GROUP BY GROUPING SETS ((os, browser), os, ())
||
GROUP BY ROLLUP (os, browser)
GROUP BY GROUPING SETS ((os, browser), os, browser, ())
||
GROUP BY CUBE (os, browser)
GROUP BY ROLLUP (columnA, columnB, columnC)
||
GROUP BY GROUPING SETS ((columnA, columnB, columnC),
(columnA, columnB),
columnA, ())
||
片方向に(ツリー状に)絞っていく組み合せによる集計
---
GROUP BY CUBE (columnA, columnB, columnC)
||
GROUP BY GROUPING SETS ((columnA, columnB, columnC),
(columnA, columnB),
(columnA, columnC),
(columnB, columnC),
columnA, columnB, columnC, ())
||
各列で絞る or 絞らないの、全ての組み合わせによる集計

 上の2クエリで ↑ このJSONが ↓ こんなテーブルになる
上の2クエリで ↑ このJSONが ↓ こんなテーブルになる
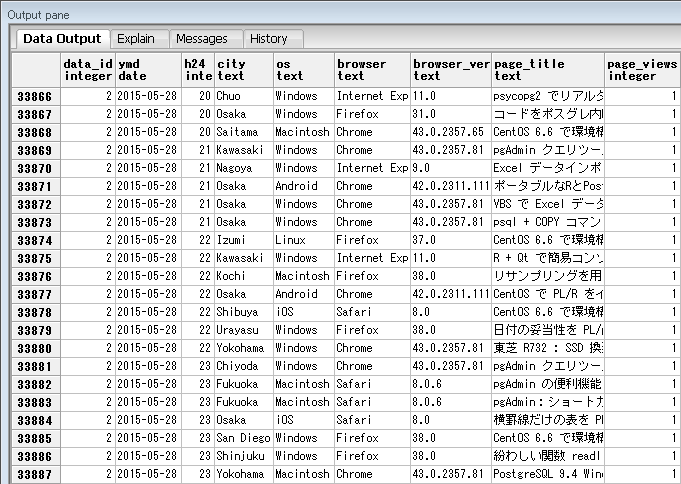 ここから本題で、上のテーブルを使ってPostgreSQL 9.5の新しいGROUP BYの説明。テーブルにある列のうち、主にOSとブラウザでの集計を例にしました。まず下は、普通のGROUP BYを使ってOS別・ブラウザ別のページビューを集計するクエリとその結果。
下が、9.5で追加される予定の一つGROUP BY GROUPING SETS (列名, 列名, …)という構文の簡単な例です。括孤内にOSとブラウザの列名を指定すると、先ほどの「OS別・ブラウザ別」でなく、OSとブラウザを別々に集計し、列をずらして縦にUNIONした結果に。例えば1行目「Android, , 1036」は、ブラウザを問わずAndroidからの全ページビューを意味しています。いわばGROUP BYを「列ごとの集計行に変える」感じ。
同じ結果を普通のGROUP BYでやると、下のように結構大変です。WITH句を使ってテーブル指定、HAVING、ORDERを1回で済ますこともできますが、やりたくない…。
先ほどのGROUPING SETSの括孤内に( )という謎の要素を追加すると、どの列でも絞り込まない「総計行」を足す結果に。下のようにOS別・ブラウザ別という小計(部分計)と総計を、一回のクエリで得られます。
普通のGROUP BYに、総計行だけ足すことも割と簡単。GROUPING SETSの括孤内を微妙に変えます。上では(os, browser, ( ))、下では((os, browser), ( ))。OSとブラウザを括孤でくくって一体の組み合わせだよ~と明示することで、普通のGROUP BY os, browser と同じことになり、これに( )を加えて総計行を追加。
このようにGROUPING SETSの括孤内を適当にいじっていると使い方が少しずつ分かると思います。下は3つの集計を一度に行う例で、①OSとブラウザ別の集計、②OS別の小計、③総計という3種類の値を一回でゲット。3種類の区別は、OSとブラウザの列がNULLかどうかを見れば分かるので、とりあえず結果をテーブル等に保存しておき、後から総計行だけ取り出すとかも簡単です。
ここまでGROUPING SETSだけ使ってきましたが、上の例はROLLUPを使って次のように短く書けます。
ここから本題で、上のテーブルを使ってPostgreSQL 9.5の新しいGROUP BYの説明。テーブルにある列のうち、主にOSとブラウザでの集計を例にしました。まず下は、普通のGROUP BYを使ってOS別・ブラウザ別のページビューを集計するクエリとその結果。
下が、9.5で追加される予定の一つGROUP BY GROUPING SETS (列名, 列名, …)という構文の簡単な例です。括孤内にOSとブラウザの列名を指定すると、先ほどの「OS別・ブラウザ別」でなく、OSとブラウザを別々に集計し、列をずらして縦にUNIONした結果に。例えば1行目「Android, , 1036」は、ブラウザを問わずAndroidからの全ページビューを意味しています。いわばGROUP BYを「列ごとの集計行に変える」感じ。
同じ結果を普通のGROUP BYでやると、下のように結構大変です。WITH句を使ってテーブル指定、HAVING、ORDERを1回で済ますこともできますが、やりたくない…。
先ほどのGROUPING SETSの括孤内に( )という謎の要素を追加すると、どの列でも絞り込まない「総計行」を足す結果に。下のようにOS別・ブラウザ別という小計(部分計)と総計を、一回のクエリで得られます。
普通のGROUP BYに、総計行だけ足すことも割と簡単。GROUPING SETSの括孤内を微妙に変えます。上では(os, browser, ( ))、下では((os, browser), ( ))。OSとブラウザを括孤でくくって一体の組み合わせだよ~と明示することで、普通のGROUP BY os, browser と同じことになり、これに( )を加えて総計行を追加。
このようにGROUPING SETSの括孤内を適当にいじっていると使い方が少しずつ分かると思います。下は3つの集計を一度に行う例で、①OSとブラウザ別の集計、②OS別の小計、③総計という3種類の値を一回でゲット。3種類の区別は、OSとブラウザの列がNULLかどうかを見れば分かるので、とりあえず結果をテーブル等に保存しておき、後から総計行だけ取り出すとかも簡単です。
ここまでGROUPING SETSだけ使ってきましたが、上の例はROLLUPを使って次のように短く書けます。