Contents
- 実行環境、ドキュメントの関連ページ
- ダミーテーブル作成
- 年齢の列を○歳ごとに階級区分
- 20
歳未満は一括、など例外がある場合(ここまで2015.8.13)
- ドキュメントの関連ページ(追加)、参考リンク
- 範囲型のセットを作る(a)ベタ書き
- 範囲型のセットを作る(b)境界値を指定
- 範囲型のセットを作る(c)年齢階級の最初、区分幅、最後を指定
- 範囲型のセットを作る(d)基本は年齢階級、ただし例外あり(ここまで2015.8.14)
- 範囲型のセットをテーブルにする
- 普通の値のテーブルと結合
- 範囲型セットのチェック(1)重複がないか
- 範囲型セットのチェック(2)抜けがないか
- 範囲型セットの抜けを埋めるクエリ
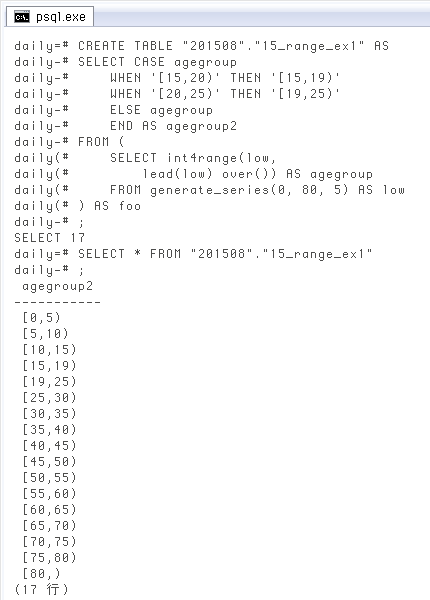
範囲型のセットをテーブルにする
昨日の最後に、例外を含むCREATE TABLE "201508"."15_range_ex1" AS
SELECT CASE agegroup
WHEN '[15,20)' THEN '[15,19)'
WHEN '[20,25)' THEN '[19,25)'
ELSE agegroup
END AS agegroup2
FROM (
SELECT int4range(low, lead(low) over()) AS agegroup
FROM generate_series(0, 80, 5) AS low
) AS foo;
SELECT * FROM "201508"."15_range_ex1";
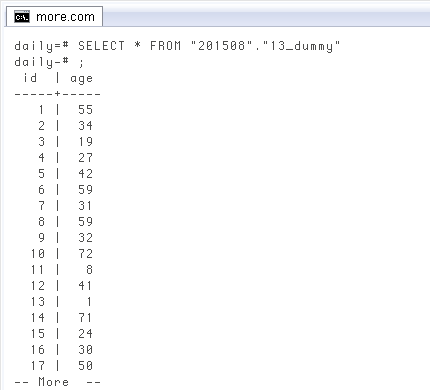
普通の値のテーブルと結合
普通の値(ここでは年齢)があるテーブルは、一昨日の最初に作ったこれ ↓ を使います。列SELECT * FROM "201508"."13_dummy";
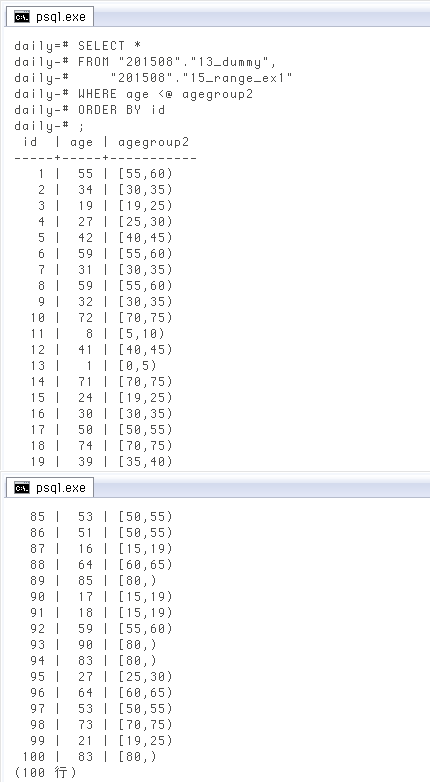
これと、前項で作った範囲型セットのテーブルを並べ「年齢が範囲型に包含される」行だけ抽出すれば ↓ 実質的に「年齢に対応する範囲型の列を足す」のと同じになります。範囲型の包含は
SELECT * FROM "201508"."13_dummy", "201508"."15_range_ex1" WHERE age <@ agegroup2 ORDER BY id; id | age | agegroup2 -----+-----+----------- 1 | 55 | [55,60) 2 | 34 | [30,35) 3 | 19 | [19,25) 4 | 27 | [25,30) 5 | 42 | [40,45) 6 | 59 | [55,60) 7 | 31 | [30,35) 8 | 59 | [55,60) 9 | 32 | [30,35) 10 | 72 | [70,75) 11 | 8 | [5,10) 12 | 41 | [40,45) 13 | 1 | [0,5) 14 | 71 | [70,75) 15 | 24 | [19,25) -- More --
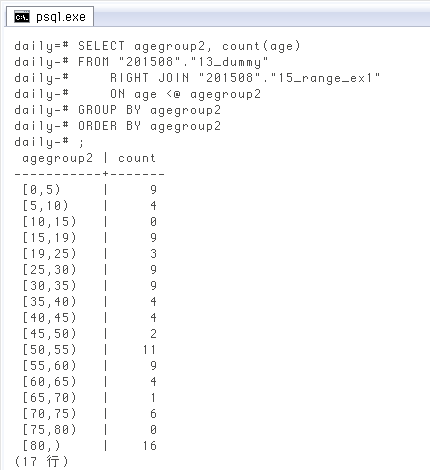
ただし上のクエリでは、対応する年齢が一つもない範囲は「初めから存在しない」と同じ。上のクエリ結果を範囲別に集計すると ↓ こうなって、[10,15)
SELECT agegroup2, count(*) FROM "201508"."13_dummy", "201508"."15_range_ex1" WHERE age <@ agegroup2 GROUP BY agegroup2 ORDER BY agegroup2; agegroup2 | count -----------+------- [0,5) | 9 [5,10) | 4 -- # [15,19) | 9 -- # [19,25) | 3 [25,30) | 9 [30,35) | 9 [35,40) | 4 [40,45) | 4 [45,50) | 2 [50,55) | 11 [55,60) | 9 [60,65) | 4 [65,70) | 1 [70,75) | 6 -- # [80,) | 16 -- # (15 行)
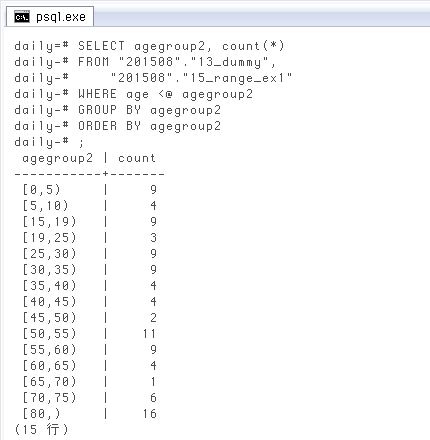
そこで、範囲型の行は全て出るように
SELECT agegroup2, count(age)
FROM "201508"."13_dummy"
RIGHT JOIN "201508"."15_range_ex1"
ON age <@ agegroup2
GROUP BY agegroup2
ORDER BY agegroup2;
agegroup2 | count
-----------+-------
[0,5) | 9
[5,10) | 4
[10,15) | 0 -- #
[15,19) | 9
[19,25) | 3
[25,30) | 9
[30,35) | 9
[35,40) | 4
[40,45) | 4
[45,50) | 2
[50,55) | 11
[55,60) | 9
[60,65) | 4
[65,70) | 1
[70,75) | 6
[75,80) | 0 -- #
[80,) | 16
(17 行)
範囲型セットのチェック(1)重複がないか
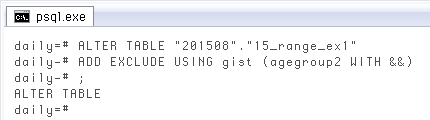
前項のように既存のデータと範囲型セットを結合する際、範囲型セットにおかしな点があると結果もおかしくなるので事前のチェックが重要。逆に言えば、適切だと確認された範囲型セットがあれば、安心して様々なテーブルと結合できます。範囲型セットをチェックする代表例として「重複」の有無があり、テーブルの列に対する排他制約として定式化されてます。下が、今回の年齢階級別範囲型の列に排他制約を付加するクエリ。簡単に言えば「agegroup2
ALTER TABLE "201508"."15_range_ex1" ADD EXCLUDE USING gist (agegroup2 WITH &&);
上の排他制約を追加後、試しに他と重なる範囲を追加しようとすると ↓ エラーになり、自動的なチェックがしっかり効いていると分かります。
INSERT INTO "201508"."15_range_ex1" (agegroup2)
VALUES ('[20, 25)');
ERROR: conflicting key value violates exclusion
constraint "15_range_ex1_agegroup2_excl"
DETAIL: Key (agegroup2)=([20,25)) conflicts
with existing key (agegroup2)=([19,25)).

範囲型セットのチェック(2)抜けがないか
重なりと違って少し面倒な、でももう一つ重要なチェックが「抜け」の有無、つまり範囲と範囲の間が飛んでいないこと。これと重複なしを合わせて初めて「全ての値が一つの範囲に対応する」と保証されます(あと範囲の両端の有限・無限もあるけど、別の問題)。抜けの有無は全行を調べないと分からない、要するに集約的な処理が必要なので、現在の
SELECT *, agegroup2 -|- lead AS neighbor
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo;
agegroup2 | lead | neighbor
-----------+---------+----------
[0,5) | [5,10) | t
[5,10) | [10,15) | t
[10,15) | [15,19) | t
[15,19) | [19,25) | t
[19,25) | [25,30) | t
[25,30) | [30,35) | t
[30,35) | [35,40) | t
[35,40) | [40,45) | t
[40,45) | [45,50) | t
[45,50) | [50,55) | t
[50,55) | [55,60) | t
[55,60) | [60,65) | t
[60,65) | [65,70) | t
[65,70) | [70,75) | t
[70,75) | [75,80) | t
[75,80) | [80,) | t
[80,) | |
(17 行)
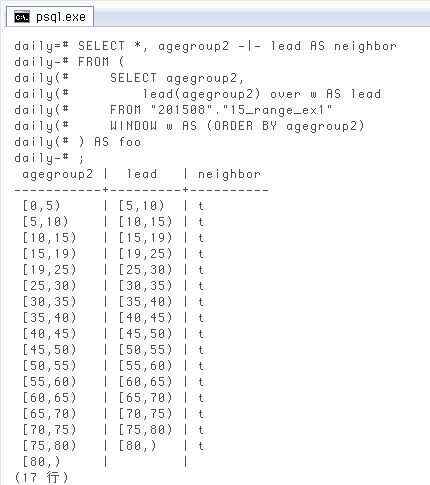
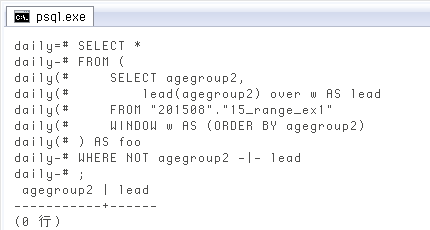
上のように全行の結果を出さずとも、WHERE
SELECT *
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo
WHERE NOT agegroup2 -|- lead;
agegroup2 | lead
-----------+------
(0 行)
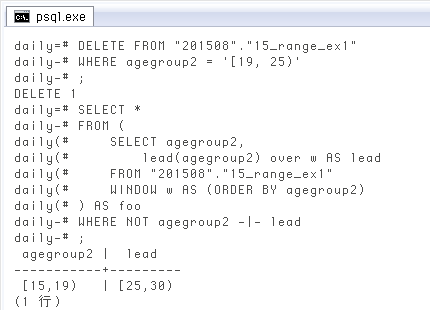
上のクエリの動作確認で、試しに途中の範囲を一つ抜いてみます。↓
DELETE FROM "201508"."15_range_ex1" WHERE agegroup2 = '[19, 25)';
先ほどのクエリを実行すると ↓ 確かに抜けが抽出されました。
SELECT *
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo
WHERE NOT agegroup2 -|- lead;
agegroup2 | lead
-----------+---------
[15,19) | [25,30)
(1 行)
範囲型セットの抜けを埋めるクエリ
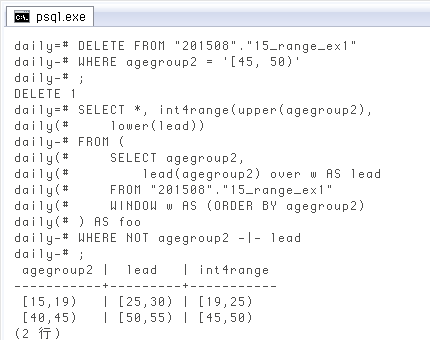
前項をもう一歩進め、抜けがあったら自動的に新しい範囲で埋めることを考えます。テスト用にもう一つ範囲を削除して ↓ 抜けの部分を増やしました。DELETE FROM "201508"."15_range_ex1" WHERE agegroup2 = '[45, 50)';
前項で作った抜け抽出クエリには前と後の範囲が表示されているので、その上限・下限から新しい範囲を作って埋めることにします。↓ とりあえず新しい範囲を作ってみたところ。
SELECT *, int4range(upper(agegroup2), lower(lead))
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo
WHERE NOT agegroup2 -|- lead;
agegroup2 | lead | int4range
-----------+---------+-----------
[15,19) | [25,30) | [19,25)
[40,45) | [50,55) | [45,50)
(2 行)
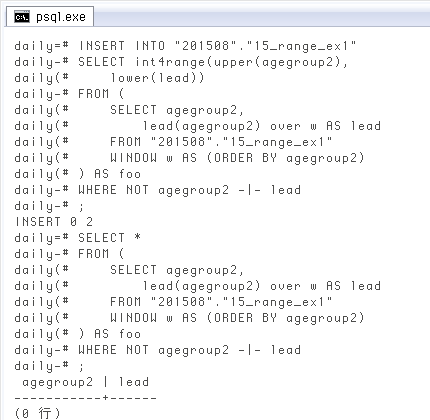
上で作った新しい範囲を、そのまま
INSERT INTO "201508"."15_range_ex1"
SELECT int4range(upper(agegroup2), lower(lead))
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo
WHERE NOT agegroup2 -|- lead;
↓ これで一応、抜けは解消しました。ただ、機械的に抜けを一つの範囲で埋めるので、元々の「5
SELECT *
FROM (
SELECT agegroup2, lead(agegroup2) over w AS lead
FROM "201508"."15_range_ex1"
WINDOW w AS (ORDER BY agegroup2)
) AS foo
WHERE NOT agegroup2 -|- lead;
agegroup2 | lead
-----------+------
(0 行)
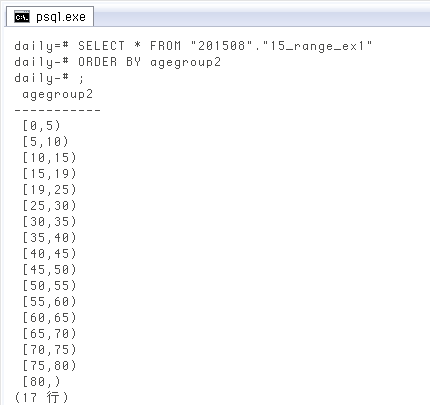
↓ 一応確認で、抜けを埋めた後。最初と同じです。
SELECT * FROM "201508"."15_range_ex1" ORDER BY agegroup2; agegroup2 ----------- [0,5) [5,10) [10,15) [15,19) [19,25) [25,30) [30,35) [35,40) [40,45) [45,50) [50,55) [55,60) [60,65) [65,70) [70,75) [75,80) [80,) (17 行)
「抜け」のチェックは、範囲型に限らず整数型の
PostgreSQL
自分もまだ一部の関数・演算子しか使っていませんが、今回の年齢階級のように統計データを扱う時は何かと便利なので、この機会に少しまとめてみました。