$ sqlte3 test_sqlite3.db SQLite version 3.12.2 2016-04-19 15:16:33 Enter ".help" for usage hints. sqlite> .mode csv sqlite> .import 'WHO_Tuberculosis/TB_strategy_2016-02-15.csv' TB_strategy sqlite> sqlite> .schema TB_strategy CREATE TABLE TB_strategy( "country" TEXT, "iso2" TEXT, "iso3" TEXT, "iso_numeric" TEXT, "g_whoregion" TEXT, "year" TEXT, "xpert_in_guide_TBHIV" TEXT, "xpert_in_guide_MDR" TEXT, "xpert_in_guide_tb" TEXT, "xpert_in_guide_children" TEXT, "xpert_in_guide_eptb" TEXT, "eol_care" TEXT, "caseb_err_nat" TEXT, "hcw_tb_infected" TEXT, "hcw_tot" TEXT, "pub_new_dx" TEXT, "priv_new_dx" TEXT, "mdr_tx_nonntp" TEXT ); sqlite> select * from tb_strategy;
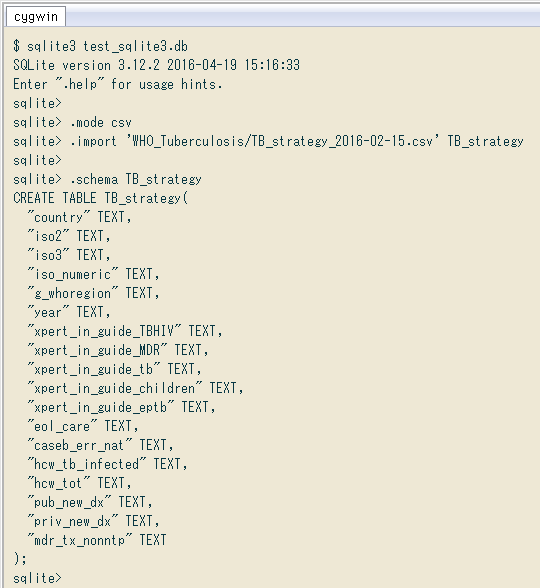
環境による差はないと思いますが一応、実行環境は
インポートしてみた
» 画像
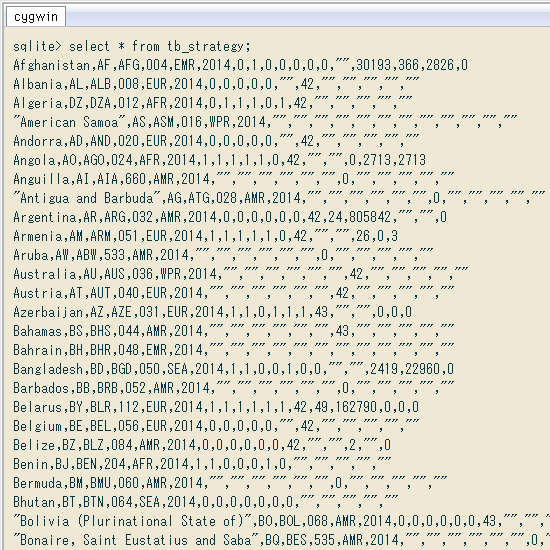{kind=link}
» 画像
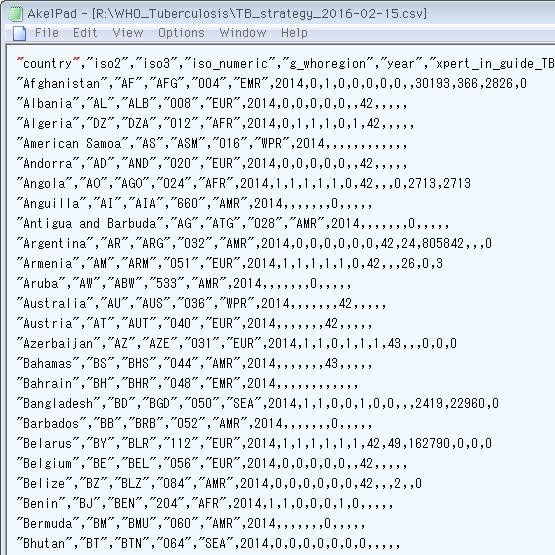{kind=link}
今回使ったコマンドは
»
↓ ドキュメントから
.mode MODE ?TABLE? Set output mode where MODE is one of: ascii Columns/rows delimited by 0x1F and 0x1E csv Comma-separated values column Left-aligned columns. (See .width) html HTML <table> code insert SQL insert statements for TABLE line One value per line list Values delimited by .separator strings tabs Tab-separated values tcl TCL list elements
ただ、先頭行がヘッダになってない変則的な
sqlite> .import 'estat/00320.csv' estat_00320 CREATE TABLE estat_00320(...) failed: duplicate column name:
用いたのは ↓ から表
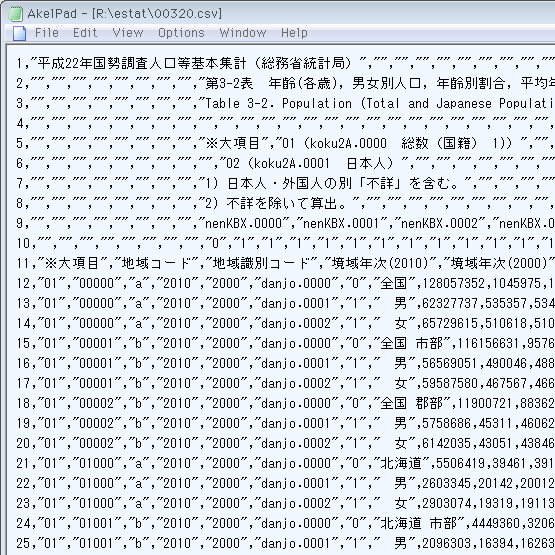{kind=link}
» 平成
というわけで、ヘッダ行がちゃんとある普通の