文字コード問題で頻出の一つ、いわゆる「全角ハイフン、ダッシュ、マイナス記号」のトラブル。Shift JISにないハイフン等の種類がUnicodeに多く、それをSJISで表示・保存しようとする際に起きます。
DBの問題でなく普遍的な現象なので慌てなくて大丈夫。一般的なアプリでは文字化けになるところ、PostgreSQLが未然防止してるわけで。SJIS以外の文字コード(EUC-JP等)でも同様ですが、以下SJISで代表してエラー例と対策を書きます。確認に使ったサーバはWindowsネイティブの9.5.3。
現象を再現するためのテーブル作成
この全角ダッシュが混入するのは主に住所や固有名詞だと思いますが、そのサンプルテーブルを作るのは面倒なので、当該の1字だけのテーブルをクエリで ↓ 作成。バイトシーケンスをconvert_from関数に渡し、文字コードにUTF-8を指定してます。
# create table example_utf8_e28094 as
select convert_from('\xe28094', 'utf8');
クエリがASCIIのみだから、DBの文字コードがUTF-8ならクライアントの文字コードを問わず(Windowsコマンドプロンプト上のpsqlでも)実行できます。つまりデータとしては全く普通のもの。問題が起きるのは、以下のようにデータ表示や保存、またはその間にSJIS(など非UTF-8)を使うからです。
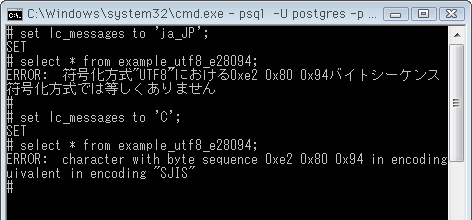
場面1 : Windowsコマンドプロンプト + psqlでデータを表示しようとした
日本語版Windowsのコマンドプロンプトの文字コードはSJIS(正確にはCP932)がデフォルト。psqlも起動時のクライアントエンコーディングがSJISになります。その状態で今回の全角ダッシュを表示しようとして起きるエラーが ↓ これ。日本語・英語両方のエラーメッセージを示しました。
# set lc_messages to 'ja_JP';
SET
# select * from example_utf8_e28094;
ERROR: 符号化方式"UTF8"における0xe2 0x80 0x94バイトシーケンス
を持つ文字は"SJIS"符号化方式では等しくありません
# set lc_messages to 'C';
SET
# select * from example_utf8_e28094;
ERROR: character with byte sequence 0xe2 0x80 0x94 in encoding
"UTF8" has no equivalent in encoding "SJIS"
エラーが出たら原因の特定が第一。今回のケースでは「SJISにない」と言われた文字の特定ですが、Windowsコマンドプロンプト+ psqlでUTF-8(というかユニコード)を表示するのは非常に面倒なので、しません(参考 : 6月24日の記事)。
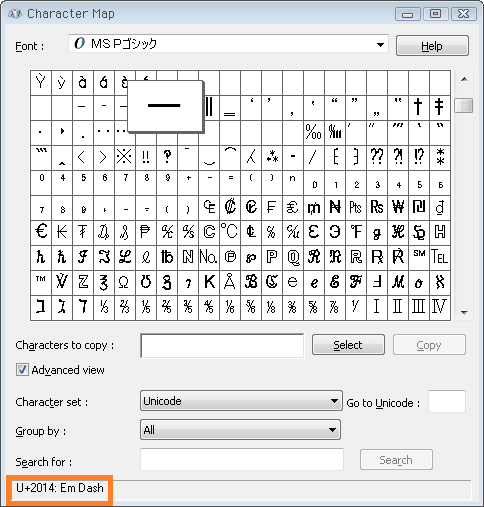
代わりにクエリでバイトシーケンスから16進コードポイントを出せば ↓ Windowsの文字コード表と照合できます。10進のコードポイントが必要ならto_hex関数を省略。
# select to_hex(
ascii(
convert_from('\xe28094', 'utf8')
)
);
+--------+
| to_hex |
+--------+
| 2014 |
+--------+
(1 row)
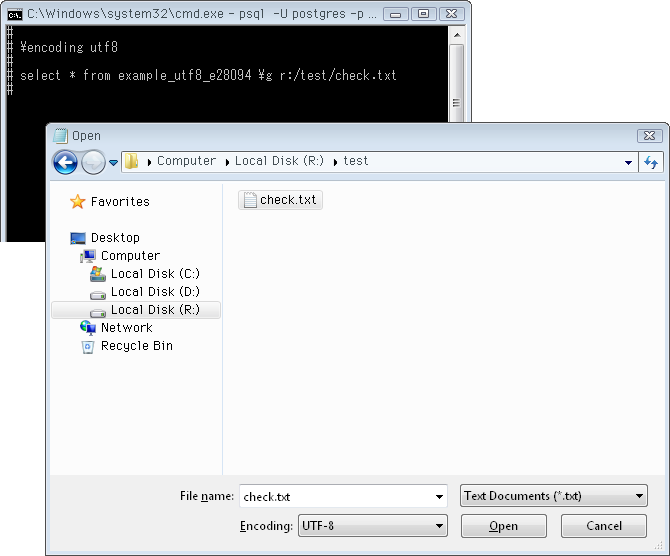
 別の方法。psqlのメタコマンド\gを使ってクエリ結果を適当なファイルに出力できるので ↓ このファイルをエディタで開き(文字コードはUTF-8)原因の文字を探せます。ただしデータが多い時は厳しいかも。
別の方法。psqlのメタコマンド\gを使ってクエリ結果を適当なファイルに出力できるので ↓ このファイルをエディタで開き(文字コードはUTF-8)原因の文字を探せます。ただしデータが多い時は厳しいかも。
# \encoding utf8
# select * from example_utf8_e28094 \g r:/test/check.txt
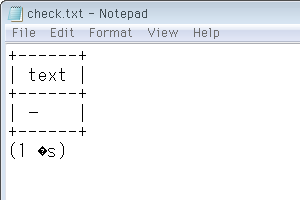 psqlが最後に付ける行数が文字化けしてますが、データとは関係ないので今日はスルー。次に対策を考えます。ともかくデータを表示できれば良いと仮定し、問題の字を「SJISにもある普通の横棒」に置換する方針で。
今回は、どんな文字コードでも使えるASCIIの半角ハイフンにします。replace関数を使い ↓ 置換元をバイトシーケンスから入力(最初のテーブル作成と同じ)、置換先は直接入力。実際のテーブルでは、問題の全角ダッシュ以外がそのまま表示されます。
psqlが最後に付ける行数が文字化けしてますが、データとは関係ないので今日はスルー。次に対策を考えます。ともかくデータを表示できれば良いと仮定し、問題の字を「SJISにもある普通の横棒」に置換する方針で。
今回は、どんな文字コードでも使えるASCIIの半角ハイフンにします。replace関数を使い ↓ 置換元をバイトシーケンスから入力(最初のテーブル作成と同じ)、置換先は直接入力。実際のテーブルでは、問題の全角ダッシュ以外がそのまま表示されます。
# select replace(text, convert_from('\xe28094', 'utf8'), '-')
from example_utf8_e28094;
+---------+
| replace |
+---------+
| - |
+---------+
(1 行)
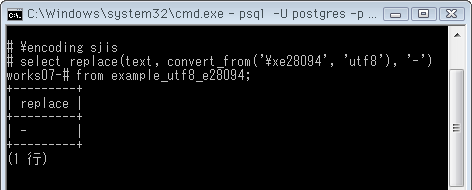 上の画像では、念のためクライアントエンコーディングをSJISに戻し、正常に実行できるのを確認しました。
今回に限らずUTF-8の字をSJISで表示できないエラーが出たら、このようにバイトシーケンス → convert_from関数 → replace関数で置換、が応急的なエラー回避。抜本対策は、データの持ち方に応じて後で検討すれば良いと思います。
上の画像では、念のためクライアントエンコーディングをSJISに戻し、正常に実行できるのを確認しました。
今回に限らずUTF-8の字をSJISで表示できないエラーが出たら、このようにバイトシーケンス → convert_from関数 → replace関数で置換、が応急的なエラー回避。抜本対策は、データの持ち方に応じて後で検討すれば良いと思います。
場面2 : COPYコマンドでShift JISファイルに出力しようとした
今度は、UTF-8を普通に使えるコンソールを想定。表示は普通にできるのに、COPYコマンドでSJISにファイル出力しようとして ↓ エラーになるケースです。
# \encoding utf8
# select * from example_utf8_e28094;
+------+
| text |
+------+
| — |
+------+
(1 row)
# copy example_utf8_e28094
to 'r:/test/output.txt' (encoding 'sjis');
ERROR: 符号化方式"UTF8"における0xe2 0x80 0x94バイトシーケンス
を持つ文字は"SJIS"符号化方式では等しくありません
あえてUTF-8より文字種の少ないSJISにしてるので当然の現象ですが、人から「SJISでデータをくれ」とか言われて出くわしたら疲れそう (-_-; 対策は先ほどと同様 ↓ SJISにある字に置換するクエリを書き、COPY文に入れればOK。
# copy (
select replace(text, convert_from('\xe28094', 'utf8'), '-')
from example_utf8_e28094
) to 'r:/test/output.txt' (encoding 'sjis');
COPY 1
 もし「全角のままでくれ」と言われたら ↓ これとか。正確にはダッシュ記号じゃないけど(Windows7の文字コード表はFullwidth Hyphen-Minusと表記)。
もし「全角のままでくれ」と言われたら ↓ これとか。正確にはダッシュ記号じゃないけど(Windows7の文字コード表はFullwidth Hyphen-Minusと表記)。
# copy (
select replace(text, convert_from('\xe28094', 'utf8'),
convert_from('\x817c', 'sjis'))
from example_utf8_e28094
) to 'r:/test/output2.txt' (encoding 'sjis');
COPY 1
このようにconvert_from関数は、いろんな文字コードのバイトシーケンスを直接入れることが可能。しかもクエリがASCIIだけで済むので、重宝します。