前回に続き、旧ブログ(Seesaa)記事検索の準備中。PostgreSQLに取り込んだHTMLの切り出しに正規表現関数を使ってますが、マッチしなかった行の扱いがsubstring関数とregexp_matches関数で全然違うのを改めて認識しました。ついでに両関数の基本的な違いもメモ。使用バージョンは9.5.3です。
使うテーブル
前回の最後(実行コマンドまとめ)が終わった時点。↓ がテーブル定義で、列htmlに旧ブログ各記事のHTMLが丸ごと入ってます。DBの文字コードはUTF-8。
# \d kenpg_seesaa_list
Table "public.kenpg_seesaa_list"
+-----------+------+-----------+
| Column | Type | Modifiers |
+-----------+------+-----------+
| ymd | date | |
| url | text | |
| title | text | |
| tags | text | |
| html_file | text | |
| html | text | | <- contents
+-----------+------+-----------+
substring関数で、マッチなしの場合
今は知らないけど、自分が書いていた頃のSeesaaブログでは、記事に「追記」を入力すると<a name="more">~</a>内にセットされるようでした。この箇所に一つも入力されてなければHTML抽出時に省けるので、substring関数で調べると ↓
# select ymd, substring(html, '<a name="more">[^<]+</a>')
from kenpg_seesaa_list;
+------------+-----------+
| ymd | substring |
+------------+-----------+
| 2015-05-23 | |
| 2015-04-19 | |
| 2015-04-16 | |
| 2015-04-15 | |
| 2015-04-14 | |
...
マッチしなかった行はNULLが返ります。全体で一つもマッチしなかったか否かは、集約関数を使うか、ORDER BY substring NULLS LASTを足してチェックします(先頭にNULLが来てれば一つもマッチなし)。
なおドキュメントの表に載ってる構文はsubstring(column FROM pattern)ですが、上のようにsubstring(column, pattern)とも書けます。FROM ⇔ カンマが互換になっており、簡単のため今日は後者で。
HTMLだからタグが英大文字の場合も考慮が必要なところ、substring関数ではiオプションを付けたりできません。そこで次にregexp_matches関数を使ってみます。
regexp_matches関数で、マッチなしの場合
形式はregexp_matchs(column, pattern [, option])。実行すると ↓ このように1行も返らず。マッチした行だけが結果に出る仕様です。
# select ymd, regexp_matches(html, '<a name="more">[^<]+</a>', 'i')
from kenpg_seesaa_list;
+-----+----------------+
| ymd | regexp_matches |
+-----+----------------+
+-----+----------------+
(0 rows)
今回のようにマッチ有無だけ知りたければ、これで終わり。substringより簡単、かつオプションも使えるので勝手が良いです。
もし、いくつかの行にマッチした場合は ↓ こうなります。結果が常に配列で返り、部分マッチ(括弧内)があれば配列の各要素になる仕様です。
# select ymd, regexp_matches(html, 'regexp_matches .{10}', 'i')
from kenpg_seesaa_list;
+------------+-----------------------------------------+
| ymd | regexp_matches |
+------------+-----------------------------------------+
| 2015-01-16 | {"regexp_matches の結果が配列でなく複"} |
| 2014-07-03 | {"regexp_matches でファイル名、サイズ"} |
| 2014-07-02 | {"regexp_matches を使い、属性名と値の"} |
| 2014-01-06 | {"regexp_matches を使って次のように書"} |
| 2013-10-30 | {"regexp_matches で一度にマッチさせる"} |
+------------+-----------------------------------------+
(5 rows)
regexp_matches関数で「非マッチ行も結果に含める」場合
このようにsubstringとregexp_matchesは、マッチしなかった行が結果に出る/出ないという大きな違いがあります。ちょっと面倒なのは、regexp_matchesで「非マッチ行も結果に含めたい」場合。関数自体にはそういうオプションがないけど、クエリを工夫すればできます。例えば ↓
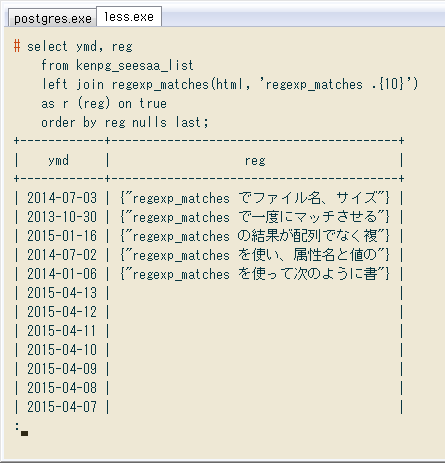
# select ymd, reg
from kenpg_seesaa_list
left join regexp_matches(html, 'regexp_matches .{10}')
as r (reg) on true
order by reg nulls last;
+------------+-----------------------------------------+
| ymd | reg |
+------------+-----------------------------------------+
| 2014-07-03 | {"regexp_matches でファイル名、サイズ"} |
| 2013-10-30 | {"regexp_matches で一度にマッチさせる"} |
| 2015-01-16 | {"regexp_matches の結果が配列でなく複"} |
| 2014-07-02 | {"regexp_matches を使い、属性名と値の"} |
| 2014-01-06 | {"regexp_matches を使って次のように書"} |
| 2015-04-13 | |
| 2015-04-12 | |
| 2015-04-11 | |
| 2015-04-10 | |
| 2015-04-09 | |
...
LEFT JOIN ... ON TRUEという変な構文ですけど。regexp_matchesの結果が非マッチだと「行自体がない」ので、こうやって結合しました。
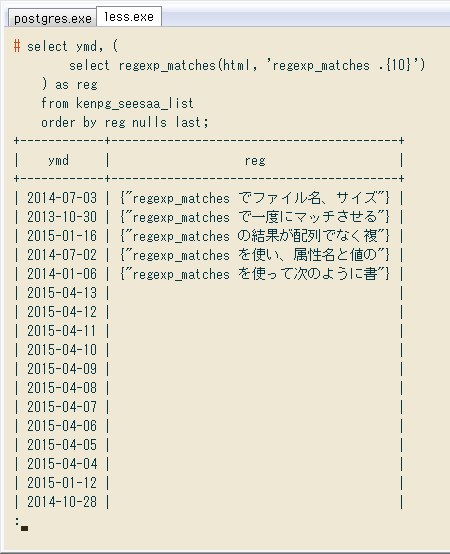
↓ 別の方法。JOINを使わないので理解しやすい反面、SELECT ... FROMの間にもう一つSELECT文が入って見にくいです。
# select ymd, (
select regexp_matches(html, 'regexp_matches .{10}')
) as reg
from kenpg_seesaa_list
order by reg nulls last;
+------------+-----------------------------------------+
| ymd | reg |
+------------+-----------------------------------------+
| 2014-07-03 | {"regexp_matches でファイル名、サイズ"} |
| 2013-10-30 | {"regexp_matches で一度にマッチさせる"} |
| 2015-01-16 | {"regexp_matches の結果が配列でなく複"} |
| 2014-07-02 | {"regexp_matches を使い、属性名と値の"} |
| 2014-01-06 | {"regexp_matches を使って次のように書"} |
| 2015-04-13 | |
| 2015-04-12 | |
| 2015-04-11 | |
| 2015-04-10 | |
| 2015-04-09 | |
...
substringとregexp_matchesの基本的な違い
今回の関心は「POSIX正規表現」で「非マッチ行の扱い」の違いでしたが、それ以前に、この2関数はいろいろ違います。
• 機能
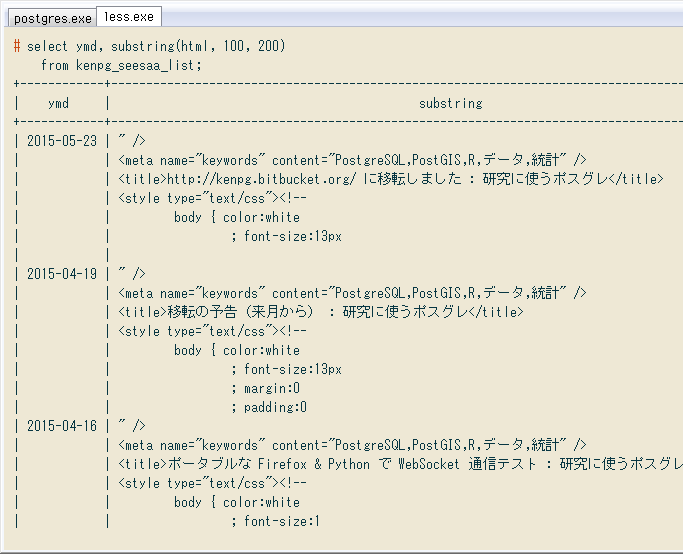
regexp_matchesはPOSIX正規表現専用ですが、substringはPOSIX正規表現だけでなく、文字位置やSQL正規表現での抽出もできます。↓ は前者の例。
# select ymd, substring(html, 100, 200)
from kenpg_seesaa_list;
+------------+-------------------------------------------------------------------------------------------------+
| ymd | substring |
+------------+-------------------------------------------------------------------------------------------------+
| 2015-05-23 | " /> +|
| | <meta name="keywords" content="PostgreSQL,PostGIS,R,データ,統計" /> +|
| | <title>http://kenpg.bitbucket.org/ に移転しました : 研究に使うポスグレ</title> +|
| | <style type="text/css"><!-- +|
| | body { color:white +|
| | ; font-size:13px +|
...
# select ymd, substring(html from 100 for 200)
from kenpg_seesaa_list;
-- same result as above
 • POSIX正規表現のオプション(iほか)
• POSIX正規表現のオプション(iほか)
substringは不可、regexp_matchesはOK(第3引数)。詳細はドキュメントを参照。
• 戻り値
substringは文字列のスカラ、regexp_matchesは文字列の配列。
• 部分マッチがある時(正規表現の丸カッコ内、いわゆる後方参照)
substringは最初の部分を返す(2番目以降は無視)。regexp_matchesは全ての部分を配列の各要素として返す(マッチした全体は返らない)。
• 複数マッチ(gオプション)
substringはオプション不可なので対象外。regexp_matchesは複数の「行」を返す。
• マッチしなかった場合(再掲)
substringはNULLのスカラを返す。regexp_matchesは「無」で当該行が消える。
基本的な違いはこんなところでしょうか。結局、regexp_matches関数の戻り値は「ゼロ~複数行の1列のテーブル」みたいなもので、高機能だけど普通の関数より扱いにくいとも言えます。
できればsubstring関数でiオプションを使いたいところ。「英大・小文字を区別せず、非マッチ時も行を消したくない」場面は結構あると思いますが、現状では ↓ この#1か#2になってしまうので。
-- as of now #1
# select column, column, ... , (
select (regexp_matches(column, pattern, 'i'))[1]
) from foo;
-- as of now #2
# select column, column, ... , reg[1]
from foo
left join regexp_matches(column, pattern, 'i')) as bar (reg)
on true;
-- ideally
# select column, column, ... , substring(column, pattern, 'i')
from foo;