
(ⅲ)続き
前回書いたとおりCSVの各行をPostgreSQLの配列型にキャストできるよう、次の一連の処理をクエリ化します。
- 1. データに含まれない適当な「一時的な字句」を設定
- 2. 二重引用符で囲まれたフィールド内にカンマがあれば、上の一時的な字句に置換(正規表現関数を使う)
- 3. 全ての連続するカンマを「空文字またはNULLのフィールド」に置換( 〃 )
- 4. 一時的な字句を元のカンマに戻す
- …… 結果の文字列を { } に入れて配列型にキャスト
正規表現では2種類のカンマの区別、すなわち「データ間の区切り」と「二重引用符で囲まれたデータ内」を区別する必要があり、PostgreSQLで使える肯定先読み/否定先読みを使います。(関連記事:1月17日)
↓ まず1と2だけ。WITH句で一時的な字句を設定し、二重引用符で囲まれたフィールド内のカンマだけ変換。万が一その字句が元データにあったら当該の行が空になるよう、CASE句で分岐しました。なお「二重引用符内にカンマがあっても一つ」と決まっていれば正規表現はもっと簡単になるけど、汎用性を考えてそうしてません。
with a (fpath, dummy) as (
values ('alameda-schools.csv', '$$comma$$')
)
select line,
case when strpos(line, dummy) > 0 then ''
else regexp_replace(line, ',(?=[^"]*(",|"$))', dummy, 'g')
end
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line;
↓ 今回のCSVに適用した結果。psqlの表示設定で、各行の結果2列を縦に並べています。先頭のみ示していますが、各行が期待どおり変換できました。変換後のカンマは全てデータ間の区切りなので、もう一息。
\pset expanded on
Expanded display is on.
(上のクエリ)
-[ RECORD 1 ]--+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude
regexp_replace | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude
-[ RECORD 2 ]--+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363
regexp_replace | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD.$$comma$$STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363
-[ RECORD 3 ]--+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701
regexp_replace | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701
-[ RECORD 4 ]--+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426
regexp_replace | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE.$$comma$$RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426
(...)
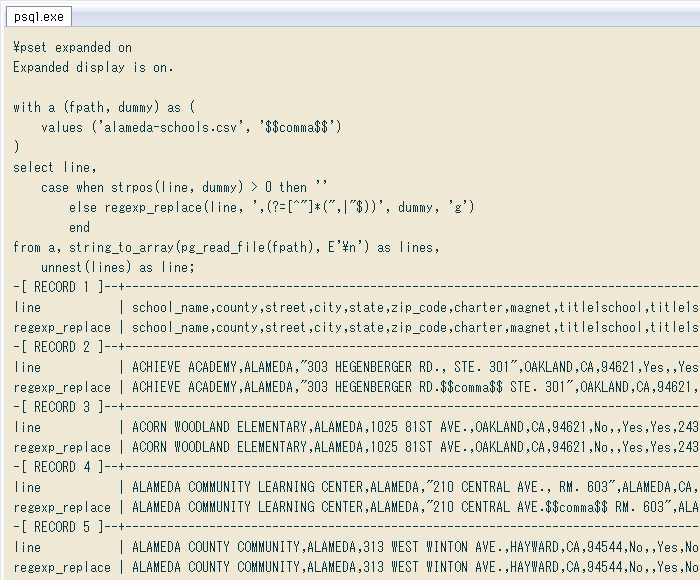 上の結果に残りの手順を追加すると ↓ こんな感じ。「連続カンマ」で空フィールドを表している箇所をNULLに明示化し、PostgreSQLの配列型にキャストします。
上の結果に残りの手順を追加すると ↓ こんな感じ。「連続カンマ」で空フィールドを表している箇所をNULLに明示化し、PostgreSQLの配列型にキャストします。
with a (fpath, dummy) as (
values ('alameda-schools.csv', '$$comma$$')
), b (line, tmp) as (
select line,
case when strpos(line, dummy) > 0 then ''
else regexp_replace(line, ',(?=[^"]*(",|"$))', dummy, 'g')
end
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line
)
select b.*, ('{' || replace(
regexp_replace(tmp, ',(?=,)', ',NULL', 'g'),
dummy, ',') || '}') :: text [] as array
from a, b;
↓ 実行結果。先ほどと同様psqlの表示設定で、各行の結果3列を縦に並べています。上から元CSV、二重引用符内のカンマを適当に変換、配列に変換後。
\pset expanded on
Expanded display is on.
(上のクエリ)
-[ RECORD 1 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude
tmp | school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,Geocode Score,Geocode Precision,latitude,longitude
array | {school_name,county,street,city,state,zip_code,charter,magnet,title1school,title1schoolwide,students,teachers,studentteach_ratio,"Geocode Score","Geocode Precision",latitude,longitude}
-[ RECORD 2 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363
tmp | ACHIEVE ACADEMY,ALAMEDA,"303 HEGENBERGER RD.$$comma$$ STE. 301",OAKLAND,CA,94621,Yes,,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363
array | {"ACHIEVE ACADEMY",ALAMEDA,"303 HEGENBERGER RD., STE. 301",OAKLAND,CA,94621,Yes,NULL,Yes,Yes,221,10.0,22.1,0.73,range,37.733459,-122.198363}
-[ RECORD 3 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701
tmp | ACORN WOODLAND ELEMENTARY,ALAMEDA,1025 81ST AVE.,OAKLAND,CA,94621,No,,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701
array | {"ACORN WOODLAND ELEMENTARY",ALAMEDA,"1025 81ST AVE.",OAKLAND,CA,94621,No,NULL,Yes,Yes,243,13.9,17.5,0.916,range,37.753053,-122.185701}
-[ RECORD 4 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
line | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426
tmp | ALAMEDA COMMUNITY LEARNING CENTER,ALAMEDA,"210 CENTRAL AVE.$$comma$$ RM. 603",ALAMEDA,CA,94501,Yes,,No,,249,10.2,24.4,0.737,range,37.771445,-122.279426
array | {"ALAMEDA COMMUNITY LEARNING CENTER",ALAMEDA,"210 CENTRAL AVE., RM. 603",ALAMEDA,CA,94501,Yes,NULL,No,NULL,249,10.2,24.4,0.737,range,37.771445,-122.279426}
(...)
 もしカンマを適当に変換した字句(今回では$$comma$$)が元データにあると、2列目(tmp)がNULLになって配列型にキャストできずエラーになります。またカンマや二重引用符に関して想定外のイレギュラーな並びがあっても、同様に配列へのキャスト時にエラーが発生。つまり上のように結果が返ってくれば、全行を見なくとも、今回のCSVは全行とりあえず配列に変換できたと分かります。
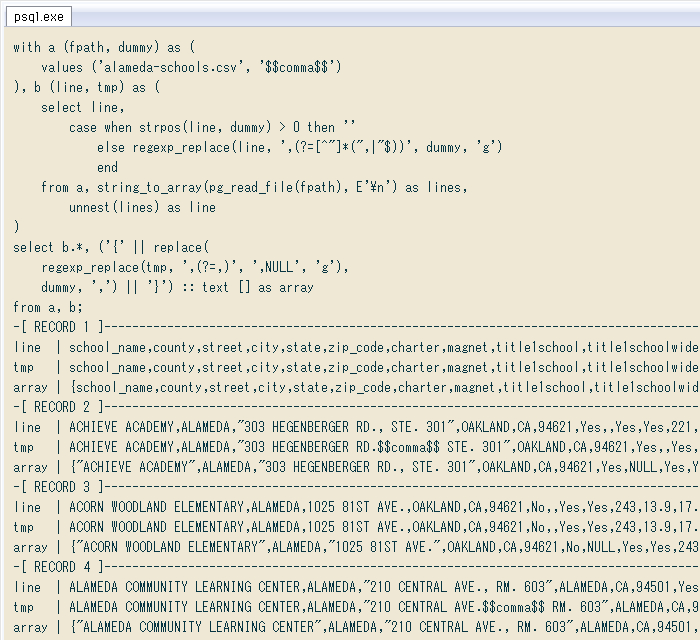
別の確認として ↓ 各行の配列の要素数を調べるクエリ。DISTINCT句で重複を削除した結果の要素数が1行だけ返ればOK、そうでなければ一部の行で列区切りが正しく認識されてないので見直します。
もしカンマを適当に変換した字句(今回では$$comma$$)が元データにあると、2列目(tmp)がNULLになって配列型にキャストできずエラーになります。またカンマや二重引用符に関して想定外のイレギュラーな並びがあっても、同様に配列へのキャスト時にエラーが発生。つまり上のように結果が返ってくれば、全行を見なくとも、今回のCSVは全行とりあえず配列に変換できたと分かります。
別の確認として ↓ 各行の配列の要素数を調べるクエリ。DISTINCT句で重複を削除した結果の要素数が1行だけ返ればOK、そうでなければ一部の行で列区切りが正しく認識されてないので見直します。
with a (fpath, dummy) as (
values ('alameda-schools.csv', '$$comma$$')
), b (line, tmp) as (
select line,
case when strpos(line, dummy) > 0 then ''
else regexp_replace(line, ',(?=[^"]*(",|"$))', dummy, 'g')
end
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line
)
select distinct array_length(('{' || replace(
regexp_replace(tmp, ',(?=,)', ',NULL', 'g'),
dummy, ',') || '}') :: text [], 1) as ncol_check
from a, b
;
+------------+
| ncol_check |
+------------+
| 17 |
+------------+
(1 row)
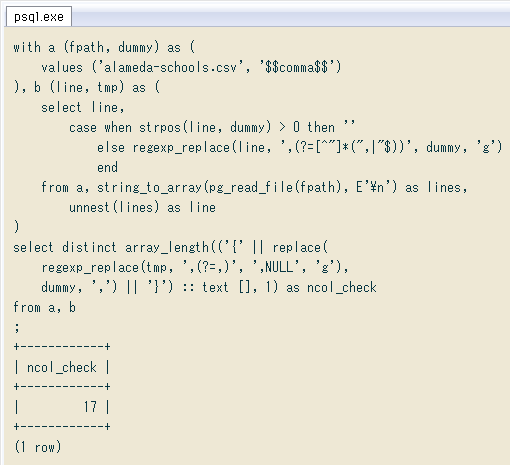
(ⅳ)配列にしたCSVの各行から、必要なフィールド(配列の要素)を抜き出す
CSVの各行が配列になれば、後は添字で任意の列を取り出せます。この時「番号付きの列名一覧」があると便利。昨日作った「CSVの列一覧を見るクエリ」を少し変えて ↓ こんな感じ。列番号は、PostgreSQL 9.4で追加されたunnest ... with ordinalilty構文を使っています。
with a (colnames) as (
select ('{' || lines[1] || '}') :: text[]
from pg_read_file('alameda-schools.csv') as str,
string_to_array(str, E'\n') as lines
)
select id, colname
from a, unnest(colnames) with ordinality as foo(colname, id)
;
+----+--------------------+
| id | colname |
+----+--------------------+
| 1 | school_name |
| 2 | county |
| 3 | street |
| 4 | city |
| 5 | state |
| 6 | zip_code |
| 7 | charter |
| 8 | magnet |
| 9 | title1school |
| 10 | title1schoolwide |
| 11 | students |
| 12 | teachers |
| 13 | studentteach_ratio |
| 14 | Geocode Score |
| 15 | Geocode Precision |
| 16 | latitude |
| 17 | longitude |
+----+--------------------+
(17 rows)
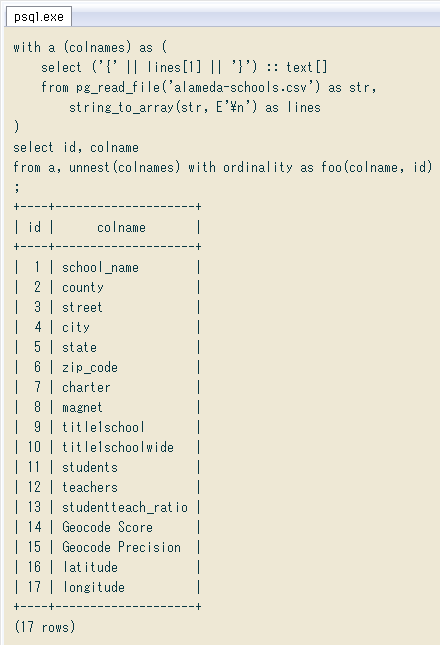 今回のCSVは元々GISチュートリアルに使う点データなので(詳細は1月18日の記事)最後の2列が緯度・経度。例えばとりあえず地図にプロットするなら、経緯度の列番号を添字にして ↓ こんな風に抽出できます。
今回のCSVは元々GISチュートリアルに使う点データなので(詳細は1月18日の記事)最後の2列が緯度・経度。例えばとりあえず地図にプロットするなら、経緯度の列番号を添字にして ↓ こんな風に抽出できます。
with a (fpath, dummy) as (
values ('alameda-schools.csv', '$$comma$$')
), b (line, tmp) as (
select line,
case when strpos(line, dummy) > 0 then ''
else regexp_replace(line, ',(?=[^"]*(",|"$))', dummy, 'g')
end
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line
), c (ary) as (
select ('{' || replace(
regexp_replace(tmp, ',(?=,)', ',NULL', 'g'),
dummy, ',') || '}') :: text []
from a, b
offset 1 -- 先頭のヘッダ行を除く
)
select ary[16] :: float as lat, ary[17] :: float as lon
from c
;
+-----------+-------------+
| lat | lon |
+-----------+-------------+
| 37.733459 | -122.198363 |
| 37.753053 | -122.185701 |
| 37.771445 | -122.279426 |
| 37.658168 | -122.097027 |
| 37.715126 | -122.1165 |
| 37.658168 | -122.097027 |
| 37.658168 | -122.097027 |
| 37.764236 | -122.248243 |
(...)
CSVの列数が多いほど、この「番号付き列名一覧」と「各行を配列化したデータ」のペアが便利。とは言え配列化のためには正規表現できちんと列を区切る手間があり、COPYコマンドとどちらが良いかはケースバイケースです。
(ⅴ)まとめ・補足
今回の「素直な」とは、CSVの各行が「PostgreSQLの配列にそのままキャストできる」こと。具体的な要件は昨日の記事に書きました。その場合、正規表現は必要なく ↓ 簡単に「各行を配列化したデータ」をクエリで得られます。
with a (fpath) as (
values ('CSVのファイルパス')
)
select ('{' || line || '}') :: text [] as array
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line;
これならアドホックにも使え、COPYコマンドのように「必ず事前にテーブルを用意する」必要がないので手軽かも。ところが、今回のCSVのように「空フィールドが連続カンマ」「データ中にもカンマがある」場合、列区切りを正規表現できちんと捉えるため ↓ こんな長くなってしまう…。
with a (fpath, dummy) as (
values ('CSVのファイルパス', 'カンマの一時置換用の字句')
), b (line, tmp) as (
select line,
case when strpos(line, dummy) > 0 then ''
else regexp_replace(line, ',(?=[^"]*(",|"$))', dummy, 'g')
end
from a, string_to_array(pg_read_file(fpath), E'\n') as lines,
unnest(lines) as line
)
select b.*, ('{' || replace(
regexp_replace(tmp, ',(?=,)', ',NULL', 'g'),
dummy, ',') || '}') :: text [] as array
from a, b;
結局、CSVが「データとしてもよく使われるカンマを区切り文字にしてしまった」のが諸悪の根源のような…。早く廃れるといいけど。以下、補足です。
(1)今回紹介したクエリはCSVから「番号付き列名一覧」と「各行を配列化したデータ」を表示するまでですが、これを CREATE TABLE ... AS または SELECT ... INTO でテーブルに保存すれば、COPYコマンド以外でのインポートになります。そのクエリは簡単なので省略しました。
(2)連続するカンマを処理する今回の正規表現では、カンマの前後に空白を含む場合を想定してません。そこまでひどいCSVは見たことがないので。どうしても必要なら ',(?=\s*,)' で対応できると思います。
(3)もし対象とするCSVの問題が「連続カンマ」だけなら、配列へのキャストでなくstring_to_array関数またはregexp_split_to_array関数で区切り文字をカンマにする方法もあります。前者は引数の使い方次第で、空フィールドを空文字/NULLのどちらにも変換可能。↓ 簡単な例です。
-- 空フィールド -> 空文字
select string_to_array('1,2,,,5,6,7', ',');
+-------------------+
| string_to_array |
+-------------------+
| {1,2,"","",5,6,7} |
+-------------------+
(1 row)
-- 空フィールド -> NULL
select string_to_array('1,2,,,5,6,7', ',', '');
+-----------------------+
| string_to_array |
+-----------------------+
| {1,2,NULL,NULL,5,6,7} |
+-----------------------+
(1 row)
-- 区切りを正規表現で指定
-- 空フィールド -> 空文字のみ. NULLにはできない
select regexp_split_to_array('1, 2, , , 5, 6, 7', '\s*,\s*');
+-----------------------+
| regexp_split_to_array |
+-----------------------+
| {1,2,"","",5,6,7} |
+-----------------------+
(1 row)
