昔は無理矢理なクエリを書いてましたが、9.4以降のunnest...with ordinalityによって「2次元配列 ⇒ 複数行の1次元配列にバラす」のが割と簡単になりました。逆の「複数行の1次元配列 ⇒ 一つの2次元配列に束ねる」は、9.5でarray_agg関数が強化されたので楽々。両方の簡単な例を紹介します。動作確認バージョンは9.5.2。
 今日は3行×4列の小さな2次元配列 ↓ を例に、まず複数行の1次元配列化から。
今日は3行×4列の小さな2次元配列 ↓ を例に、まず複数行の1次元配列化から。
select '{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 0, 1, 2}
}' :: int[];
+---------------------------------+
| int4 |
+---------------------------------+
| {{1,2,3,4},{5,6,7,8},{9,0,1,2}} |
+---------------------------------+
(1 row)
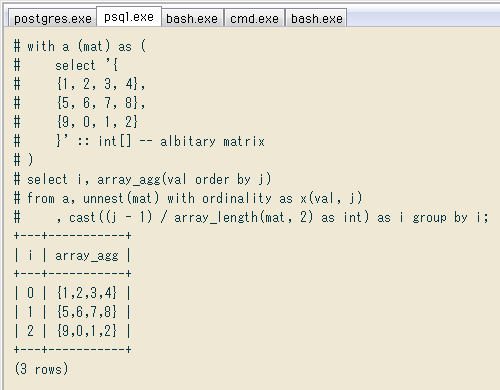
↓ 完成形のクエリ。上の2次元配列をWITH句の最初でmatと名付け、後はSELECT一文で処理してます。説明は画像の下に。
with a (mat) as (
select '{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 0, 1, 2}
}' :: int[] -- albitary matrix
)
select i, array_agg(val order by j)
from a, unnest(mat) with ordinality as x(val, j)
, cast((j - 1) / array_length(mat, 2) as int) as i group by i;
+---+-----------+
| i | array_agg |
+---+-----------+
| 0 | {1,2,3,4} |
| 1 | {5,6,7,8} |
| 2 | {9,0,1,2} |
+---+-----------+
(3 rows)
以下、段階的な説明です。最初にunnest...with ordinalityの結果だけ示すと ↓ こう。unnestは、2次元に限らず何次元でも「全次元をキャンセル」してフラットに一要素ずつに分けてしまう。他には配列をバラす関数がなくて不便だけど、PostgreSQL9.4で追加されたwith ordinalityが要素添字を付けるので(下のj)、これを活用します。
with a (mat) as (
select '{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 0, 1, 2}
}' :: int[]
)
select val, j
from a, unnest(mat) with ordinality as x(val, j);
+-----+----+
| val | j |
+-----+----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| 0 | 10 |
| 1 | 11 |
| 2 | 12 |
+-----+----+
(12 rows)
↓ 2次元配列の列数は固定だから、要素添字と計算すれば行番号が出ます(下のi)。列数を出すのはarray_length関数。castは実質的な意味がなく、fromの後に置くため便宜的なもの。式のままだとselect...fromの間にしか置けず、見にくいので。
with a (mat) as (
select '{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 0, 1, 2}
}' :: int[]
)
select i, j, val
from a, unnest(mat) with ordinality as x(val, j)
, cast((j - 1) / array_length(mat, 2) as int) as i;
+---+----+-----+
| i | j | val |
+---+----+-----+
| 0 | 1 | 1 |
| 0 | 2 | 2 |
| 0 | 3 | 3 |
| 0 | 4 | 4 |
| 1 | 5 | 5 |
| 1 | 6 | 6 |
| 1 | 7 | 7 |
| 1 | 8 | 8 |
| 2 | 9 | 9 |
| 2 | 10 | 0 |
| 2 | 11 | 1 |
| 2 | 12 | 2 |
+---+----+-----+
(12 rows)
後は行番号iごとにグループ化し、array_aggで1次元配列に束ねるだけ。元の列順(下のj)を維持するためarray_agg内にorder byを使ってます。↓ 最初のクエリ再掲。
with a (mat) as (
select '{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 0, 1, 2}
}' :: int[] -- albitary matrix
)
select i, array_agg(val order by j)
from a, unnest(mat) with ordinality as x(val, j)
, cast((j - 1) / array_length(mat, 2) as int) as i group by i;
+---+-----------+
| i | array_agg |
+---+-----------+
| 0 | {1,2,3,4} |
| 1 | {5,6,7,8} |
| 2 | {9,0,1,2} |
+---+-----------+
(3 rows)
2次元配列をバラすのは以上。逆に、複数行の1次元配列を2次元配列化するには、冒頭で書いたとおりPostgreSQL9.5からarray_agg関数で一発。↓ 最初に作った2次元配列が復元されてます。
with a (ary) as (
values ( '{1, 2, 3, 4}' :: int[] ),
( '{5, 6, 7, 8}' ),
( '{9, 0, 1, 2}' )
)
select array_agg(ary) from a;
+---------------------------------+
| array_agg |
+---------------------------------+
| {{1,2,3,4},{5,6,7,8},{9,0,1,2}} |
+---------------------------------+
(1 row)
 ↓ array_agg内のorder byは、1次元配列を束ねる時も有効。動作の詳細は未確認ですが、少なくとも先頭要素が重複してなければその順番になるっぽい。
↓ array_agg内のorder byは、1次元配列を束ねる時も有効。動作の詳細は未確認ですが、少なくとも先頭要素が重複してなければその順番になるっぽい。
with a (ary) as (
values ( '{1, 2, 3, 4}' :: int[] ),
( '{5, 6, 7, 8}' ),
( '{9, 0, 1, 2}' )
)
select array_agg(ary order by ary desc) from a;
+---------------------------------+
| array_agg |
+---------------------------------+
| {{9,0,1,2},{5,6,7,8},{1,2,3,4}} |
+---------------------------------+
(1 row)
 もう少しサイズの大きい2次元配列も作ってテストしましたが、結果が同じだし記事が長過ぎくなるので割愛します。そのサンプル配列を作る際、手入力でなく適当な文字列から自動的に作るクエリ(Rのmatrix(vector, nrow, ncol)みたいな)を考えたので、意味ありそうだったら明日書きます。
もう少しサイズの大きい2次元配列も作ってテストしましたが、結果が同じだし記事が長過ぎくなるので割愛します。そのサンプル配列を作る際、手入力でなく適当な文字列から自動的に作るクエリ(Rのmatrix(vector, nrow, ncol)みたいな)を考えたので、意味ありそうだったら明日書きます。