列数が多いといっても20未満。データ中にカンマがあるといっても、当該の列は二重引用符で囲まれてて判別可能。要するに無茶苦茶に扱いづらいとは言えず「普通」にインポートしてもいいけど、場面によっては工夫が必要かもしれないので、いくつか方法を比べてみました。
実行環境
- Windows 7 64bit + PostgreSQL 9.5.0
- コマンドプロンプトの代わりにConEmu 151208 + psql
どんなCSVか(配布元と中身)
QGISというオープンソースGISソフトウェアのチュートリアル用データの一部です。チュートリアルはカリフォルニア大学バークレー校ジャーナリズム大学院の組織Advanced Media Instituteがウェブで公開しているもの。
地理学や生態学でなくジャーナリズムの研究教育でもオープンソースGISが使われているという、日本とかなり違う状況。チュートリアル前半、Import a shape fileの文章中にサンプルデータqgis-tutorial-files.zipへのリンクがあり、zipをダウンロード&展開すると、中のSHP-Library/dataにalameda-schools.csvが入ってます。これが今回のCSVで、内容は直接関係ありませんがカリフォルニア州のアラメダという地域の学校データ(経緯度つき)。
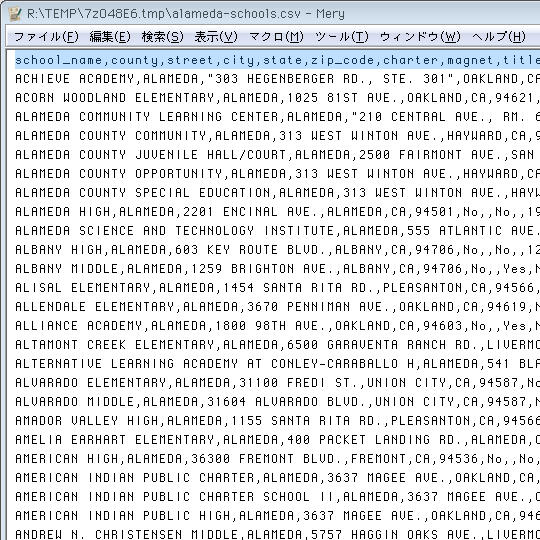
 QGISチュートリアルにおける、たぶん点データ読み込みのサンプルだと思います。自分は昨年のPostgreSQLカンファレンスでPostGISとMySQL用のサンプルデータを探す過程で知り、結局カンファレンスには未使用だったけどCSVの「微妙な取り込みにくさ」が気になってました。中身は ↓ こんな感じで17列×395行(+先頭に列名のヘッダ)。
QGISチュートリアルにおける、たぶん点データ読み込みのサンプルだと思います。自分は昨年のPostgreSQLカンファレンスでPostGISとMySQL用のサンプルデータを探す過程で知り、結局カンファレンスには未使用だったけどCSVの「微妙な取り込みにくさ」が気になってました。中身は ↓ こんな感じで17列×395行(+先頭に列名のヘッダ)。
 微妙に扱いにくいと思う理由は次の4点。
微妙に扱いにくいと思う理由は次の4点。
- 列数が多い → インポート先テーブルの各列を定義するのが面倒
- 列の一部(street)にカンマがあり、この列だけ二重引用符で囲まれている
- 空白を含む列、空の列もあるが、それは二重引用符で囲まれていない
- 行を一意に区別するIDなどの列がない
以下、PostgreSQLに取り込む方法をいくつか試します。準備としてPostgreSQLのデータフォルダ直下 ↓ にCSVをコピー。こうするとCOPYコマンドやファイルアクセス関数(pg_read_file等)からパスなしで呼び出せて便利です。
(1)普通にインポート先テーブルを定義しCOPYコマンドを使う
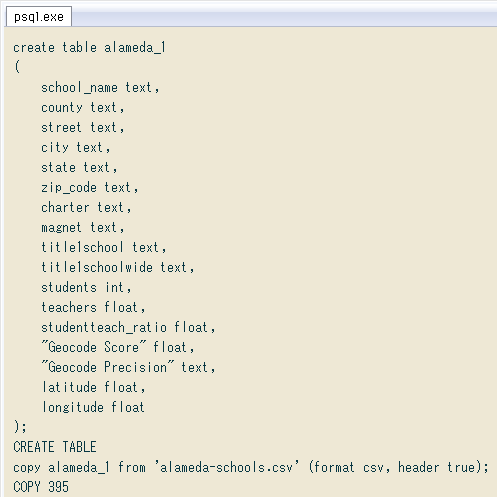
CSVの列名ヘッダをそのままテーブルの列名にし、データ型はCSVをざっと眺めて決めました。COPYコマンドでインポートすると ↓ 問題なく完了。先ほど挙げたように二重引用符の使い方が中途半端なCSVですが、PostgreSQLのCOPYコマンドは平気みたいです。
create table alameda_1
(
school_name text,
county text,
street text,
city text,
state text,
zip_code text,
charter text,
magnet text,
title1school text,
title1schoolwide text,
students int,
teachers float,
studentteach_ratio float,
"Geocode Score" float,
"Geocode Precision" text,
latitude float,
longitude float
);
copy alameda_1 from 'alameda-schools.csv' (format csv, header true);
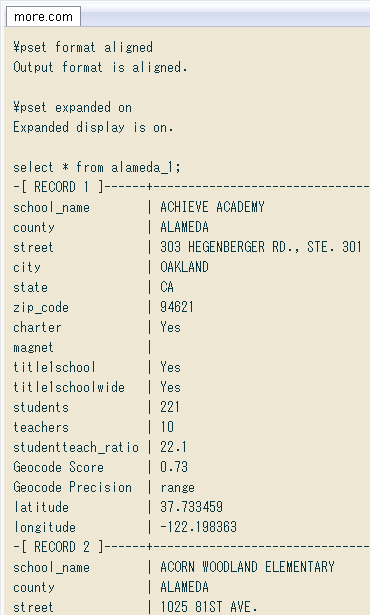
 ↓ 結果の確認。列が多いのでpsqlの縦に並べるExpanded displayが便利。空白やカンマをデータ中に含む列もきちんとインポートされてます。
↓ 結果の確認。列が多いのでpsqlの縦に並べるExpanded displayが便利。空白やカンマをデータ中に含む列もきちんとインポートされてます。
\pset format aligned
Output format is aligned.
\pset expanded on
Expanded display is on.
select * from alameda_1;
-[ RECORD 1 ]------+---------------------------------------------------
school_name | ACHIEVE ACADEMY
county | ALAMEDA
street | 303 HEGENBERGER RD., STE. 301
city | OAKLAND
state | CA
zip_code | 94621
charter | Yes
magnet |
title1school | Yes
title1schoolwide | Yes
students | 221
teachers | 10
studentteach_ratio | 22.1
Geocode Score | 0.73
Geocode Precision | range
latitude | 37.733459
longitude | -122.198363
-[ RECORD 2 ]------+---------------------------------------------------
school_name | ACORN WOODLAND ELEMENTARY
county | ALAMEDA
street | 1025 81ST AVE.
(...)
 取り込みはできたものの、先ほど書いたように「行を一意に区別するID」が元CSVにないので追加します。serial型の列を足して主キーにするだけで簡単。
取り込みはできたものの、先ほど書いたように「行を一意に区別するID」が元CSVにないので追加します。serial型の列を足して主キーにするだけで簡単。
alter table alameda_1 add column rowid serial;
alter table alameda_1 add primary key (rowid);
普通は最初のテーブル定義時にID列を作ると思いますが、今回のように列が多いとCOPYコマンドで「CSVの全ての列名」を列挙する ↓ 羽目になるので、後付けの方が楽。IDが最後の列というのは不格好だけど。
copy alameda_1 (school_name, county, street, ............... )
from 'alameda-schools.csv' (format csv, header true);
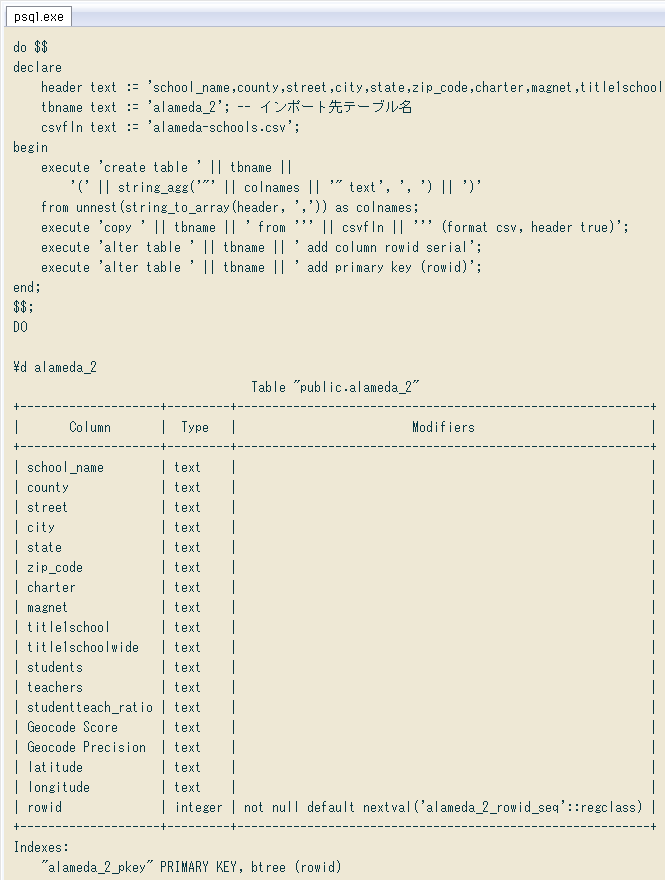
(2)CSVのヘッダ行から直にテーブル定義クエリを作る
今回は17列で済みましたが、手動でテーブル定義を打つのは何か非効率な感じ。大半の列はテキスト型なので、とりあえず全列テキストで簡易にテーブル定義し、後で型変換する手もあるかと。で、CSVのヘッダ列から直に「テーブル定義クエリを作るクエリ」↓ を考えてみました。
select 'create table alameda_2 (' || string_agg('"' || colnames || '" text', ', ') || ')'
from unnest(string_to_array('ここにCSVのヘッダ列をコピペ', ',')) as colnames;
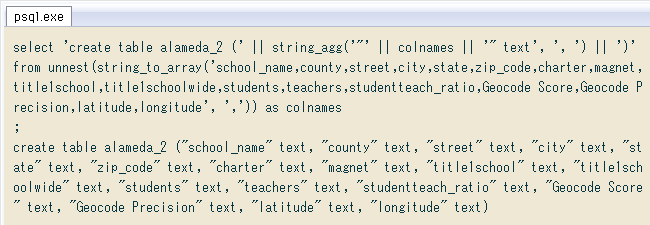
列名ヘッダのカンマは全て列区切りだったので、PostgreSQLのstring_to_array関数に渡せば「列名の配列」になります。それをunnest関数で一時的に行にバラし、各行の後に型(今回はテキスト)を付け、再びカンマ区切りで連結すれば「簡易な全列定義」。その前にcreate table テーブル名を挿入して完成です。↓ 実際にやってみた様子。
select 'create table alameda_2 (' || string_agg('"' || colnames || '" text', ', ') || ')'
from unnest(string_to_array('school_name,county,street,city,state,zip_code,charter,magnet,
title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode P
recision,latitude,longitude', ',')) as colnames;
create table alameda_2 ("school_name" text, "county" text, "street" text, "city" text, "st
ate" text, "zip_code" text, "charter" text, "magnet" text, "title1school" text, "title1sch
oolwide" text, "students" text, "teachers" text, "studentteach_ratio" text, "Geocode Score
" text, "Geocode Precision" text, "latitude" text, "longitude" text)
 後は、何らかの関数でこのクエリ文字列を動的に実行すればOK。続けてCOPYコマンドのインポートやID列の付加も可能です。例えばPL/pgSQLの無名コードブロックだと
後は、何らかの関数でこのクエリ文字列を動的に実行すればOK。続けてCOPYコマンドのインポートやID列の付加も可能です。例えばPL/pgSQLの無名コードブロックだと
do $$
declare
header text := 'ここにCSVのヘッダ列をコピペ';
tbname text := 'alameda_2'; -- インポート先テーブル名
csvfln text := 'alameda-schools.csv';
begin
execute 'create table ' || tbname ||
'(' || string_agg('"' || colnames || '" text', ', ') || ')'
from unnest(string_to_array(header, ',')) as colnames;
execute 'copy ' || tbname || ' from ''' || csvfln || ''' (format csv, header true)';
execute 'alter table ' || tbname || ' add column rowid serial';
execute 'alter table ' || tbname || ' add primary key (rowid)';
end;
$$;
最初の動的クエリはexecute ... fromという余り見かけない構文ですが ↓ 実行できました。無名コードブロックの次にテーブル定義を\dで表示。テーブル行数が元CSVと同じ395行なのも確認しました(画像では省略)。
(3)とりあえずテキスト型で入れた列の型を変換する
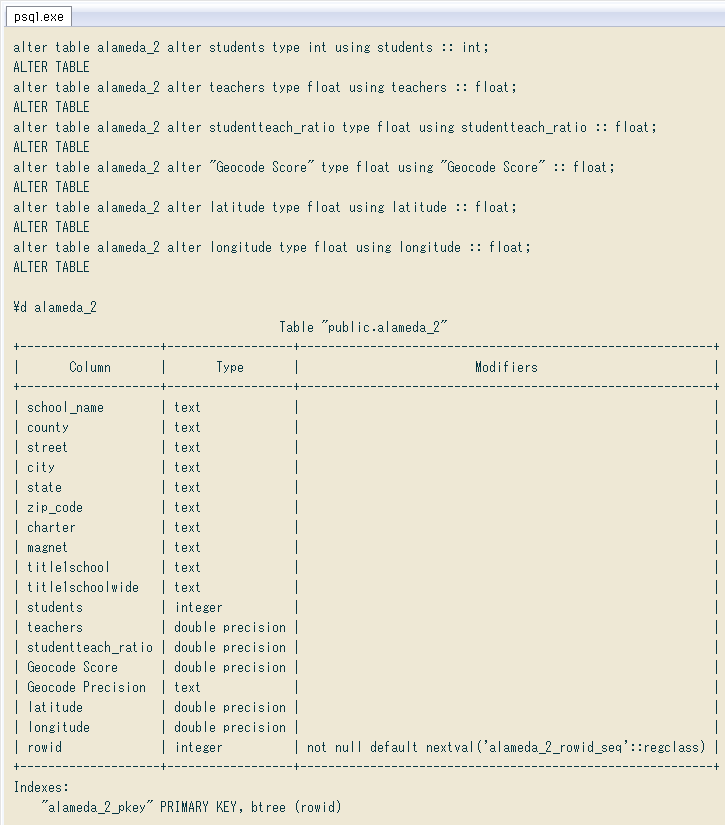
列の型変換は、CSVインポートに限らず、またテキスト型以外からも含めて時々使いそう。今回は ↓ こんな感じでテキストから数値へ変換できました。ただし各列に空文字がない前提。あると単なるキャストでは変換できません(たぶんusingの後にcase句で分岐すればいいと思うけど未確認)。列名・型名を各2回書くのが少し面倒。
-- ひな型
-- alter table テーブル名 alter 列名 type 型名 using 列名 :: 型名;
alter table alameda_2 alter students type int using students :: int;
alter table alameda_2 alter teachers type float using teachers :: float;
alter table alameda_2 alter studentteach_ratio type float using studentteach_ratio :: float;
alter table alameda_2 alter "Geocode Score" type float using "Geocode Score" :: float;
alter table alameda_2 alter latitude type float using latitude :: float;
alter table alameda_2 alter longitude type float using longitude :: float;
 もう一つ、テキストからboolへの型変換。true / false でなくYes / Noの文字列で、PostgreSQLでキャストするとboolになります。というか初めて知りました^^; 今回のCSVでは4つの列が ↓ Yes / No形式で、空のフィールドはNULL化済み(COPYコマンドのデフォルトの動作)。
もう一つ、テキストからboolへの型変換。true / false でなくYes / Noの文字列で、PostgreSQLでキャストするとboolになります。というか初めて知りました^^; 今回のCSVでは4つの列が ↓ Yes / No形式で、空のフィールドはNULL化済み(COPYコマンドのデフォルトの動作)。
\pset null <NULL>
Null display is "<NULL>".
select distinct charter, magnet, title1school, title1schoolwide
from alameda_2;
+---------+--------+--------------+------------------+
| charter | magnet | title1school | title1schoolwide |
+---------+--------+--------------+------------------+
| Yes | <NULL> | No | <NULL> |
| Yes | <NULL> | Yes | Yes |
| No | <NULL> | No | <NULL> |
| No | No | <NULL> | <NULL> |
| No | No | No | <NULL> |
| No | <NULL> | Yes | No |
| Yes | <NULL> | Yes | No |
| No | <NULL> | Yes | Yes |
| Yes | <NULL> | <NULL> | <NULL> |
+---------+--------+--------------+------------------+
(9 rows)
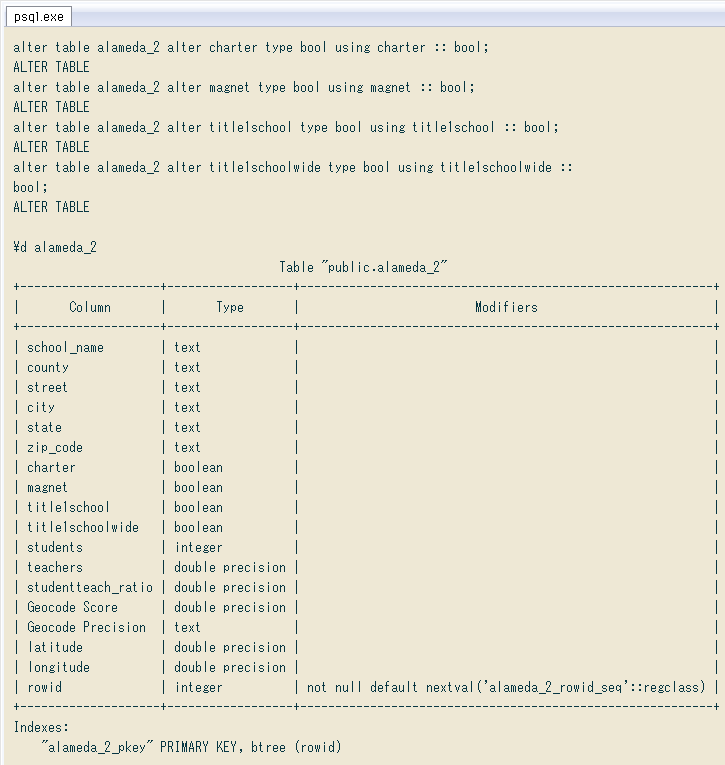
空文字があるとNGですが今回はないので、先ほどと同様 ↓ ALTER TABLE文で型変換できました。
alter table alameda_2 alter charter type bool using charter :: bool;
alter table alameda_2 alter magnet type bool using magnet :: bool;
alter table alameda_2 alter title1school type bool using title1school :: bool;
alter table alameda_2 alter title1schoolwide type bool using title1schoolwide :: bool;
(4)COPYコマンドは「賢い」けどアドホックには少し使いづらい
今日はここまで。(2)と(3)ともにCOPYコマンドを使い、前者では「二重引用符が微妙」なCSVもすんなり取り込めました。ただ、どうしてもインポート先テーブルの事前準備が必須で、CSVの列が多くなるほどそれが面倒…。例えばCSVまるごとは不要だけど一部の行や列をサクッと確認するとかには使いづらい。というわけでCOPYコマンド以外でのCSV処理について、明日以降書きます。