昨日Excelから変換したXMLを、PostgreSQLに読み込んで操作する準備編。Windows7ではシンボリックリンクを割と簡単に作れるようになったので、それとPostgreSQLの汎用ファイルアクセス関数の一つpg_read_fileを組み合わせます。最後にxpathを使う一例として、テキストノードや属性値で簡単な検索。
Contents
実行環境
- Windows7 32bit
- PostgreSQL Portable 9.4.1
- クエリの実行にはpgAdmin 1.20を使用。
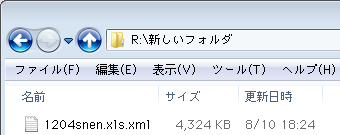
- サンプルにしたXMLは、昨日Excelファイルから作成したもの。今日は「R:/新しいフォルダ」の下に一つだけ置いて使いました。
Windows7でのシンボリックリンク作成
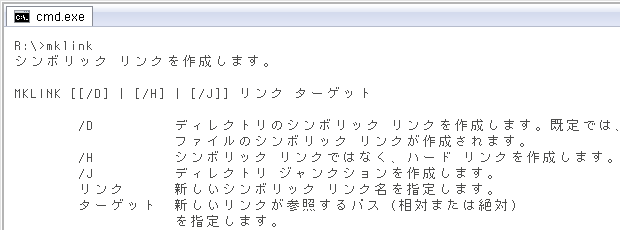
XPの頃は標準機能でなく面倒だったけど、Win7からMKLINKコマンド一つで簡単になりました。パラメータは下記のとおり。(コマンドによる表示のコピペ)
MKLINK [[/D] | [/H] | [/J]] リンク ターゲット
/D ディレクトリのシンボリック リンクを作成します。既定では、
ファイルのシンボリック リンクが作成されます。
/H シンボリック リンクではなく、ハード リンクを作成します。
/J ディレクトリ ジャンクションを作成します。
リンク 新しいシンボリック リンク名を指定します。
ターゲット 新しいリンクが参照するパス (相対または絶対)
を指定します。
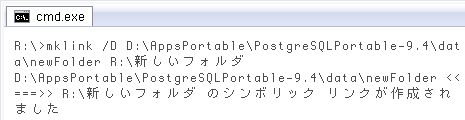
今回は、XMLファイルを置いたディレクトリへのシンボリックリンクを、PostgreSQLのデータディレクトリ直下に作ります。こうするとPostgreSQLの汎用ファイルアクセス関数を使ってXMLにアクセス可能(ただしPostgreSQLのスーパーユーザのみ)。mklinkコマンドは ↓ こんな感じ。
mklink /D [PostgreSQLのデータディレクトリ]\[シンボリックリンク名] [XMLを置いたディレクトリ]
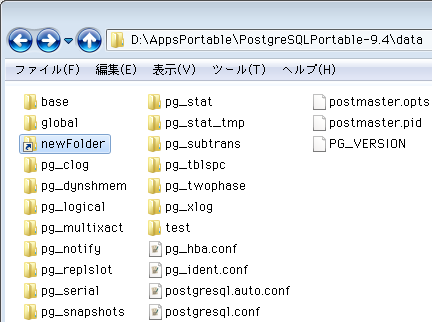
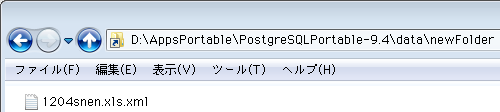
コマンド実行後にPostgreSQLのデータディレクトリをExplorerで開くと、ショートカットと同じアイコンでシンボリックリンクが追加されているはず。ショートカットとの違いは、クリックして開けば分かります。リンク先の中身が表示されつつ、アドレスはシンボリックリンクの場所のままだから(二つ目の画像)。
リンク先のパスに日本語があっても、シンボリックリンク名を英数字のみで作ればPostgreSQLからアクセスできて便利。既存のディレクトリ構成そのままで、必要な場所だけPostgreSQLで活用できます。
XMLをpg_read_file関数で読み込み
汎用ファイルアクセス関数の詳細は、PostgreSQL 9.4日本語ドキュメントの当該ページ(システム管理関数の中の一項)を参照。以下、簡単な使用例です。
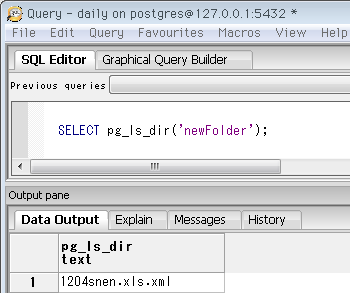
まずpg_ls_dirは、引数で指定したディレクトリ内の一覧。ファイルかサブディレクトリが複数あれば複数行が返ります。引数はPostgreSQLデータディレクトリからの相対パス(他の関数も同様)。先ほど作ったシンボリックリンクを指定すると ↓ こんな風にXMLファイル一つが出ます。
SELECT pg_ls_dir('newFolder');
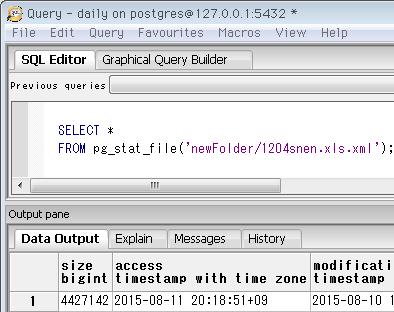
次にpg_stat_fileは、引数で指定したファイルのサイズ、更新日時などを複合型で返します。下は、今回のXMLファイルを指定した結果。
SELECT * FROM pg_stat_file('newFolder/1204snen.xls.xml');
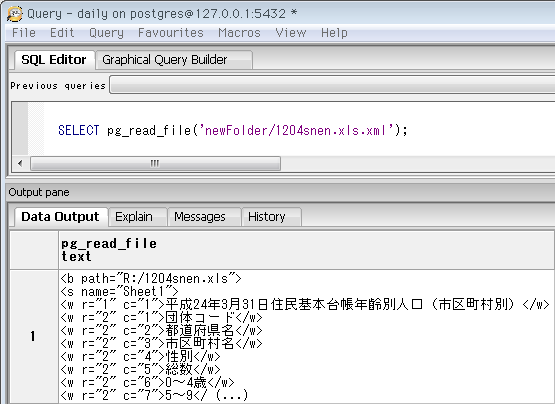
三つ目が、今日メインで使うpg_read_file。テキストファイルを読み込み、一つの文字列として返します。前提として「ファイルの文字コード=データベースの文字コード」。そうでない場合エラーになりますが、別の方法としてバイナリ読み込み用のpg_read_binary_fileと文字コード変換を組み合わせればOK(詳細はドキュメント内の例を参照)。下が、用意したXMLファイルを読み込んだところ。
SELECT pg_read_file('newFolder/1204snen.xls.xml');
↓pg_read_file関数の戻り値を、そのままXMLにキャストできます。結果は上と同じなので省略。
SELECT pg_read_file('newFolder/1204snen.xls.xml') :: xml;
以上が、ローカルのXMLファイルをシンボリックリンク経由でPostgreSQLに読み込むまでのひな型。結果が一つながりの文字列なので扱いやすいです。実用ではテーブルに保存して使うのが常ですが、次項では簡単に、このpg_read_fileの戻り値をXMLにキャストしそのままxpath関数に渡してみます。
xpath関数の簡単な例
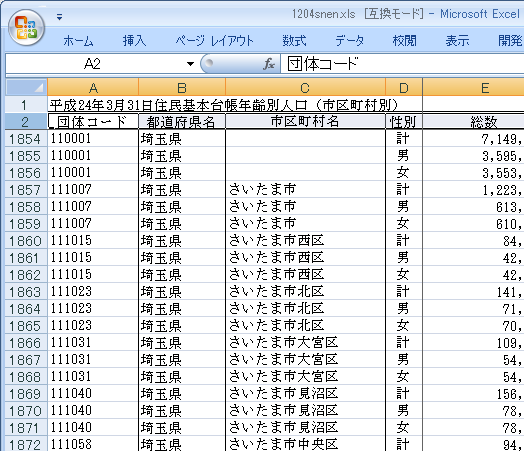
今日のXMLの元は、下のExcelファイルを1セルごとに<w r="行番号" c="列番号">セルの中身</w>という形式で要素化し束ねたもの。行・列の位置は属性値、セル内容はテキストノード。このXMLから、xpath関数で必要箇所を抽出する簡単な例をやってみます。
最初はセルのデータ(XMLのテキストノード)に対する検索。下記サイトに例があり、要素名[.="検索値"] というxpath式でできると知りました。
» 一行入魂 XPathでテキストノードの検索
クエリ例は ↓ こんな感じ。セル内容が「さいたま市」に一致する要素を検索する場合です。前項で書いたとおりpg_read_fileでXMLを読み込み、XMLにキャストしてxpath関数に渡す。この戻り値は常に配列型なので、unnest関数で一行ずつにバラします。
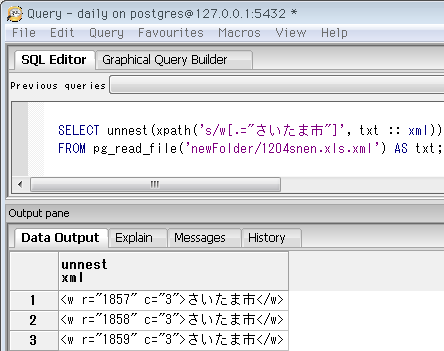
SELECT unnest(xpath('s/w[.="さいたま市"]', txt :: xml))
FROM pg_read_file('newFolder/1204snen.xls.xml') AS txt;
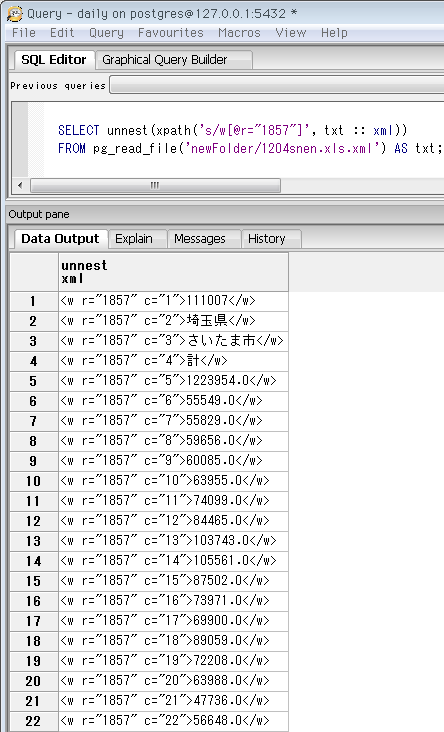
さいたま市のセルが3つあったので、とりあえず先頭のセルの行番号を使って、この行のデータを見ることにします。Excel上で言えば横にスクロールする感じ。行番号は要素のr属性で分かり、上の先頭セルは1857。これと同じ要素を検索するxpath式は、要素名[@r="検索値"]。
SELECT unnest(xpath('s/w[@r="1857"]', txt :: xml))
FROM pg_read_file('newFolder/1204snen.xls.xml') AS txt;
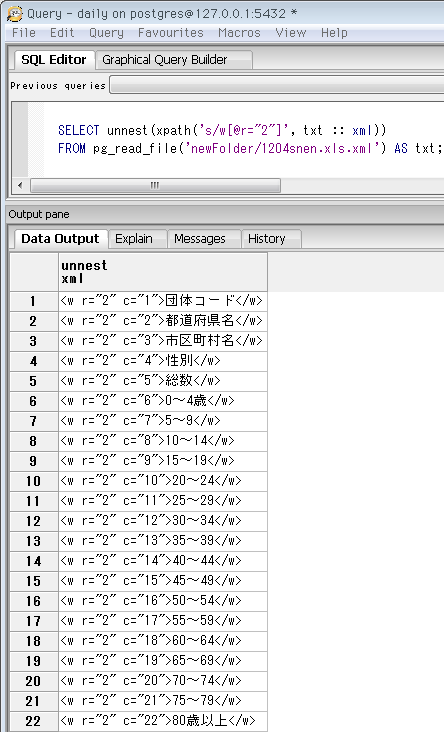
ずらずらっとセルの情報が出てきました。上から4つ目のセル(テキストノード)に「計」とあり、他の2行はこの内訳だった模様。他のセルの数値内容も知るため、表の行見出し部分を抽出してみます。本当は元のExcelを開く方が早いですが。行番号の先頭の方で検索すると ↓2行目にありました。
SELECT unnest(xpath('s/w[@r="2"]', txt :: xml))
FROM pg_read_file('newFolder/1204snen.xls.xml') AS txt;
この行見出しを使って、先ほど抽出した行別データの意味が分かります。上から4つ目が「性別」とあるので、先ほどの「計」は男女計の意味だった等。また行・列とも番号で区別されるため、Excelのアルファベットの列名を考える必要なし。昔はこの列名⇔列番号の相互変換が面倒でした。
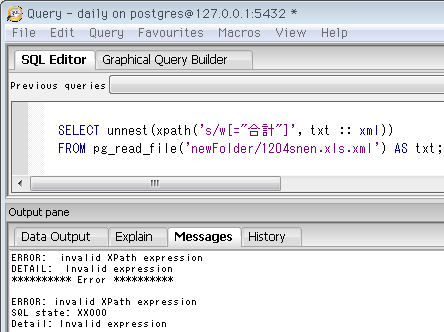
なおxpathの式を間違えるとエラーが出ますが ↓SQLと違い具体的な問題箇所は指摘されません。
ERROR: invalid XPath expression
今回の検索はごく簡単な例で、これだけならExcelを開いてコピペする方がいいけど、シートのあちこちに散らばっているデータを抽出するとか(実際いま、全国のいくつかの市町村について作業中)、同じ形式の複数のファイルに対して共通の処理をするなどの場合、今回の方法は結構使えます。
ただXML形式はいかんせん処理が遅く、データ量が多いと実用が厳しい時も。やっぱり今後はJSON(B)かなぁと思いつつ、Excelでありがちな「セル内改行」とか引用符とかイレギュラーなデータ(地雷)の扱いに頭が痛いという、自分の中では過渡期です。