Contents
- 実行環境、ドキュメントの関連ページ
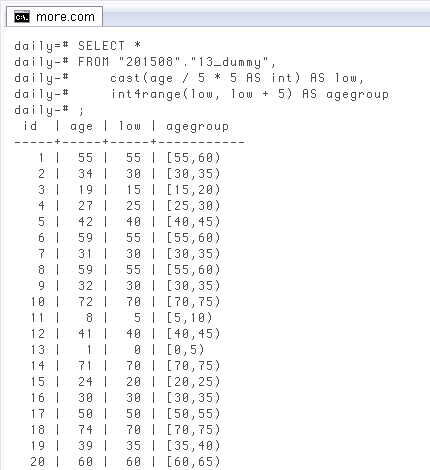
- ダミーテーブル作成
- 年齢の列を○歳ごとに階級区分
- 20
歳未満は一括、など例外がある場合(ここまで昨日)
- ドキュメントの関連ページ(追加)、参考リンク
- 範囲型のセットを作る(a)ベタ書き
- 範囲型のセットを作る(b)境界値を指定
- 範囲型のセットを作る(c)年齢階級の最初、区分幅、最後を指定
- 範囲型のセットを作る(d)基本は年齢階級、ただし例外あり
- (3)範囲型のセットをテーブルに、他(2015.8.15)
ドキュメントの関連ページ(追加)、参考リンク
今日の途中から少し使う範囲型のセットを作る(a)ベタ書き
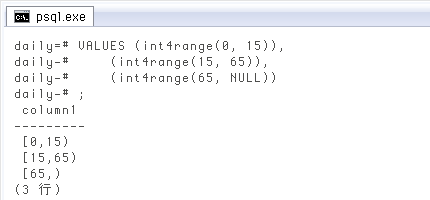
今日のクエリは、テーブルまたはビューに入れる中身だけ記します。実際使う時は、各クエリの前にまず範囲型一つずつベタ書きで定義し、縦に重ねる場合。階級区分が少ない時はこれで十分。上限を
VALUES (int4range(0, 15)),
(int4range(15, 65)),
(int4range(65, NULL));
column1
---------
[0,15)
[15,65)
[65,)
(3 行)
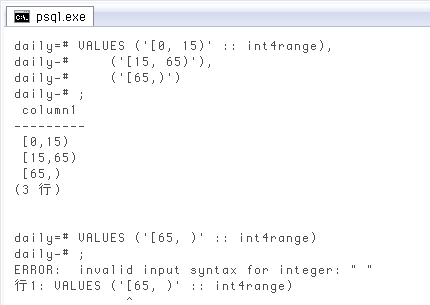
上はコンストラクタ関数を使用、下は文字列で定義してキャストする例。半角空白は少し注意が必要で、数値の前にあっても問題ありませんが「上限が
VALUES ('[0, 15)' :: int4range),
('[15, 65)'),
('[65,)');
column1
---------
[0,15)
[15,65)
[65,)
(3 行)
VALUES ('[65, )' :: int4range);
ERROR: invalid input syntax for integer: " "
行 1: VALUES ('[65, )' :: int4range)
^
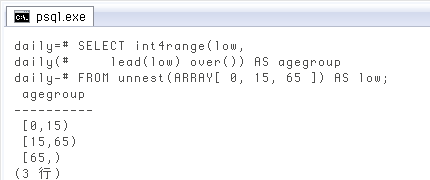
範囲型のセットを作る(b)境界値を指定
前項のようにベタ書きだと、同じ数値をだいたいSELECT int4range(low,
lead(low) over()) AS agegroup
FROM unnest(ARRAY[ 0, 15, 65 ]) AS low;
agegroup
----------
[0,15)
[15,65)
[65,)
(3 行)
ウィンドウ関数の
SELECT low, lead(low) over() AS up FROM unnest(ARRAY[ 0, 15, 65 ]) AS low;
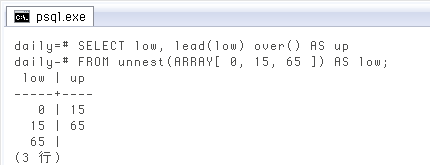
ウィンドウ関数を使う時、普通は行の並び順を指定しますが(over(ORDER BY ...)
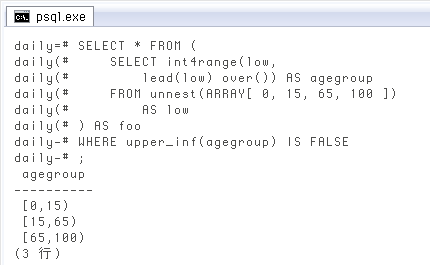
最後の範囲が自動的に「○歳以上」になって便利な一方、逆に「最後の範囲も○~○歳にする」場合はちょっと面倒。とりあえず「○歳以上」まで作っておいて最後に省く方法 ↓ を考えましたが、もっと良い方法があるかも。upper_inf
SELECT * FROM (
SELECT int4range(low,
lead(low) over()) AS agegroup
FROM unnest(ARRAY[ 0, 15, 65, 100 ])
AS low
) AS foo
WHERE upper_inf(agegroup) IS FALSE;
agegroup
----------
[0,15)
[15,65)
[65,100)
(3 行)
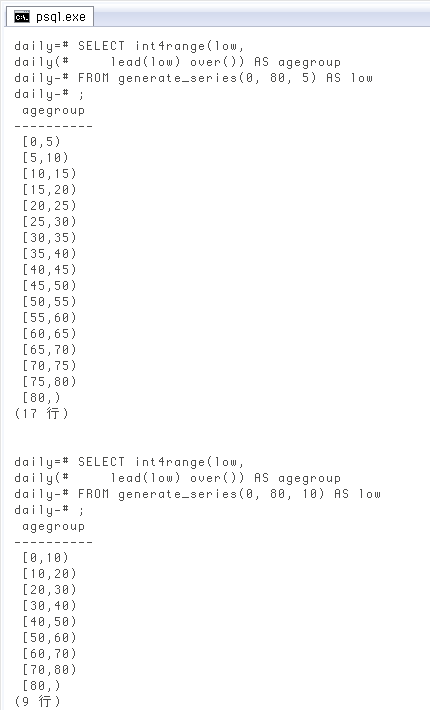
範囲型のセットを作る(c)年齢階級の最初、区分幅、最後を指定
前項までは階級区分が少ない時や、境界値に「○歳ずつ」などの規則性がない時に使う想定。次は「○歳ずつに区切る」場合です。例えば「5SELECT int4range(low,
lead(low) over()) AS agegroup
FROM generate_series(0, 80, 5) AS low;
agegroup
----------
[0,5)
[5,10)
[10,15)
[15,20)
[20,25)
[25,30)
[30,35)
[35,40)
[40,45)
[45,50)
[50,55)
[55,60)
[60,65)
[65,70)
[70,75)
[75,80)
[80,)
(17 行)
10
SELECT int4range(low,
lead(low) over()) AS agegroup
FROM generate_series(0, 80, 10) AS low;
agegroup
----------
[0,10)
[10,20)
[20,30)
[30,40)
[40,50)
[50,60)
[60,70)
[70,80)
[80,)
(9 行)
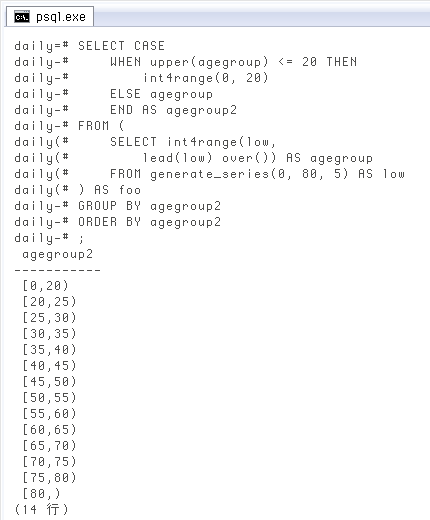
範囲型のセットを作る(d)基本は年齢階級、ただし例外あり
ここから、昨日ネックになってた例外ありの場合。どうしてもクエリが複雑になるので、生の年齢の列を変換する中で行うより、別のテーブルかビューで範囲型のセットだけ作ることにします。例えば「基本は
SELECT CASE
WHEN upper(agegroup) <= 20 THEN
int4range(0, 20)
ELSE agegroup
END AS agegroup2
FROM (
SELECT int4range(low,
lead(low) over()) AS agegroup
FROM generate_series(0, 80, 5) AS low
) AS foo
GROUP BY agegroup2
ORDER BY agegroup2;
agegroup2
-----------
[0,20) -- #
[20,25)
[25,30)
[30,35)
[35,40)
[40,45)
[45,50)
[50,55)
[55,60)
[60,65)
[65,70)
[70,75)
[75,80)
[80,)
(14 行)
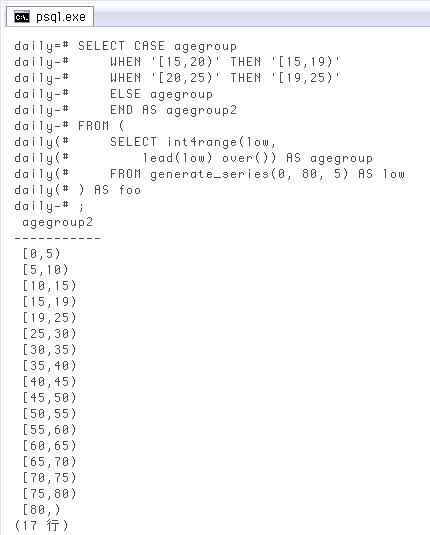
最後に、昨日頭が痛かった「5
SELECT CASE agegroup
WHEN '[15,20)' THEN '[15,19)'
WHEN '[20,25)' THEN '[19,25)'
ELSE agegroup
END AS agegroup2
FROM (
SELECT int4range(low,
lead(low) over()) AS agegroup
FROM generate_series(0, 80, 5) AS low
) AS foo;
agegroup2
-----------
[0,5)
[5,10)
[10,15)
[15,19) -- #
[19,25) -- #
[25,30)
[30,35)
[35,40)
[40,45)
[45,50)
[50,55)
[55,60)
[60,65)
[65,70)
[70,75)
[75,80)
[80,)
(17 行)
これでだいたい、年齢階級を範囲型のセットにするひな型にできそう。明日は、これらのセットをテーブルかビューにして、生の年齢の列があるテーブルと結合する予定。
あと、上のように例外を処理したりすると、うっかりクエリを間違えて「重なり」や「抜け」ができかねません。結果として、ある年齢が「複数の範囲に入る」または「どの範囲にも入らない」という事態になって困るので、そのチェックについても明日考えます。