Contents
ファイル構成、ソース、XML
前のブログで作った時と同じで、Python» Qgis - Download SW e progetti prototipali
QGIS 2.6.1
↓ バッチファイルのソース。前は引数一つだけの想定で、それを
@echo off %~d0 cd %~p0 cd QGIS/bin set PYTHONHOME=../apps/Python27 set PYTHONPATH=../apps/Python27/Lib set PATH=%PYTHONHOME% setlocal enableextensions :repeat set /a count=%count%+1 python "../../python_script/excel2xml_rev.py" "%1" if "%~2"=="" goto end shift goto repeat :end endlocal pause
↓
import os
import sys
import win32com.client
import codecs
fln = sys.argv[1].replace(os.path.sep, '/')
xml = fln + '.xml'
eao = win32com.client.Dispatch('Excel.Application')
eao.Visible = False
eao.DisplayAlerts = False
dic = []
wbo = eao.Workbooks.Open(fln)
for i in range(0, wbo.WorkSheets.Count) :
wso = wbo.WorkSheets(i + 1)
usr = wso.UsedRange
tags = []
for j in wso.Comments :
t = j.Text()
if not t : continue
tag = ['<comment r="', str(j.Parent.Row), '"']
tag.extend([' c="', str(j.Parent.Column), '">'])
tag.extend([t, '</comment>'])
tags.append(''.s.join(tag))
tmp = {'wsname' : wso.Name}
tmp['r_top'] = usr.Row
tmp['c_top'] = usr.Column
tmp['data'] = usr.Value
if tmp['data'] is None : continue
if len(tags) > 0 : tmp['comm'] = crf.join(tags)
dic.append(tmp)
if i == wbo.WorkSheets.Count : break
wbo.Close()
eao.Quit()
tags = [unicode('<b path="' + fln + '">')]
for w in dic :
tags.append(unicode('<s name="' + w['wsname'] + '">'))
if 'comm' in w : tags.append(w['comm'])
nrow = w['r_top']
for r in w['data'] :
ncol = w['c_top']
for c in r :
if c is not None :
tag = ['<w r="', str(nrow), '"']
tag.extend([' c="', str(ncol), '">'])
tag.extend([unicode(c), '</w>'])
tags.append(''.join(tag))
ncol = ncol + 1
nrow = nrow + 1
tags.append('</s>')
tags.append('</b>')
output = '\n'.join(tags)
f = codecs.open(xml, 'w', 'utf8') # change from 'sjis'
f.write(output)
f.close
出力される
<w r="行番号" c="列番号">データ</w>という単純な要素の集合になります。これをシートごと、さらにブック(ファイル)ごとにツリー化するのが基本。あとコメントは別のツリーになります。この
実行例(動画)
動画形式は実行例(説明)
今回使った» 政府統計の総合窓口
↓ ファイルはこんな感じで日本語がいっぱい。また年齢階級を表すのに全角チルダ「~」が使われてます。これがあると
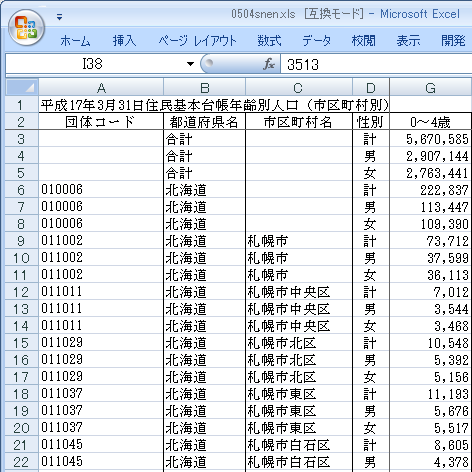
Excel
普通はコマンドプロンプト(DOS
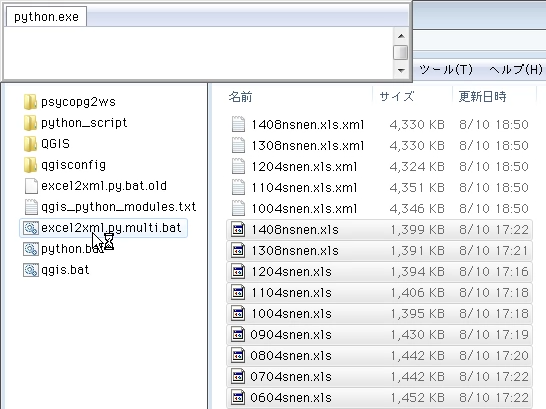
バッチの最後に
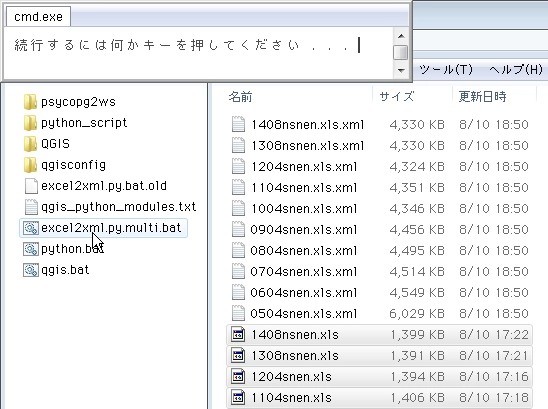
元の

画像の下の方を見ると、数値が
制約・注意点
記事の中に書いた点も含め、まとめておきます。- PC
に Excelがインストールされている前提。それを Python が起動して操作する。 - Excel
ファイルのパスに日本語や半角空白があると駄目。(未対応) - パスが深いファイルを一度に大量に渡すと、コマンドラインの最大長?のような制約を受けて失敗するかもしれない。(未調査)
- 出力される
XML は「行番号・列番号・セルの中身」の集合で、すぐ使えるデータ形式ではない。 - 整数だったセルが「xxxx.0」と小数点以下
1 桁の形式に変わってしまう。 - 当たり前だけど
Excel ファイルのデータだけ取得し、書式設定やグラフ等は無視する。
こんな感じで一般的な手段ではないと思うけど、自分としては