Contents
- 今日やること、実行環境、ドキュメントの関連ページ
- ダミーテーブル作成
- 年齢の列を○歳ごとに階級区分
- 20
歳未満は一括、など例外がある場合
- (2)範囲型のセットを作る(2015.8.14)
- (3)範囲型のセットをテーブルに、他(2015.8.15)
今日やること、実行環境、ドキュメントの関連ページ
階級別になってる統計データは置いといて、まず手元の集計前データの年齢(生の値が入力されている)を範囲型に変換するひな形を作ります。実行環境は下記の
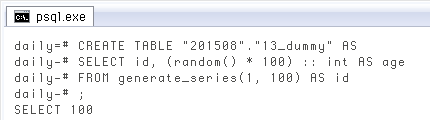
ダミーテーブル作成
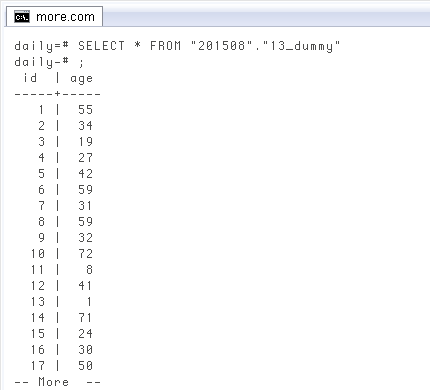
IDCREATE TABLE "201508"."13_dummy" AS SELECT id, (random() * 100) :: int AS age FROM generate_series(1, 100) AS id; SELECT * FROM "201508"."13_dummy"; -- Check id | age -----+----- 1 | 55 2 | 34 3 | 19 4 | 27 5 | 42 6 | 59 7 | 31 8 | 59 9 | 32 10 | 72 11 | 8 12 | 41 13 | 1 14 | 71 15 | 24 -- More --
年齢の列を○歳ごとに階級区分
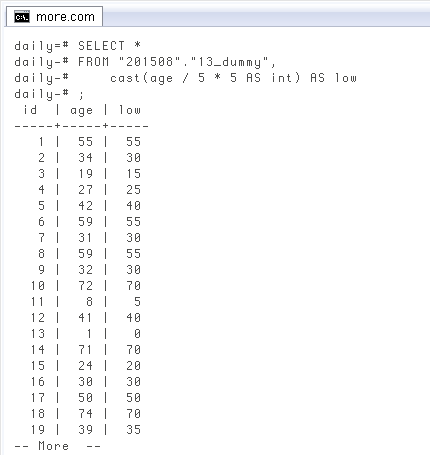
ここから本題。まずSELECT *
FROM "201508"."13_dummy",
cast(age / 5 * 5 AS int) AS low;
id | age | low
-----+-----+-----
1 | 55 | 55
2 | 34 | 30
3 | 19 | 15
4 | 27 | 25
5 | 42 | 40
6 | 59 | 55
7 | 31 | 30
8 | 59 | 55
9 | 32 | 30
10 | 72 | 70
11 | 8 | 5
12 | 41 | 40
13 | 1 | 0
14 | 71 | 70
15 | 24 | 20
-- More --
下限に今回の幅(5
SELECT *
FROM "201508"."13_dummy",
cast(age / 5 * 5 AS int) AS low,
int4range(low, low + 5) AS agegroup;
id | age | low | agegroup
-----+-----+-----+-----------
1 | 55 | 55 | [55,60)
2 | 34 | 30 | [30,35)
3 | 19 | 15 | [15,20)
4 | 27 | 25 | [25,30)
5 | 42 | 40 | [40,45)
6 | 59 | 55 | [55,60)
7 | 31 | 30 | [30,35)
8 | 59 | 55 | [55,60)
9 | 32 | 30 | [30,35)
10 | 72 | 70 | [70,75)
11 | 8 | 5 | [5,10)
12 | 41 | 40 | [40,45)
13 | 1 | 0 | [0,5)
14 | 71 | 70 | [70,75)
15 | 24 | 20 | [20,25)
-- More --
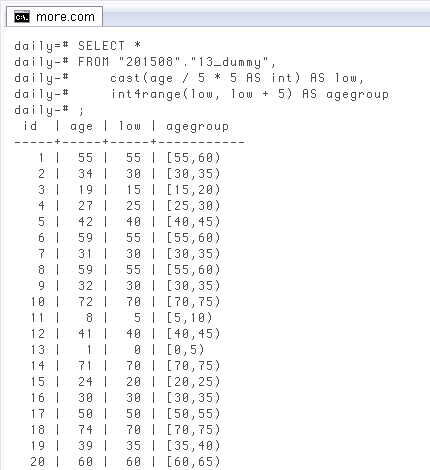
上のクエリは
SELECT *
FROM "201508"."13_dummy",
cast(5 AS int) AS n,
cast(age / n * n AS int) AS low,
int4range(low, low + n) AS agegroup;
id | age | n | low | agegroup
-----+-----+---+-----+-----------
1 | 55 | 5 | 55 | [55,60)
2 | 34 | 5 | 30 | [30,35)
3 | 19 | 5 | 15 | [15,20)
4 | 27 | 5 | 25 | [25,30)
5 | 42 | 5 | 40 | [40,45)
6 | 59 | 5 | 55 | [55,60)
7 | 31 | 5 | 30 | [30,35)
8 | 59 | 5 | 55 | [55,60)
9 | 32 | 5 | 30 | [30,35)
10 | 72 | 5 | 70 | [70,75)
11 | 8 | 5 | 5 | [5,10)
12 | 41 | 5 | 40 | [40,45)
13 | 1 | 5 | 0 | [0,5)
14 | 71 | 5 | 70 | [70,75)
15 | 24 | 5 | 20 | [20,25)
-- More --
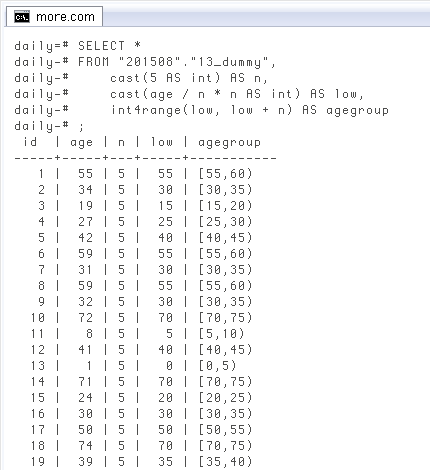
例えば上のクエリの「5」を「10」に変えるだけで ↓
SELECT *
FROM "201508"."13_dummy",
cast(10 AS int) AS n,
cast(age / n * n AS int) AS low,
int4range(low, low + n) AS agegroup;
id | age | n | low | agegroup
-----+-----+----+-----+-----------
1 | 55 | 10 | 50 | [50,60)
2 | 34 | 10 | 30 | [30,40)
3 | 19 | 10 | 10 | [10,20)
4 | 27 | 10 | 20 | [20,30)
5 | 42 | 10 | 40 | [40,50)
6 | 59 | 10 | 50 | [50,60)
7 | 31 | 10 | 30 | [30,40)
8 | 59 | 10 | 50 | [50,60)
9 | 32 | 10 | 30 | [30,40)
10 | 72 | 10 | 70 | [70,80)
11 | 8 | 10 | 0 | [0,10)
12 | 41 | 10 | 40 | [40,50)
13 | 1 | 10 | 0 | [0,10)
14 | 71 | 10 | 70 | [70,80)
15 | 24 | 10 | 20 | [20,30)
-- More --
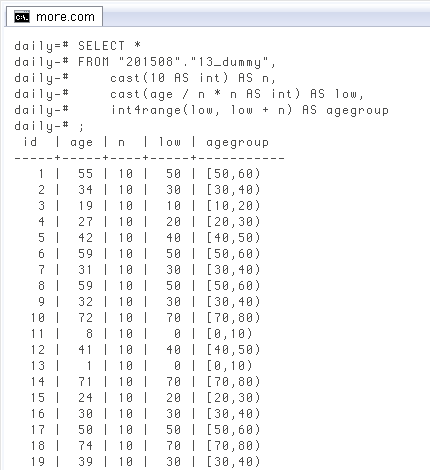
「20
基本は前項で尽きていますが、「結合先の階級別データでは○歳未満が一括されてる」など年齢階級に例外がある場合に備えます。実際多いんですよ日本の統計では…。下は「10
SELECT *
FROM "201508"."13_dummy",
cast(10 AS int) AS n,
cast(CASE WHEN age < 20 THEN 0
ELSE age / n * n END AS int) AS low,
cast(CASE WHEN age < 20 THEN 20
ELSE low + n END AS int) AS up,
int4range(low, up) AS agegroup;
id | age | n | low | up | agegroup
-----+-----+----+-----+-----+-----------
1 | 55 | 10 | 50 | 60 | [50,60)
2 | 34 | 10 | 30 | 40 | [30,40)
3 | 19 | 10 | 0 | 20 | [0,20) -- #
4 | 27 | 10 | 20 | 30 | [20,30)
5 | 42 | 10 | 40 | 50 | [40,50)
6 | 59 | 10 | 50 | 60 | [50,60)
7 | 31 | 10 | 30 | 40 | [30,40)
8 | 59 | 10 | 50 | 60 | [50,60)
9 | 32 | 10 | 30 | 40 | [30,40)
10 | 72 | 10 | 70 | 80 | [70,80)
11 | 8 | 10 | 0 | 20 | [0,20) -- #
12 | 41 | 10 | 40 | 50 | [40,50)
13 | 1 | 10 | 0 | 20 | [0,20) -- #
14 | 71 | 10 | 70 | 80 | [70,80)
15 | 24 | 10 | 20 | 30 | [20,30)
-- More --
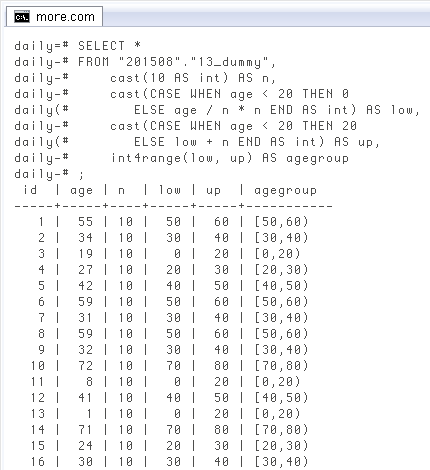
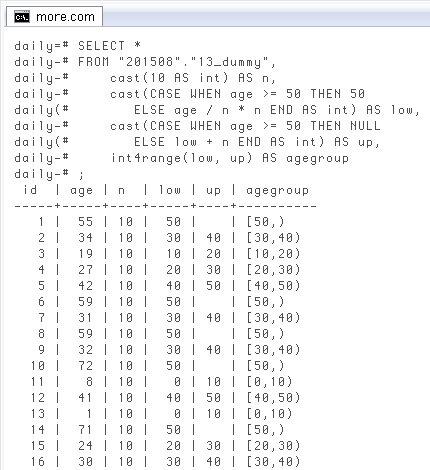
もう一つ、例外の中でほぼ必ずある「○歳以上は一括」という場合。上と違って上限がありません。こういう時に
下は「50
SELECT *
FROM "201508"."13_dummy",
cast(10 AS int) AS n,
cast(CASE WHEN age >= 50 THEN 50
ELSE age / n * n END AS int) AS low,
cast(CASE WHEN age >= 50 THEN NULL
ELSE low + n END AS int) AS up,
int4range(low, up) AS agegroup;
id | age | n | low | up | agegroup
-----+-----+----+-----+----+----------
1 | 55 | 10 | 50 | | [50,) -- #
2 | 34 | 10 | 30 | 40 | [30,40)
3 | 19 | 10 | 10 | 20 | [10,20)
4 | 27 | 10 | 20 | 30 | [20,30)
5 | 42 | 10 | 40 | 50 | [40,50)
6 | 59 | 10 | 50 | | [50,) -- #
7 | 31 | 10 | 30 | 40 | [30,40)
8 | 59 | 10 | 50 | | [50,) -- #
9 | 32 | 10 | 30 | 40 | [30,40)
10 | 72 | 10 | 50 | | [50,) -- #
11 | 8 | 10 | 0 | 10 | [0,10)
12 | 41 | 10 | 40 | 50 | [40,50)
13 | 1 | 10 | 0 | 10 | [0,10)
14 | 71 | 10 | 50 | | [50,) -- #
15 | 24 | 10 | 20 | 30 | [20,30)
-- More --
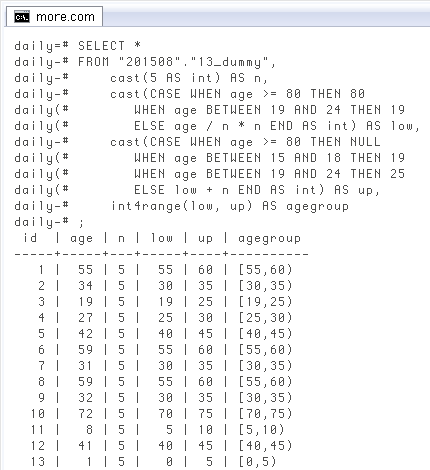
最後は、実際いま扱っている頭が痛い例。基本は
SELECT *
FROM "201508"."13_dummy",
cast(5 AS int) AS n,
cast(CASE WHEN age >= 80 THEN 80
WHEN age BETWEEN 19 AND 24 THEN 19
ELSE age / n * n END AS int) AS low,
cast(CASE WHEN age >= 80 THEN NULL
WHEN age BETWEEN 15 AND 18 THEN 19
WHEN age BETWEEN 19 AND 24 THEN 25
ELSE low + n END AS int) AS up,
int4range(low, up) AS agegroup;
id | age | n | low | up | agegroup
-----+-----+---+-----+----+----------
1 | 55 | 5 | 55 | 60 | [55,60)
2 | 34 | 5 | 30 | 35 | [30,35)
3 | 19 | 5 | 19 | 25 | [19,25) -- #
4 | 27 | 5 | 25 | 30 | [25,30)
5 | 42 | 5 | 40 | 45 | [40,45)
6 | 59 | 5 | 55 | 60 | [55,60)
7 | 31 | 5 | 30 | 35 | [30,35)
8 | 59 | 5 | 55 | 60 | [55,60)
9 | 32 | 5 | 30 | 35 | [30,35)
10 | 72 | 5 | 70 | 75 | [70,75)
11 | 8 | 5 | 5 | 10 | [5,10)
12 | 41 | 5 | 40 | 45 | [40,45)
13 | 1 | 5 | 0 | 5 | [0,5)
14 | 71 | 5 | 70 | 75 | [70,75)
15 | 24 | 5 | 19 | 25 | [19,25)
...
85 | 53 | 5 | 50 | 55 | [50,55)
86 | 51 | 5 | 50 | 55 | [50,55)
87 | 16 | 5 | 15 | 19 | [15,19) -- #
88 | 64 | 5 | 60 | 65 | [60,65)
89 | 85 | 5 | 80 | | [80,)
90 | 17 | 5 | 15 | 19 | [15,19) -- #
91 | 18 | 5 | 15 | 19 | [15,19) -- #
92 | 59 | 5 | 55 | 60 | [55,60)
93 | 90 | 5 | 80 | | [80,)
94 | 83 | 5 | 80 | | [80,)
95 | 27 | 5 | 25 | 30 | [25,30)
96 | 64 | 5 | 60 | 65 | [60,65)
97 | 53 | 5 | 50 | 55 | [50,55)
98 | 73 | 5 | 70 | 75 | [70,75)
99 | 21 | 5 | 19 | 25 | [19,25) -- #
100 | 83 | 5 | 80 | | [80,)
(100 行)
ここまで例外が多いと、先にビューで範囲型を定義して、生の年齢の列があるテーブルと結合した方が良さそう。他のテーブルにも使えるし。という訳で明日に続きます。