# select * from cols_ja; +----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | id | 項目1 | 項目2 | 項目3 | 項目4 | 項目5 | 項目6 | 項目7 | 項目8 | 項目9 | +----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | 1 | 8 | 0.4 | 680 | 80 | 23.1 | 91 | 12.4 | 94.9 | 1.1 | | 2 | 7 | 51.9 | 74 | 116 | 95.2 | 42.4 | 49.2 | 48.6 | 85.4 | | 3 | 8 | 51.2 | 411 | 248 | 39.4 | 42.1 | 75.2 | 95.3 | 18.2 | | 4 | 1 | 55.6 | 530 | 565 | 41.2 | 53.4 | 24.5 | 49.2 | 76.6 | | 5 | 1 | 61.6 | 714 | 166 | 35.1 | 23.3 | 24 | 46.7 | 18.5 | | 6 | 6 | 95.9 | 672 | 518 | 78 | 18.4 | 92.9 | 2.8 | 57.8 | | 7 | 3 | 78 | 532 | 532 | 89.8 | 8.7 | 6.2 | 46.3 | 49.9 | | 8 | 5 | 70.8 | 991 | 362 | 86.3 | 60.7 | 7.7 | 2.9 | 95.8 | | 9 | 3 | 27 | 425 | 495 | 93.4 | 38.4 | 16.7 | 45.1 | 16.5 | | 10 | 3 | 38 | 193 | 929 | 72.9 | 97.3 | 46.1 | 26.1 | 87.2 | +----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ (10 rows)
クエリで他テーブルと一緒に使う際 ↓
select *
from other_table, (
select * cols_ja
-- TODO: change colname "id" to "rowid"
) as foo;
id
select id as rowid, * from cols_ja; +-------+----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | rowid | id | 項目1 | 項目2 | 項目3 | 項目4 | 項目5 | 項目6 | 項目7 | 項目8 | 項目9 | +-------+----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | 1 | 1 | 8 | 0.4 | 680 | 80 | 23.1 | 91 | 12.4 | 94.9 | 1.1 | | 2 | 2 | 7 | 51.9 | 74 | 116 | 95.2 | 42.4 | 49.2 | 48.6 | 85.4 | | 3 | 3 | 8 | 51.2 | 411 | 248 | 39.4 | 42.1 | 75.2 | 95.3 | 18.2 | ...
今までは律義に ↓ こう書いてました。列数が多くてやだな~と思いつつ。
select *
from other_table, (
select id as rowid, "項目1", "項目3", "項目3", "項目4", "項目5",
"項目6", "項目7", "項目8", "項目9"
from cols_ja
) as foo;
ところが ↓ テーブルエイリアスの後に、先頭からの列名を、実テーブルより少ない列数で指定できるんですよ
select * from cols_jaas foo (rowid); +-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | rowid | 項目1 | 項目2 | 項目3 | 項目4 | 項目5 | 項目6 | 項目7 | 項目8 | 項目9 | +-------+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | 1 | 8 | 0.4 | 680 | 80 | 23.1 | 91 | 12.4 | 94.9 | 1.1 | | 2 | 7 | 51.9 | 74 | 116 | 95.2 | 42.4 | 49.2 | 48.6 | 85.4 | | 3 | 8 | 51.2 | 411 | 248 | 39.4 | 42.1 | 75.2 | 95.3 | 18.2 | ...
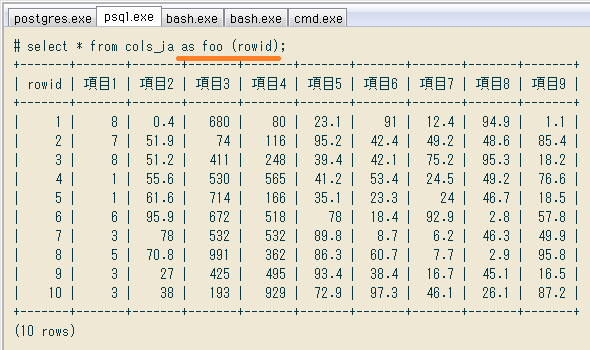
つまりエイリアスに書かれた列名が左端から適用され、足りなくなったら実テーブルの列名が使われるらしい。だから先ほどのクエリ(他テーブルと併用時)も ↓ こんなに簡単になります。あ~もっと早く知ってれば
-- past
select *
from other_table, (
select id as rowid, "項目1", "項目3", "項目3", "項目4", "項目5",
"項目6", "項目7", "項目8", "項目9"
from cols_ja
) as foo;
-- from now on
select *
from other_table,
cols_ja as foo(rowid);
最左列に限らず ↓ こんな風にできます。左の方にある列名をフレキシブルに変える際、とても便利。
select * from cols_jaas foo (id, data1, data2); +----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | id | data1 | data2 | 項目3 | 項目4 | 項目5 | 項目6 | 項目7 | 項目8 | 項目9 | +----+-------+-------+-------+-------+-------+-------+-------+-------+-------+ | 1 | 8 | 0.4 | 680 | 80 | 23.1 | 91 | 12.4 | 94.9 | 1.1 | | 2 | 7 | 51.9 | 74 | 116 | 95.2 | 42.4 | 49.2 | 48.6 | 85.4 | | 3 | 8 | 51.2 | 411 | 248 | 39.4 | 42.1 | 75.2 | 95.3 | 18.2 | ...
サブクエリに限らず
with a(rowid) as ( select * from cols_ja ) select * from a;
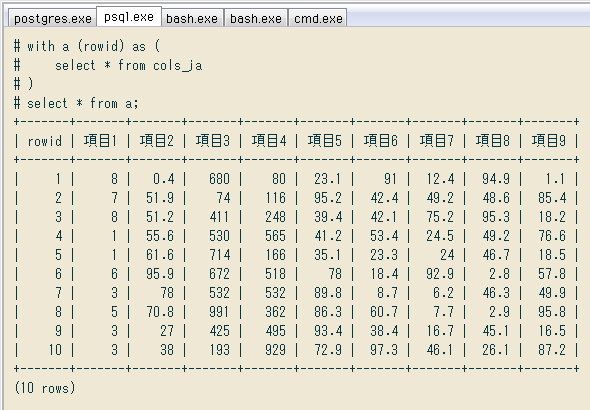
過去記事のクエリも、今回のを使って簡単になるのが結構多そう。ほんとに