(1)でよくあるのは、CSV
最初にサンプルテーブルの作成。クエリとともに示すと ↓ こんな感じです。ex1
create table ex1_duplicated as
with a (id, v1, v2) as (
select i,
round(random() :: numeric * 50, 1) + 25,
(random() * 1e+5) :: int
from generate_series(1, 10) as i
)
select * from a
union all
select * from a where id in (2, 4, 6);
select * from ex1_duplicated order by id;
+----+------+-------+
| id | v1 | v2 |
+----+------+-------+
| 1 | 45.1 | 25717 |
| 2 | 48.2 | 11497 | -- dup
| 2 | 48.2 | 11497 | -- dup
| 3 | 45.8 | 8680 |
| 4 | 65.7 | 69892 | -- dup
| 4 | 65.7 | 69892 | -- dup
| 5 | 30.9 | 69303 |
| 6 | 67.1 | 68719 | -- dup
| 6 | 67.1 | 68719 | -- dup
| 7 | 42.5 | 9535 |
| 8 | 57.1 | 81801 |
| 9 | 35.1 | 53506 |
| 10 | 28.2 | 14749 |
+----+------+-------+
(13 rows)
create table ex2_duplicated as
select ceil(random() * 9) :: int as id,
round(random() :: numeric * 50, 1) + 25 as v1,
(random() * 1e+5) :: int as v2
from generate_series(1, 15)
order by 1;
select * from ex2_duplicated order by id;
+----+------+-------+
| id | v1 | v2 |
+----+------+-------+
| 2 | 44.0 | 58432 |
| 2 | 40.3 | 21274 |
| 3 | 48.9 | 34272 |
| 3 | 74.3 | 91995 |
| 4 | 59.9 | 2754 |
| 4 | 64.9 | 47945 |
| 4 | 41.0 | 15123 |
| 4 | 29.7 | 51639 |
| 6 | 25.5 | 93051 |
| 7 | 45.8 | 24025 |
| 8 | 44.9 | 46623 |
| 8 | 71.9 | 46514 |
| 8 | 35.3 | 98214 |
| 8 | 67.3 | 3839 |
| 9 | 27.1 | 89533 |
+----+------+-------+
(15 rows)
create table ex3_duplicated as
select row_number() over() :: int as id,
v1, v2
from ex1_duplicated;
select * from ex3_duplicated order by id;
+----+------+-------+
| id | v1 | v2 |
+----+------+-------+
| 1 | 45.1 | 25717 |
| 2 | 48.2 | 11497 |
| 3 | 45.8 | 8680 |
| 4 | 65.7 | 69892 |
| 5 | 30.9 | 69303 |
| 6 | 67.1 | 68719 |
| 7 | 42.5 | 9535 |
| 8 | 57.1 | 81801 |
| 9 | 35.1 | 53506 |
| 10 | 28.2 | 14749 |
| 11 | 48.2 | 11497 |
| 12 | 65.7 | 69892 |
| 13 | 67.1 | 68719 |
+----+------+-------+
(13 rows)
↓ 本題の、重複データをウィンドウ関数で抽出する例です。調べる列を
with a as (
select *, count(*) over(partition by id, v1, v2)
from ex1_duplicated
)
select * from a
where count > 1
order by id;
+----+------+-------+-------+
| id | v1 | v2 | count |
+----+------+-------+-------+
| 2 | 48.2 | 11497 | 2 |
| 2 | 48.2 | 11497 | 2 |
| 4 | 65.7 | 69892 | 2 |
| 4 | 65.7 | 69892 | 2 |
| 6 | 67.1 | 68719 | 2 |
| 6 | 67.1 | 68719 | 2 |
+----+------+-------+-------+
(6 rows)
with a as (
select *, count(*) over(partition by id)
from ex2_duplicated
)
select * from a
where count > 1
order by id;
+----+------+-------+-------+
| id | v1 | v2 | count |
+----+------+-------+-------+
| 2 | 44.0 | 58432 | 2 |
| 2 | 40.3 | 21274 | 2 |
| 3 | 48.9 | 34272 | 2 |
| 3 | 74.3 | 91995 | 2 |
| 4 | 59.9 | 2754 | 4 |
| 4 | 64.9 | 47945 | 4 |
| 4 | 41.0 | 15123 | 4 |
| 4 | 29.7 | 51639 | 4 |
| 8 | 44.9 | 46623 | 4 |
| 8 | 71.9 | 46514 | 4 |
| 8 | 35.3 | 98214 | 4 |
| 8 | 67.3 | 3839 | 4 |
+----+------+-------+-------+
(12 rows)
with a as (
select *, count(*) over(partition by v1)
from ex3_duplicated
)
select * from a
where count > 1
order by v1;
+----+------+-------+-------+
| id | v1 | v2 | count |
+----+------+-------+-------+
| 2 | 48.2 | 11497 | 2 |
| 11 | 48.2 | 11497 | 2 |
| 12 | 65.7 | 69892 | 2 |
| 4 | 65.7 | 69892 | 2 |
| 13 | 67.1 | 68719 | 2 |
| 6 | 67.1 | 68719 | 2 |
+----+------+-------+-------+
(6 rows)
最後の
全列が重複していた
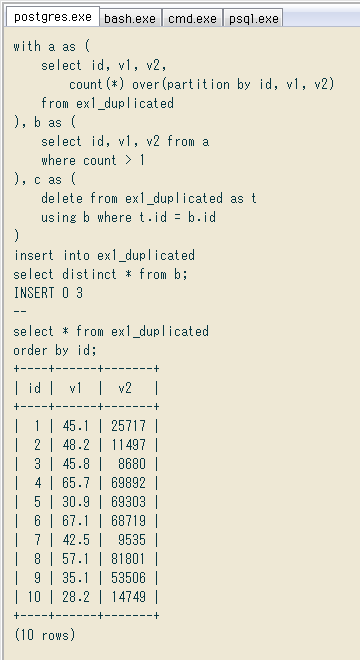
with a as (
select id, v1, v2,
count(*) over(partition by id, v1, v2)
from ex1_duplicated
), b as (
select id, v1, v2 from a
where count > 1
), c as (
delete from ex1_duplicated as t
using b where t.id = b.id
)
insert into ex1_duplicated
select distinct * from b;
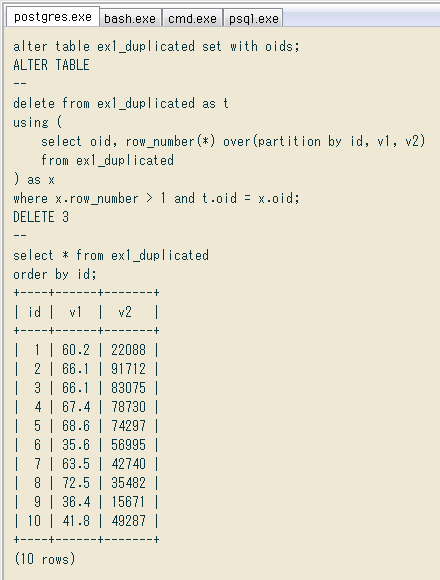
別の方法として、テーブル各行に固有の
alter table ex1_duplicated set with oids;
delete from ex1_duplicated as t
using (
select oid, row_number(*) over(partition by id, v1, v2)
from ex1_duplicated
) as x
where x.row_number > 1 and t.oid = x.oid;
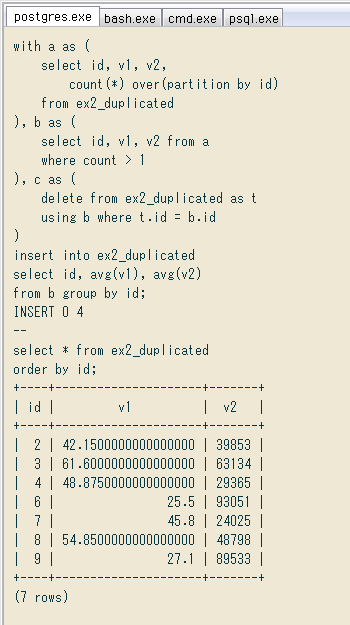
最後に、id
with a as (
select id, v1, v2,
count(*) over(partition by id)
from ex2_duplicated
), b as (
select id, v1, v2 from a
where count > 1
), c as (
delete from ex2_duplicated as t
using b where t.id = b.id
)
insert into ex2_duplicated
select id, avg(v1), avg(v2)
from b group by id;
ここでは平均を取り、列
ex1
alter table ex2_duplicated set with oids;
delete from ex2_duplicated as t
using (
select oid, row_number(*) over(partition by id)
from ex2_duplicated
) as x
where x.row_number > 1 and t.oid = x.oid;