COPYコマンド以外でCSVを扱うPostgreSQLの「道具立て」
昨日はまずインポート先テーブルを作ってからCOPYコマンドでCSVを流し込み、必要に応じてテーブルへの後処理をしました。CSVのデータ全体を使う場合はそうなると思いますが、今日は少し違う場面を想定。テーブルを作るまでもなくCSVを「つまみ食い」したいような時、COPYコマンド以外でのSQL上の方法を考えます。
必要な手順と、PostgreSQLでの道具立ては主に次の四つ。
- ⅰ)ローカルにあるCSVファイルを読み込む → 汎用ファイルアクセス関数を使う
- ⅱ)素直なCSVは単純にカンマで分ける → 配列型へのキャストを使う
- ⅲ)素直でないCSVは何とか正しく区切る → 正規表現関数を使う
- ⅳ)配列にした各行から、必要なフィールド(配列の要素)を抜き出す
以下、各作業について書きます(ⅲの途中からは明日以降に)。
(ⅰ)ローカルにあるCSVファイルをpg_read_file関数で読み込む
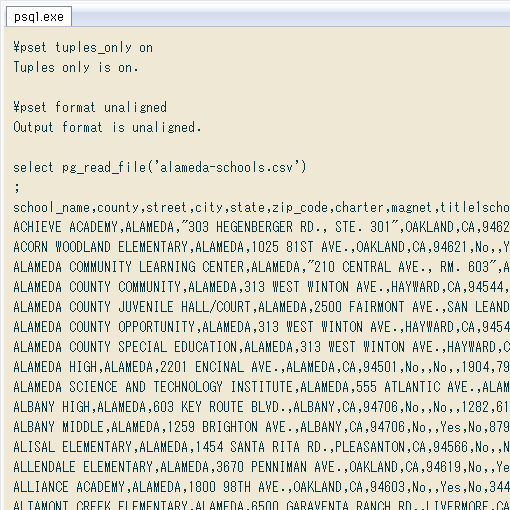
PostgreSQLのクエリ上で、COPYコマンド以外に外部ファイルを扱えるのはpg_read_fileなどの汎用ファイルアクセス関数です。詳細は ↓ こちら。
今回のCSVはPostgreSQLのデータフォルダ直下に置いたので(一昨日の記事参照)この汎用ファイルアクセス関数で読み込めます。文字コードによってはバイナリ用のpg_read_binary_fileを使う必要もありますが、今回のCSVは英数字だけなので普通にテキストファイル用のpg_read_fileでOK。実行すると ↓ こんな感じ。結果を見やすいよう、あらかじめ psqlの表示を変更してます。
\pset tuples_only on
Tuples only is on.
\pset format unaligned
Output format is unaligned.
select pg_read_file('alameda-schools.csv');
school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude
ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363
ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701
ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426
ALAMEDA COUNTY COMMUNITY,ALAMEDA,313 WEST WINTON AVE.,HAYWARD,CA,94544,No,,Yes,No,200,12.0,16.7,1.0,range,37.658168,-122.097027
(...)
 psqlのページャが有効なら(デフォルトではそうなっているはず)CSVの中身が先頭から一画面ずつ表示されます。好きな所まで確認できて便利。
ただしpg_read_file関数は、結果を「一つながりの文字列」として返します。上の結果が一行ずつなのは「改行も文字列の一部」として取り込まれているから。このままでは使えないので、とりあえず一行ずつに分けます。
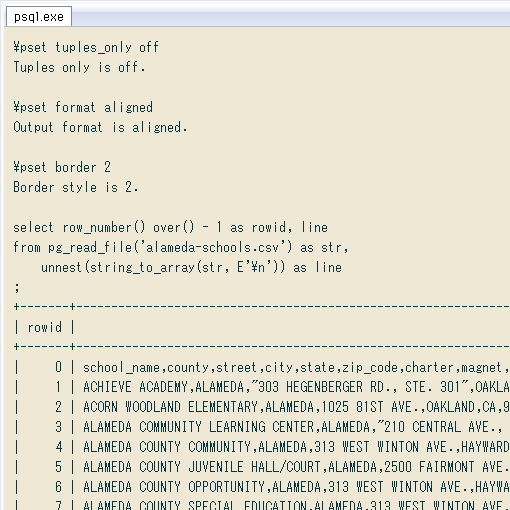
テンプレは ↓ こんな感じ。改行をデリミタとしてstring_to_array関数に渡すと配列になり、それをunnest関数で行に展開。ついでにウィンドウ関数のrow_numberで行番号を振るようにしました。
psqlのページャが有効なら(デフォルトではそうなっているはず)CSVの中身が先頭から一画面ずつ表示されます。好きな所まで確認できて便利。
ただしpg_read_file関数は、結果を「一つながりの文字列」として返します。上の結果が一行ずつなのは「改行も文字列の一部」として取り込まれているから。このままでは使えないので、とりあえず一行ずつに分けます。
テンプレは ↓ こんな感じ。改行をデリミタとしてstring_to_array関数に渡すと配列になり、それをunnest関数で行に展開。ついでにウィンドウ関数のrow_numberで行番号を振るようにしました。
select row_number() over() as rowid, line
from pg_read_file('データフォルダ下のCSVファイルのパス') as str,
unnest(string_to_array(str, E'\n')) as line;
↓ 実行例。最初にpsqlの表示を設定してます。また行番号は、先頭がヘッダという意味を込めてゼロ始まり。
\pset tuples_only off
Tuples only is off.
\pset format aligned
Output format is aligned.
\pset border 2
Border style is 2.
select row_number() over() - 1 as rowid, line
from pg_read_file('alameda-schools.csv') as str,
unnest(string_to_array(str, E'\n')) as line;
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| rowid | line |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 0 | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude |
| 1 | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363 |
| 2 | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701 |
| 3 | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426 |
| 4 | ALAMEDA COUNTY COMMUNITY,ALAMEDA,313 WEST WINTON AVE.,HAYWARD,CA,94544,No,,Yes,No,200,12.0,16.7,1.0,range,37.658168,-122.097027 |
| 5 | ALAMEDA COUNTY JUVENILE HALL/COURT,ALAMEDA,2500 FAIRMONT AVE.,SAN LEANDRO,CA,94578,No,,Yes,No,249,25.5,9.8,0.92,range,37.715126,-122.1165 |
(...)
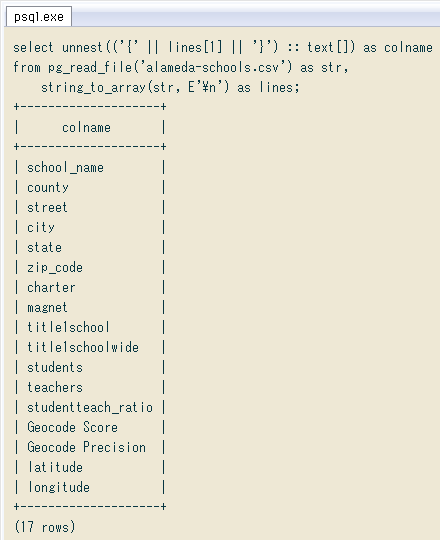
(ⅱ)1行の「素直な」CSVは、そのままPostgreSQLの配列型にできる
前項でCSVを1行ずつにしました。各行が「素直な」CSVなら ↓ こんな風にそのまま配列型にキャストできます。
select '{ 素直なCSVの1行 }' :: text[];
素直なCSVを詳しく言うと ↓ を満たすもの。ドキュメントの「配列の値の入力」の項には余り書かれていません。正確にはソースファイルを見て確認すべきですが、とりあえず自分の経験した範囲では
- カンマのあるデータは二重引用符で囲まれている、またはカンマが\,にエスケープされている
- 空フィールドは空文字 "" かNULLのどちらか。NULLは小文字でもOK
この要件はかなり幅広で、例えば「空白や改行を含むフィールドがあり、二重引用符で囲まれてない」場合でもカンマ区切りで配列になります。ただ泣き所は「カンマの連続で空フィールドを示す」CSVに使えないこと(エラーになる)。空文字とNULLをしっかり区別するPostgreSQLらしいですが、実際そういうCSVが多い…。
今回のCSVは、先ほど先頭から数行見ただけで「カンマの連続で空フィールド」があるので厳しいですが、ヘッダ行に限れば「素直なCSV」なので、この方法で「全列名の配列」を作れます。例えば ↓ こんな風に、改行で分割して配列化したCSVの先頭の要素を取り出し(lines[1])そのまま { } に入れてキャスト。さらに表示用にunnest関数で行にバラしました。CSVファイル名だけ入れ替えれば、汎用的な「CSVの列一覧を見るクエリ」です。
select unnest(('{' || lines[1] || '}') :: text[]) as colname
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines;
+--------------------+
| colnames |
+--------------------+
| school_name |
| county |
| street |
| city |
| state |
| zip_code |
| charter |
| magnet |
| title1school |
| title1schoolwide |
| students |
| teachers |
| studentteach_ratio |
| Geocode Score |
| Geocode Precision |
| latitude |
| longitude |
+--------------------+
(17 rows)
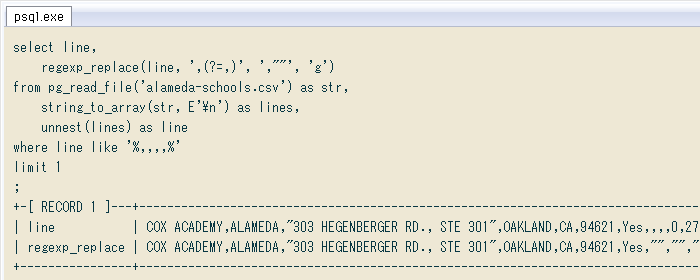
(ⅲ)そのままで配列型にできないCSVを、正規表現で置換する
今回のCSVから「カンマの連続で表された空フィールド」が連続する一行 ↓ を取り出してみました。同じ行に「カンマを含むデータ」もありますが、それは二重引用符で囲まれており無問題。空フィールドを "" かNULLにすればそのまま配列にできるので、正規表現で何とかします。
select line
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines,
unnest(lines) as line
where line like '%,,,,%'
limit 1;
+-----------------------------------------------------------------------------------------------------------------------+
| line |
+-----------------------------------------------------------------------------------------------------------------------+
| COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,,,,0,27.75,,0.604,street,37.736534,-122.19504 |
+-----------------------------------------------------------------------------------------------------------------------+
(1 row)
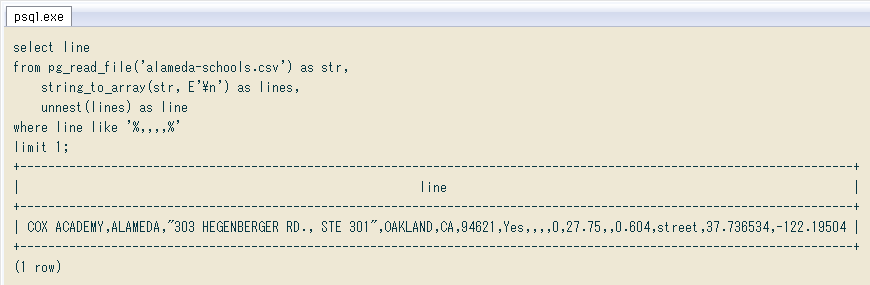 普通の置換で「全ての ,, を ,"", に」するとか、同じことを正規表現関数regexp_replaceで行うのでは ↓ 問題箇所が連続する所で失敗します。
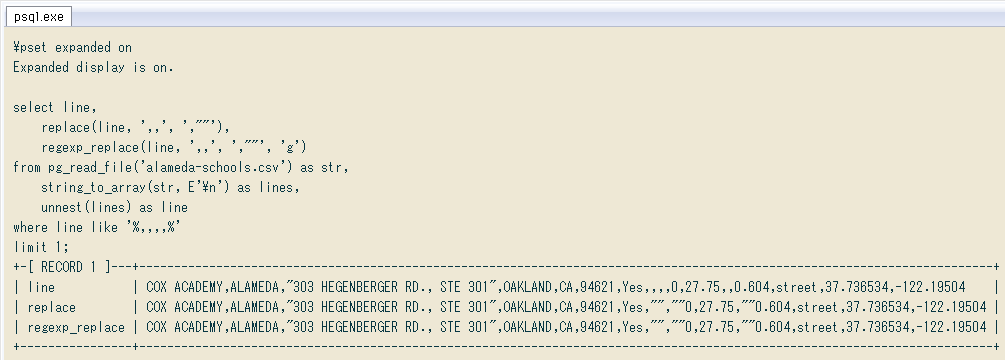
普通の置換で「全ての ,, を ,"", に」するとか、同じことを正規表現関数regexp_replaceで行うのでは ↓ 問題箇所が連続する所で失敗します。
\pset expanded on
Expanded display is on.
select line,
replace(line, ',,', ',""'),
regexp_replace(line, ',,', ',""', 'g')
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines,
unnest(lines) as line
where line like '%,,,,%'
limit 1;
+-[ RECORD 1 ]---+--------------------------------------------------------------------------------------------------------------------------+
| line | COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,,,,0,27.75,,0.604,street,37.736534,-122.19504 |
| replace | COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,"",""0,27.75,""0.604,street,37.736534,-122.19504 |
| regexp_replace | COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,"",""0,27.75,""0.604,street,37.736534,-122.19504 |
+----------------+--------------------------------------------------------------------------------------------------------------------------+
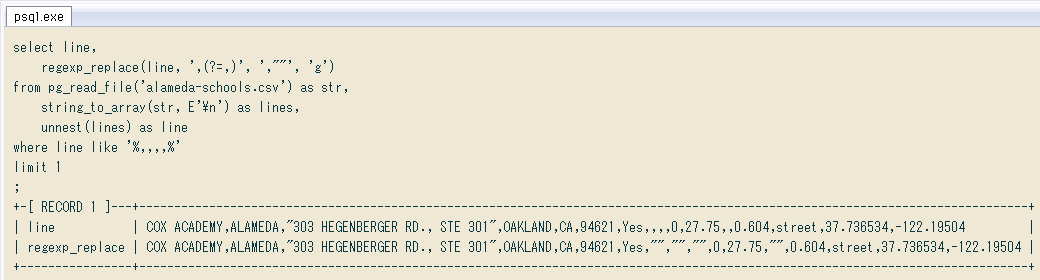
 そこで先日書いた正規表現の肯定先読みを使えば ↓ 全ての空フィールドを空文字に変換できました。
そこで先日書いた正規表現の肯定先読みを使えば ↓ 全ての空フィールドを空文字に変換できました。
select line,
regexp_replace(line, ',(?=,)', ',""', 'g')
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines,
unnest(lines) as line
where line like '%,,,,%'
limit 1
;
+-[ RECORD 1 ]---+-------------------------------------------------------------------------------------------------------------------------------+
| line | COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,,,,0,27.75,,0.604,street,37.736534,-122.19504 |
| regexp_replace | COX ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE 301",OAKLAND,CA,94621,Yes,"","","",0,27.75,"",0.604,street,37.736534,-122.19504 |
+----------------+-------------------------------------------------------------------------------------------------------------------------------+
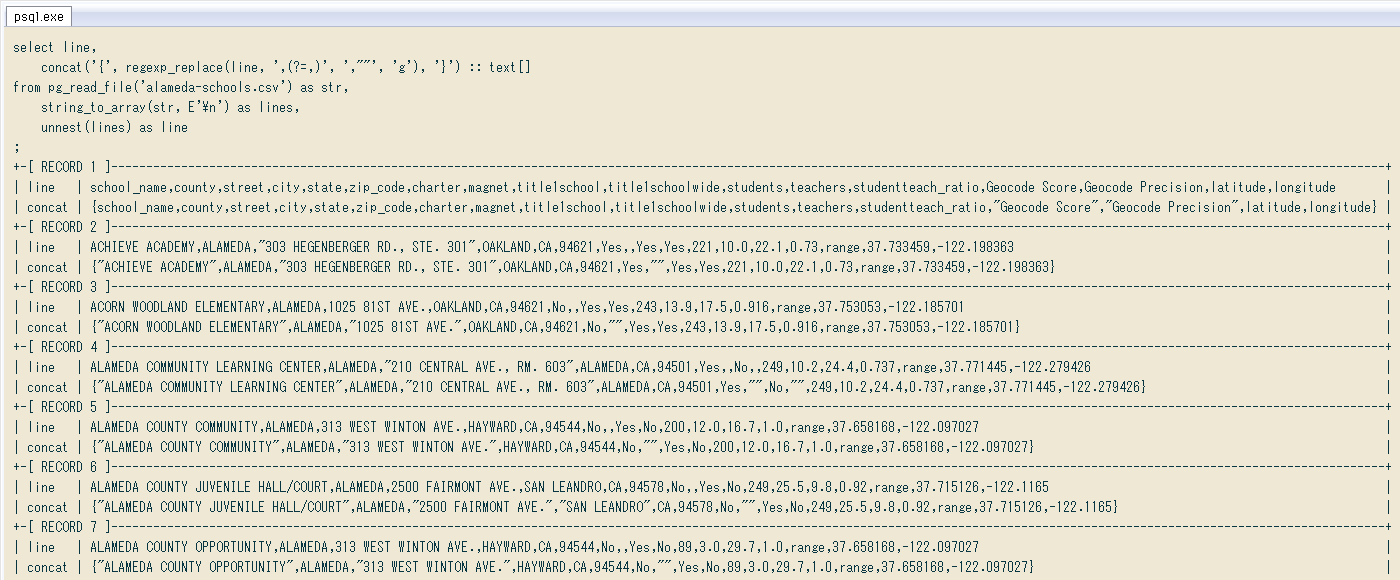
 この正規表現でCSVの全行を置換、続けて配列にキャストし ↓ 問題なく終了。もし二重引用符で囲まれたフィールド内に「連続するカンマ」があったりするとエラーになりますが、今回のCSVはそこまでひどくなかったです。
この正規表現でCSVの全行を置換、続けて配列にキャストし ↓ 問題なく終了。もし二重引用符で囲まれたフィールド内に「連続するカンマ」があったりするとエラーになりますが、今回のCSVはそこまでひどくなかったです。
select line,
concat('{', regexp_replace(line, ',(?=,)', ',""', 'g'), '}') :: text[]
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines,
unnest(lines) as line
;
+-[ RECORD 1 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| line | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude |
| concat | {school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,"Geocode Score","Geocode Precision",latitude,longitude} |
+-[ RECORD 2 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| line | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363 |
| concat | {"ACHIEVE ACADEMY",ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,"",Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363} |
+-[ RECORD 3 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| line | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701 |
| concat | {"ACORN WOODLAND ELEMENTARY",ALAMEDA,"1025 81ST AVE.",OAKLAND,CA,94621,No,"",Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701} |
+-[ RECORD 4 ]--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| line | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426 |
| concat | {"ALAMEDA COMMUNITY LEARNING CENTER",ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,"",No,"",249,10.2,24.4,0.737,range,37.771445,-122.279426} |
(...)
 後々のため、もう少し汎用的な処理を考えると
後々のため、もう少し汎用的な処理を考えると
- 1. データに含まれない適当な「一時的な字」を設定
- 2. 二重引用符で囲まれたフィールド内にカンマがあれば、上の一時的な字に置換
- 3. 全ての連続するカンマを「空文字またはNULLのフィールド」に置換
- 4. 一時的な字を元のカンマに戻す
て感じでしょうか。あー面倒!CSVなんて無くなればいいのに!TSVがデフォルトでいいじゃない! …今日は疲れたので続きは明日以降。