Seesaaで書いてた旧ブログ、全693記事のアーカイブ化の一環です。全文検索に使う部分の抽出・整理用に、まずHTMLを丸ごとPostgreSQLに取り込みました。
実行環境
• Windows7 x64 + Cygwin 2.5.1 + ConEmu 150813g
• Windows版PostgreSQL 9.5.3 + Cygwin版psql
• Windowsは管理者権限ユーザ、PostgreSQL接続はスーパーユーザ
使うファイル群と作業用DB
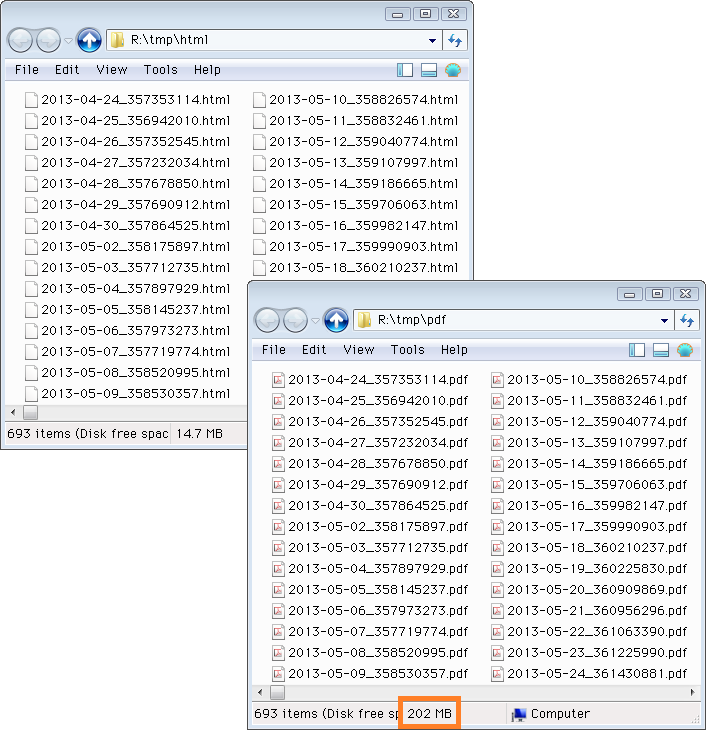
ファイル群は旧ブログ(Seesaa)の全693記事のHTMLファイル。前回、PerlスクリプトとcURLで自動取得・保存しました。↓ 左上のhtmlフォルダが保存先。
 DBは、8月18日に旧ブログの記事リストを作ったもの。その時はリストをTSV出力しましたが、今回はテーブル化して始めます。
↓ 8月18日にTSV出力したのと同様のクエリを、今度は先頭にcreate table ... as文を付けて実行するだけ。記事リストの元になるテキストデータ(旧ブログのindex-xx.htmlを全て連結したもの)は既にDBに入ってます。
DBは、8月18日に旧ブログの記事リストを作ったもの。その時はリストをTSV出力しましたが、今回はテーブル化して始めます。
↓ 8月18日にTSV出力したのと同様のクエリを、今度は先頭にcreate table ... as文を付けて実行するだけ。記事リストの元になるテキストデータ(旧ブログのindex-xx.htmlを全て連結したもの)は既にDBに入ってます。
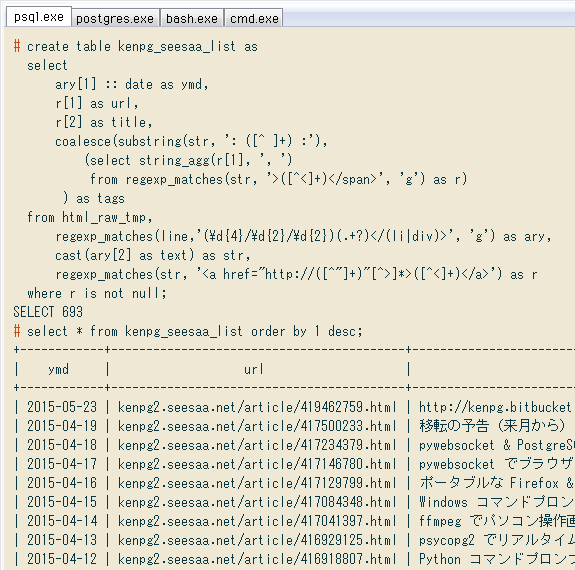
# create table kenpg_seesaa_list as
select
ary[1] :: date as ymd,
r[1] as url,
r[2] as title,
coalesce(substring(str, ': ([^ ]+) :'),
(select string_agg(r[1], ', ')
from regexp_matches(str, '>([^<]+)</span>', 'g') as r)
) as tags
from html_raw_tmp,
regexp_matches(line,'(\d{4}/\d{2}/\d{2})(.+?)</(li|div)>', 'g') as ary,
cast(ary[2] as text) as str,
regexp_matches(str, '<a href="http://([^"]+)"[^>]*>([^<]+)</a>') as r
where r is not null;
-- check result
# select * from kenpg_seesaa_list order by 1 desc;
+------------+------------------------------------------+-------------------------------------------------------------+----------------------------------+
| ymd | url | title | tag |
+------------+------------------------------------------+-------------------------------------------------------------+----------------------------------+
| 2015-05-23 | kenpg2.seesaa.net/article/419462759.html | http://kenpg.bitbucket.org/ に移転しました | info |
| 2015-04-19 | kenpg2.seesaa.net/article/417500233.html | 移転の予告(来月から) | info |
| 2015-04-18 | kenpg2.seesaa.net/article/417234379.html | pywebsocket & PostgreSQL の Web クライアント(暫定) | WebSocket, Python, PostgreSQL |
| 2015-04-17 | kenpg2.seesaa.net/article/417146780.html | pywebsocket でブラウザ ⇒ サーバに処理中止を指示(暫定) | WebSocket, Python |
| 2015-04-16 | kenpg2.seesaa.net/article/417129799.html | ポータブルな Firefox & Python で WebSocket 通信テスト | Python, Firefox, WebSocket |
...
(693 rows)
 重複やNULLがない確認として、各列に制約を付けます。
重複やNULLがない確認として、各列に制約を付けます。
# alter table kenpg_seesaa_list add primary key(ymd);
create unique index on kenpg_seesaa_list (url);
alter table kenpg_seesaa_list alter url set not null;
alter table kenpg_seesaa_list alter title set not null;
alter table kenpg_seesaa_list alter tags set not null;
テーブル各行と、これから取り込むHTMLファイルが対応してます。ファイル名が年月日とURL内の数字からなり、テーブルの列ymdとurlで一意に決まる形。HTMLを格納する準備として、ファイル名とコンテンツを入れる列を足します。
# alter table kenpg_seesaa_list add html_file text;
alter table kenpg_seesaa_list add html text;
↓ テーブル定義を表示して、ここまでの準備を確認。
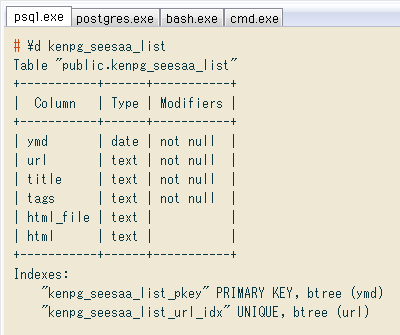
# \d kenpg_seesaa_list
Table "public.kenpg_seesaa_list"
+-----------+------+-----------+
| Column | Type | Modifiers |
+-----------+------+-----------+
| ymd | date | not null |
| url | text | not null |
| title | text | not null |
| tags | text | not null |
| html_file | text | |
| html | text | |
+-----------+------+-----------+
Indexes:
"kenpg_seesaa_list_pkey" PRIMARY KEY, btree (ymd)
"kenpg_seesaa_list_url_idx" UNIQUE, btree (url)
Cygwinシェルから「Windowsのシンボリックリンク」を作成
今回、過去記事で何回かやったのと同様、PostgreSQLのpg_read_file関数でHTMLファイルの中身を文字列としてテーブルに入れます。この関数がアクセスできるのはDBのデータフォルダ下のみですが、HTMLのある場所へのシンボリックリンクをデータフォルダに作れば大丈夫。
少し注意なのは、DBサーバがWindows版なので「シンボリックリンクをWindowsのMKLINKコマンドで作る」必要がある点。クライアントがCygwin版psqlだからと言ってlnコマンドを使うと、Windowsネイティブで機能しません。
今までは普通にWindowsのCMDシェルを開きMKLINKしてきましたが、今日はあえてCygwin版psqlから、シェルのコマンドでやってみました(ついでにPostgreSQLのデータフォルダを直接入力しない方法で)。
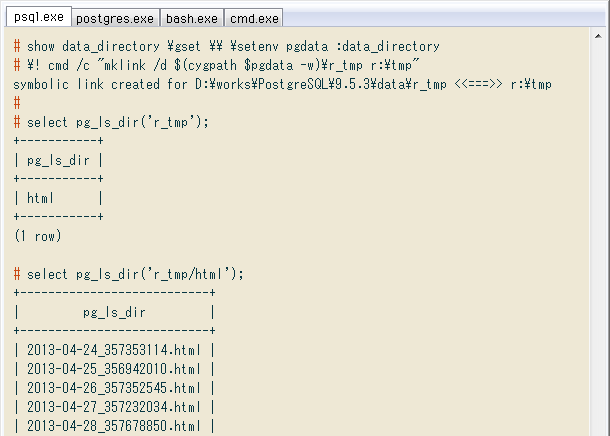
↓ 1行目でデータフォルダをシェルの環境変数pgdataに入れ、2行目でcygpathコマンドを介してMKLINKのパラメータを入力。これで、データフォルダのパスは入力せずWindowsのシンボリックリンクを張れました。
# show data_directory \gset \\ \setenv pgdata :data_directory
# \! cmd /c "mklink /d $(cygpath $pgdata -w)\r_tmp r:\tmp"
symbolic link created for D:\works\PostgreSQL\9.5.3\data\r_tmp <<===>> r:\tmp
↓ フォルダ内の一覧をpg_ls_dir関数で出すと、確かにHTMLのある場所にアクセス可能。これで準備終わり、次項でHTMLの中身を取り込みます。
# select pg_ls_dir('r_tmp');
+-----------+
| pg_ls_dir |
+-----------+
| html |
+-----------+
(1 row)
# select pg_ls_dir('r_tmp/html');
+---------------------------+
| pg_ls_dir |
+---------------------------+
| 2013-04-24_357353114.html |
| 2013-04-25_356942010.html |
| 2013-04-26_357352545.html |
| 2013-04-27_357232034.html |
| 2013-04-28_357678850.html |
...
(693 rows)
DBのテーブル内にHTMLファイル名を生成し、一括読み込み
前々項で書いたとおり、各HTMLファイル名は日付とURL内の数字から成ってます(前回cURLで取得した時、そういう命名規則で保存)。ファイル読み込みに当たり、まず同じファイル名をSQLで作成しテーブルに入れます。
↓ いきなりUPDATEせず、SELECT文で確認してから。日付型の出力形式は設定によって変わり得るので(参考:7月18日の記事)to_char関数で固定します。
# select ymd, url,
to_char(ymd, 'yyyy-mm-dd')
|| '_' || substring(url, '\d+\.html$')
from kenpg_seesaa_list;
+------------+------------------------------------------+---------------------------+
| ymd | url | ?column? |
+------------+------------------------------------------+---------------------------+
| 2014-09-16 | kenpg.seesaa.net/article/405510842.html | 2014-09-16_405510842.html |
| 2014-09-14 | kenpg.seesaa.net/article/405425703.html | 2014-09-14_405425703.html |
| 2014-09-13 | kenpg.seesaa.net/article/405374546.html | 2014-09-13_405374546.html |
| 2014-09-12 | kenpg.seesaa.net/article/405030672.html | 2014-09-12_405030672.html |
| 2014-09-11 | kenpg.seesaa.net/article/404550720.html | 2014-09-11_404550720.html |
...
(693 rows)
# update kenpg_seesaa_list
set html_file = to_char(ymd, 'yyyy-mm-dd')
|| '_' || substring(url, '\d+\.html$');
UPDATE 693
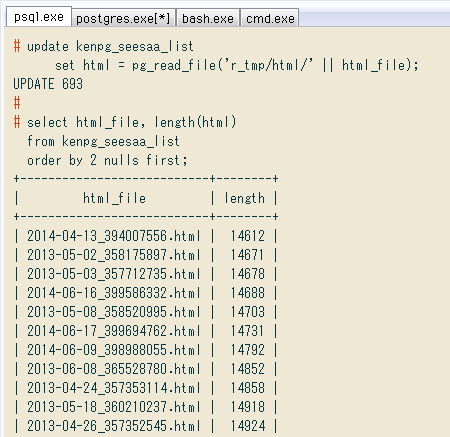
ファイル名がhtml_file列に入ったので、pg_read_file関数で読み込み、列htmlに入れます。これもいきなり実行せずSELECT文で確認してから。
↓ 確認例。ファイルコンテンツの長さが小さい順に出力します。想定外にファイル名が違って不存在とか、文字コードがUTF-8以外ならエラーが起き、ファイル取得時の問題で空とかサイズが極端に小さいのがあれば先頭に来るので分かります。
# select html_file,
length(pg_read_file('r_tmp/html/' || html_file))
from kenpg_seesaa_list
order by 2 nulls first;
+---------------------------+--------+
| html_file | length |
+---------------------------+--------+
| 2014-04-13_394007556.html | 14612 |
| 2013-05-02_358175897.html | 14671 |
| 2013-05-03_357712735.html | 14678 |
| 2014-06-16_399586332.html | 14688 |
| 2013-05-08_358520995.html | 14703 |
...
(693 rows)
↓ 問題なさそうなのでUPDATE、念のため結果を確認。これで693個のHTMLファイルの中身がテーブル各行に保存されました。
# update kenpg_seesaa_list
set html = pg_read_file('r_tmp/html/' || html_file);
UPDATE 693
# select html_file, length(html)
from kenpg_seesaa_list
order by 2 nulls first;
+---------------------------+--------+
| html_file | length |
+---------------------------+--------+
| 2014-04-13_394007556.html | 14612 |
| 2013-05-02_358175897.html | 14671 |
| 2013-05-03_357712735.html | 14678 |
| 2014-06-16_399586332.html | 14688 |
| 2013-05-08_358520995.html | 14703 |
...
(693 rows)
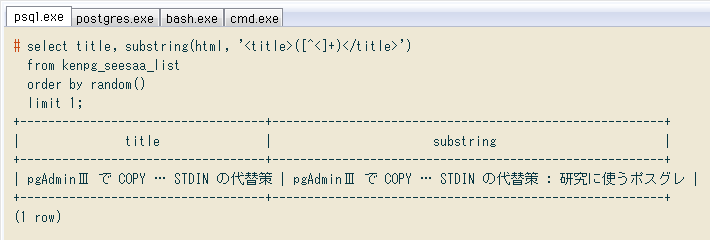
 ↓ ランダムに抽出してHTMLを見たり、記事タイトルが元のリスト(テーブルのtitle列)と合っているか確認したり。ローマ数字も問題なく入ってます。
↓ ランダムに抽出してHTMLを見たり、記事タイトルが元のリスト(テーブルのtitle列)と合っているか確認したり。ローマ数字も問題なく入ってます。
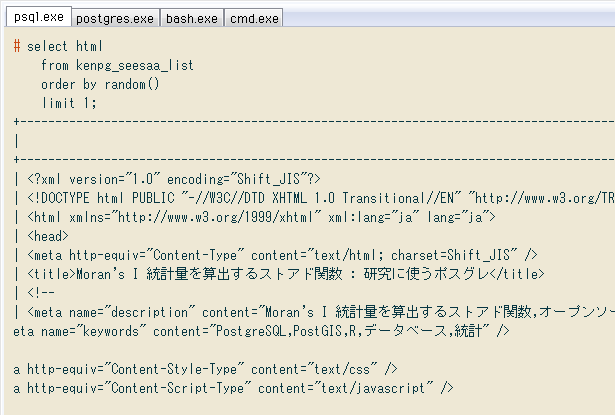
# select html
from kenpg_seesaa_list
order by random()
limit 1;
+---------------------------------------------------------------------------
|
+---------------------------------------------------------------------------
| <?xml version="1.0" encoding="Shift_JIS"?>
| <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www
| <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
| <head>
| <meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS" />
| <title>Moran's I 統計量を算出するストアド関数 : 研究に使うポスグレ</title>
...
# select title, substring(html, '<title>([^<]+)</title>')
from kenpg_seesaa_list
order by random()
limit 1;
+-----------------------------------+--------------------------------------------------------+
| title | substring |
+-----------------------------------+--------------------------------------------------------+
| pgAdminⅢ で COPY … STDIN の代替策 | pgAdminⅢ で COPY … STDIN の代替策 : 研究に使うポスグレ |
+-----------------------------------+--------------------------------------------------------+
(1 row)
 もうシンボリックリンクは不要なのでRMDIRコマンドで削除。DELだとリンク先の実体を消すので要注意。CMDシェル上で実行するのと違ってThe directory is not emptyとメッセージが出て、でもシンボリックリンクは普通に削除されてました。
もうシンボリックリンクは不要なのでRMDIRコマンドで削除。DELだとリンク先の実体を消すので要注意。CMDシェル上で実行するのと違ってThe directory is not emptyとメッセージが出て、でもシンボリックリンクは普通に削除されてました。
# \! cmd /c "rmdir $(cygpath $pgdata -w)\r_tmp r:\tmp"
The directory is not empty.
最後に念のため、投入した2列にNOT NULL制約を付加。あとテーブルサイズは7.5MBでした。元のHTML全部(約14MB)の半分くらい。
# alter table kenpg_seesaa_list alter html_file set not null;
alter table kenpg_seesaa_list alter html set not null;
# select pg_size_pretty(
pg_table_size(
to_regclass('kenpg_seesaa_list')
)
);
+----------------+
| pg_size_pretty |
+----------------+
| 7464 kB |
+----------------+
(1 row)
実行コマンドまとめ(全てpsql上)
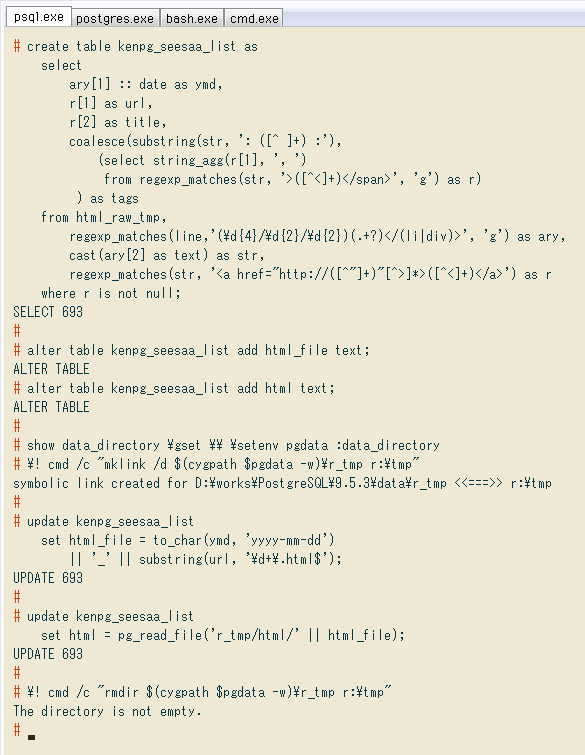
記事が長くなったのでまとめ。確認部分やテーブル制約は省いてます。2つのUPDATEを一文にできるかと思ったけど駄目でした(HTMLコンテンツが読み込まれず)。クエリの下に、この通り実際やり直した際の画像があります。
# create table kenpg_seesaa_list as
select
ary[1] :: date as ymd,
r[1] as url,
r[2] as title,
coalesce(substring(str, ': ([^ ]+) :'),
(select string_agg(r[1], ', ')
from regexp_matches(str, '>([^<]+)</span>', 'g') as r)
) as tags
from html_raw_tmp,
regexp_matches(line,'(\d{4}/\d{2}/\d{2})(.+?)</(li|div)>', 'g') as ary,
cast(ary[2] as text) as str,
regexp_matches(str, '<a href="http://([^"]+)"[^>]*>([^<]+)</a>') as r
where r is not null;
# alter table kenpg_seesaa_list add html_file text;
# alter table kenpg_seesaa_list add html text;
# show data_directory \gset \\ \setenv pgdata :data_directory
# \! cmd /c "mklink /d $(cygpath $pgdata -w)\r_tmp r:\tmp"
# update kenpg_seesaa_list
set html_file = to_char(ymd, 'yyyy-mm-dd')
|| '_' || substring(url, '\d+\.html$');
# update kenpg_seesaa_list
set html = pg_read_file('r_tmp/html/' || html_file);
# \! cmd /c "rmdir $(cygpath $pgdata -w)\r_tmp r:\tmp"
次は全文検索に使う部分の抽出
PostgreSQLにHTMLを取り込んだのは、旧ブログの記事全文検索に使う本文を抽出して整理するため。途中でリニューアルしてタグの構造が変わったし、ブログシステム側が付加する内容も時期等によって違う可能性があるので。正規表現を試行錯誤して抽出・確認を繰り返し、まとまったら記事にします。