--------------------------------------------------------------------------------+
(1 row)
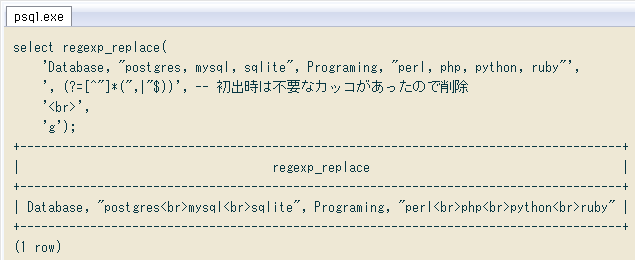
未処理で残った「最終列内のカンマ」は、後ろが「二重引用符以外の文字列+二重引用符+行末」となるものを全て捕捉すればOK。これを上の正規表現に加えた結果 ↓ 列区切りでないカンマを全て置換できました。
-- 肯定先読みで「列区切りでないカンマ」を全て置換する例
select regexp_replace(
'Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"',
', (?=[^"]*(",|"$))', -- 初出時は不要なカッコがあったので削除. 以下同様(1月21日)
'<br>',
'g');
+--------------------------------------------------------------------------------------+
| regexp_replace |
+--------------------------------------------------------------------------------------+
| Database, "postgres<br>mysql<br>sqlite", Programing, "perl<br>php<br>python<br>ruby" |
+--------------------------------------------------------------------------------------+
(1 row)
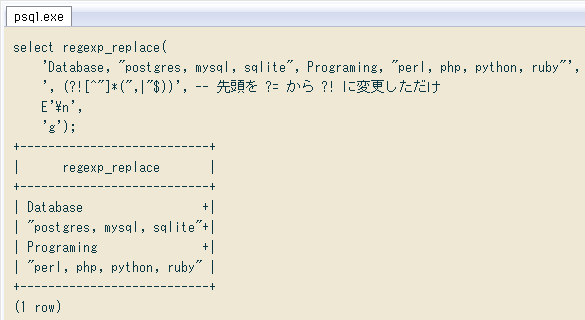
否定先読みで「列区切りカンマ」だけを検索
前項で「列区切りでないカンマ」を全て置換できたので、後は全てのカンマ=列区切り。もう正規表現は必要なく一括置換すれば済みますが、もし先に「列区切りカンマ」だけ検索or置換する場合、正規表現パターンの?=を?!に変えるだけで ↓ 済みます(肯定先読み → 否定先読み)。
select regexp_replace(
'Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"',
', (?![^"]*(",|"$))', -- 先頭を ?= から ?! に変更しただけ
E'\n',
'g');
+---------------------------+
| regexp_replace |
+---------------------------+
| Database +|
| "postgres, mysql, sqlite"+|
| Programing +|
| "perl, php, python, ruby" |
+---------------------------+
(1 row)
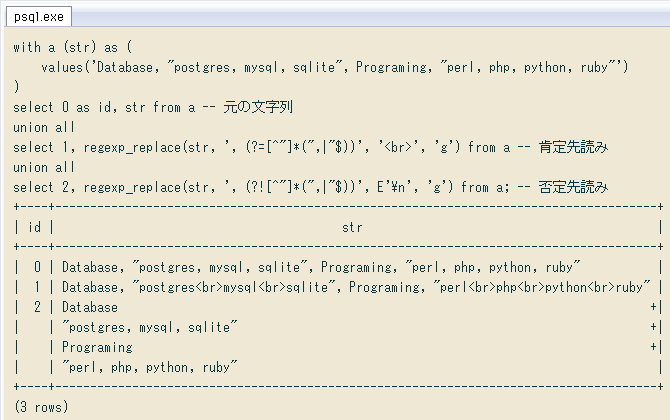
 ↓ 全体をまとめたクエリ。WITH句で対象文字列を書き、「元の文字列」「データ内のカンマを置換」「列区切りのカンマを置換」の結果を縦に積んで出力しています。
↓ 全体をまとめたクエリ。WITH句で対象文字列を書き、「元の文字列」「データ内のカンマを置換」「列区切りのカンマを置換」の結果を縦に積んで出力しています。
with a (str) as (
values('Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby"')
)
select 0 as id, str from a -- 元の文字列
union all
select 1, regexp_replace(str, ', (?=[^"]*(",|"$))', '<br>', 'g') from a -- 肯定先読み
union all
select 2, regexp_replace(str, ', (?![^"]*(",|"$))', E'\n', 'g') from a; -- 否定先読み
+----+--------------------------------------------------------------------------------------+
| id | str |
+----+--------------------------------------------------------------------------------------+
| 0 | Database, "postgres, mysql, sqlite", Programing, "perl, php, python, ruby" |
| 1 | Database, "postgres<br>mysql<br>sqlite", Programing, "perl<br>php<br>python<br>ruby" |
| 2 | Database +|
| | "postgres, mysql, sqlite" +|
| | Programing +|
| | "perl, php, python, ruby" |
+----+--------------------------------------------------------------------------------------+
(3 rows)
↓ 確認のため、最後だけでなく最初の列もカンマを含む場合。同じ正規表現で対応できてます。
with a (str) as (
values('"postgres, mysql, sqlite", Database, Programing, "perl, php, python, ruby"')
)
select 0 as id, str from a -- 元の文字列
union all
select 1, regexp_replace(str, ', (?=[^"]*(",|"$))', '<br>', 'g') from a
union all
select 2, regexp_replace(str, ', (?![^"]*(",|"$))', E'\n', 'g') from a;
+----+--------------------------------------------------------------------------------------+
| id | str |
+----+--------------------------------------------------------------------------------------+
| 0 | "postgres, mysql, sqlite", Database, Programing, "perl, php, python, ruby" |
| 1 | "postgres<br>mysql<br>sqlite", Database, Programing, "perl<br>php<br>python<br>ruby" |
| 2 | "postgres, mysql, sqlite" +|
| | Database +|
| | Programing +|
| | "perl, php, python, ruby" |
+----+--------------------------------------------------------------------------------------+
(3 rows)
 「先読み」「後読み」と何回も書いてると、TUKUYOMIのOPが脳内で再生されて離れない…。
「先読み」「後読み」と何回も書いてると、TUKUYOMIのOPが脳内で再生されて離れない…。