Contents
- サンプルテーブル作成と、例のエラーを再現
- convert_from
を使う - 逆パターンのエラーには使えない
- convert_to
の使いみち
サンプルテーブル作成と、例のエラーを再現
↓ 文字コード# create table test_kana as select chr(i) from generate_series(12353, 12542) as i; SELECT 190 # select * from test_kana; +-----+ | chr | +-----+ | ぁ | | あ | | ぃ | | い | | ぅ | | う | | ぇ | | え | | ぉ | | お | | か | | が | | き | ... | ヱ | | ヲ | | ン | | ヴ | | ヵ | | ヶ | | ヷ | | ヸ | | ヹ | | ヺ | | ・ | | ー | | ヽ | | ヾ | +-----+ (190 rows)

このテーブルを「ユニコード固有の字があると知らずに
# copy test_kana to '/test_kana_sjis.tsv' (encoding sjis);ERROR: character with byte sequence 0xe3 0x82 0x94 in encoding "UTF8" has no equivalent in encoding "SJIS"
日本語メッセージなら「符号化方式
convert_from
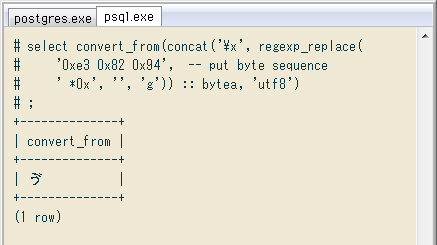
マニュアルの文字列処理関数のページにある# select convert_from(
concat('\x', 'e3', '82', '94') :: bytea,
'utf8');
+--------------+
| convert_from |
+--------------+
| ゔ |
+--------------+
(1 row)
シーケンスから
select convert_from(concat('\x', regexp_replace(
'0xe3 0x82 0x94', -- put byte sequence
' *0x', '', 'g')) :: bytea, 'utf8');
逆パターンのエラーには使えない
同じようなメッセージ「符号化方式↓ 現象の例。先ほどのサンプルテーブルから先頭
# copy (select * from test_kana limit 50) to '/test_kana_sjis.tsv' (encoding sjis); COPY 50 # copy test_kana from '/test_kana_sjis.tsv'; ERROR: invalid byte sequence for encoding "UTF8": 0x82 CONTEXT: COPY test_kana, line 1
convert_to
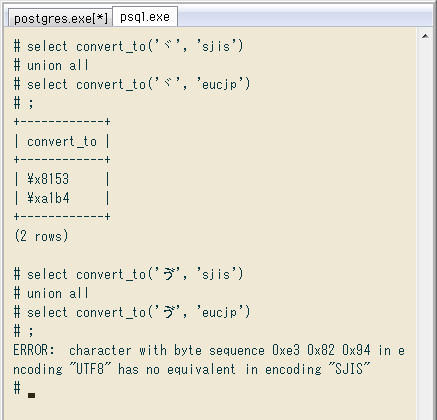
convert_from# select convert_to('ヾ', 'sjis')
union all
select convert_to('ヾ', 'eucjp');
+------------+
| convert_to |
+------------+
| \x8153 |
| \xa1b4 |
+------------+
(2 rows)
-- 両方の文字コードに字が存在
# select convert_to('ゔ', 'sjis')
union all
select convert_to('ゔ', 'eucjp');
ERROR: character with byte sequence 0xe3 0x82 0x94 in
encoding "UTF8" has no equivalent in encoding "SJIS"
-- 一行目(SJISへの変換)が失敗 = 文字が存在しない
1
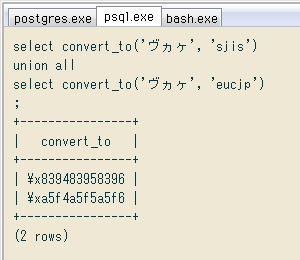
select convert_to('ヴヵヶ', 'sjis')
union all
select convert_to('ヴヵヶ', 'eucjp');
+----------------+
| convert_to |
+----------------+
| \x839483958396 |
| \xa5f4a5f5a5f6 |
+----------------+
(2 rows)