8月22日から作業中の、旧ブログ(Seesaa)の記事検索用にHTMLを整理する件。今日は単なる途中経過で、次回へのつなぎです。今日切り出したHTMLに対し、次回はWITH RECURSIVEとJSONBを使って「複数組の文字列置換」を1クエリでします。
実行環境
• Windows7 x64 + Cygwin 2.5.1 + ConEmu 150813g
• Windows版PostgreSQL 9.5.3 + Cygwin版psql
• Windowsは管理者権限ユーザ、PostgreSQL接続はスーパーユーザ
テーブルに、切り出し後を保存する列を追加
作業は8月22日の最後、実行コマンドまとめを行った状態から。使うテーブルは1つで ↓ こんな構成。列htmlに、旧ブログ各記事のHTMLをそのまま突っ込みました。
# \d kenpg_seesaa_list
Table "public.kenpg_seesaa_list"
+-----------+------+-----------+
| Column | Type | Modifiers |
+-----------+------+-----------+
| ymd | date | |
| url | text | |
| title | text | |
| tags | text | |
| html_file | text | |
| html | text | | <- contents
+-----------+------+-----------+
列htmlには不要部分も多いので、文字検索に必要な部分だけ切り出して新しい列にします。空の列をテーブルに追加し(列名body)、各種の列制約も付加。↓
# alter table kenpg_seesaa_list add body text;
# alter table kenpg_seesaa_list add primary key (ymd);
alter table kenpg_seesaa_list alter url set not null;
alter table kenpg_seesaa_list alter title set not null;
alter table kenpg_seesaa_list alter tags set not null;
alter table kenpg_seesaa_list alter html_file set not null;
alter table kenpg_seesaa_list alter html set not null;
create unique index on kenpg_seesaa_list (url);
# \d kenpg_seesaa_list
Table "public.kenpg_seesaa_list"
+-----------+------+-----------+
| Column | Type | Modifiers |
+-----------+------+-----------+
| ymd | date | not null |
| url | text | not null |
| title | text | not null |
| tags | text | not null |
| html_file | text | not null |
| html | text | not null |
| body | text | |
+-----------+------+-----------+
Indexes:
"kenpg_seesaa_list_pkey" PRIMARY KEY, btree (ymd)
"kenpg_seesaa_list_url_idx" UNIQUE, btree (url)

正規表現での切り出しをSELECT文で確認してからUPDATE
旧ブログのうち<a name="more">~</a>という追記部分は何も入ってなく不要、と前回確認しました。残るのは本文だけで(タイトルは記事リストから既にテーブルに入れた)、それっぽい所をSELECTクエリ → 確認 → 修正を何度か行って、正規表現を決めていきます。
切り出し結果を全部表示すると見づらいので、left関数・right関数で先頭・末尾の任意文字数分だけ抽出して表示すると便利。↓
# select ymd, left(r[1], 30) || '...' || right(r[1], 30)
from kenpg_seesaa_list,
regexp_matches(html,
'main_article">(.+)'
|| '<a name="more"></a></div>\s+<div class="footer nocontent">') as r
order by random();
+------------+-----------------------------------------------------------------------------------------------------------------------------+
| ymd | ?column? |
+------------+-----------------------------------------------------------------------------------------------------------------------------+
| 2015-01-06 | 構文比較のメモ。正確には PostgreSQL の配列型と ...QL の CASE 句と違うので、これも間違いやすいところ。 |
| 2014-11-22 | 前のブログ <a href="http://kenpg.se...crolling="yes"></iframe><br /> |
| 2014-11-10 | <a href="/article/408207238.ht...枚で済みます。それらを参考に、今後いろいろ試行錯誤する予定。 |
| 2015-03-31 | 以下 Windows 7 32bit での作業経過です。元々...reSQL に接続してデータを読み込む環境を整える予定です。 |
| 2014-11-16 | <a href="//kenpg2.seesaa.net/a...ST_Y 関数でY座標値を抽出すれば10進数になっています。 |
| 2014-10-04 | <a href="/article/406128236.ht...tatus);<br /> }<br />}</div> |
| 2014-12-05 | <a href="//www.postgresql.jp/e...x solid; width:320px" /><br /> |
| 2014-10-28 | <a href="//kenpg2.seesaa.net/a...t/image/20141028_pga_1.png" /> |
| 2014-12-06 | <a href="/article/409350194.ht...- Ordinary Day</a>(2002)<br /> |
| 2015-02-27 | <a href="/article/414487346.ht...があれば、一部でも自動化できないか調べてみます。<br /> |
| 2014-11-06 | <a href="//kenpg2.seesaa.net/a...持っていけるようになり、連携の幅が広がるのは確実です ≧▽≦ |
| 2014-12-30 | 12月18日に PostgreSQL 9.4.0 が正式リリ....net/image/20141230_20.png" /> |
| 2015-01-16 | PostgreSQL の xpath 関数を使っていると、例...hes の結果が配列でなく複数行なので、少し長くなりました。 |
| 2014-10-31 | 10月31日に PostGIS ラスタについて話すというか講...を ST_ColorMap で使う(2)</a><br /> |
...
(196 rows)
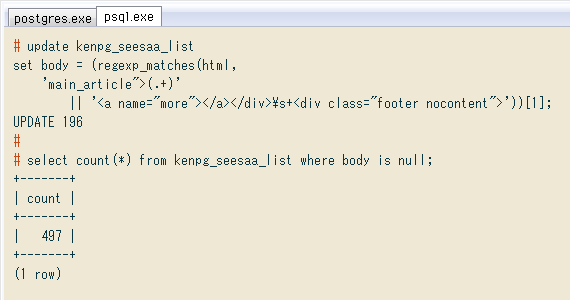
 切り出し結果だけ見ると良さげだけど、行数が196。全記事数は693で、この正規表現ではマッチしないのが相当あるっぽい。でも、UPDATE時はマッチした行だけ変わる(非マッチ行には、元と同じNULLが再入力される)ので、とりあえず入力しちゃいます。SELECT ... FROMからUPDATE ... SETの文に組み替えるだけ。↓ 処理残は、切り出し後の列bodyがNULLの行を数えます(497行)。
切り出し結果だけ見ると良さげだけど、行数が196。全記事数は693で、この正規表現ではマッチしないのが相当あるっぽい。でも、UPDATE時はマッチした行だけ変わる(非マッチ行には、元と同じNULLが再入力される)ので、とりあえず入力しちゃいます。SELECT ... FROMからUPDATE ... SETの文に組み替えるだけ。↓ 処理残は、切り出し後の列bodyがNULLの行を数えます(497行)。
# update kenpg_seesaa_list
set body = (regexp_matches(html,
'main_article">(.+)'
|| '<a name="more"></a></div>\s+<div class="footer nocontent">'))[1];
UPDATE 196
# select count(*) from kenpg_seesaa_list where body is null;
+-------+
| count |
+-------+
| 497 |
+-------+
(1 row)
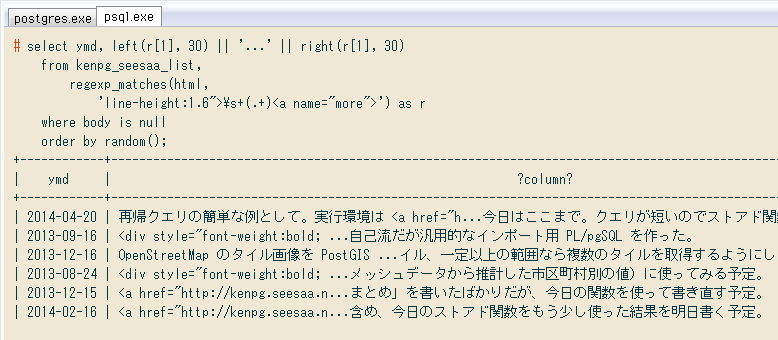
 残った分につき、また正規表現をいくつか試すと ↓ こんな感じで本文を抽出できました。上と同様にUPDATEしますが、念のため更新対象の行をWHERE body is nullと絞り込み。でないと、先に入力済みの行を誤って上書きするかもしれないので。(まぁその時は先のクエリを再実行すればいいけど。SQLはこのへん気楽です)
残った分につき、また正規表現をいくつか試すと ↓ こんな感じで本文を抽出できました。上と同様にUPDATEしますが、念のため更新対象の行をWHERE body is nullと絞り込み。でないと、先に入力済みの行を誤って上書きするかもしれないので。(まぁその時は先のクエリを再実行すればいいけど。SQLはこのへん気楽です)
# select ymd, left(r[1], 30) || '...' || right(r[1], 30)
from kenpg_seesaa_list,
regexp_matches(html,
'line-height:1.6">\s+(.+)<a name="more">') as r
where body is null
order by random();
+------------+-----------------------------------------------------------------------------------------------------------------------------+
| ymd | ?column? |
+------------+-----------------------------------------------------------------------------------------------------------------------------+
| 2014-04-20 | 再帰クエリの簡単な例として。実行環境は <a href="h...今日はここまで。クエリが短いのでストアド関数にはしなかった。 |
| 2013-09-16 | <div style="font-weight:bold; ...自己流だが汎用的なインポート用 PL/pgSQL を作った。 |
| 2013-12-16 | OpenStreetMap のタイル画像を PostGIS ...イル、一定以上の範囲なら複数のタイルを取得するようにしたい。 |
| 2013-08-24 | <div style="font-weight:bold; ...メッシュデータから推計した市区町村別の値)に使ってみる予定。 |
| 2013-12-15 | <a href="http://kenpg.seesaa.n...まとめ」を書いたばかりだが、今日の関数を使って書き直す予定。 |
| 2014-02-16 | <a href="http://kenpg.seesaa.n...含め、今日のストアド関数をもう少し使った結果を明日書く予定。 |
...
# update kenpg_seesaa_list
set body = (regexp_matches(html,
'line-height:1.6">\s+(.+)<a name="more">'))[1]
where body is null;
UPDATE 497
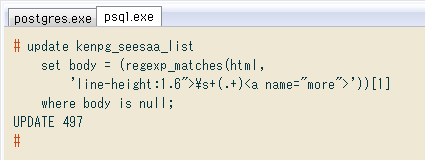 UPDATEの結果497行が変更され、処理残は一気に解消。HTML切り出しのパターンは結局2つで、旧ブログの最初/小リニューアル後それぞれが同じでした。途中で細々と変更してなくてよかった...。
UPDATEの結果497行が変更され、処理残は一気に解消。HTML切り出しのパターンは結局2つで、旧ブログの最初/小リニューアル後それぞれが同じでした。途中で細々と変更してなくてよかった...。
# select count(*) from kenpg_seesaa_list where body is null;
+-------+
| count |
+-------+
| 0 |
+-------+
(1 row)
(余談)記事の長さの度数分布を出してみる
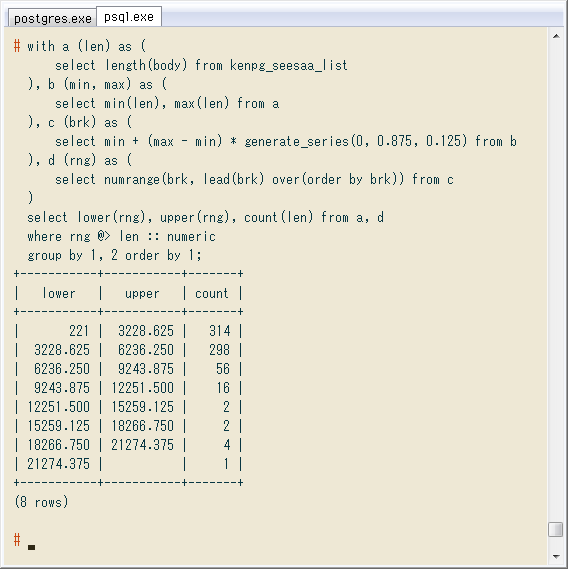
今日の作業はここまで。ちょっと物足りないので、抽出した記事本文の長さ(文字数。非ASCIIも1字)の度数分布をSQLで出してみます。
パーセンタイルだと「度数を等しくした区分」ですが、度数分布は普通「数値間隔を等しくした区分」でのカウント。PostgreSQLでは直接出す関数がないので範囲型を使い、少し長いクエリに ↓ なりました。改良できたら追記します。
# with a (len) as (
select length(body) from kenpg_seesaa_list
), b (min, max) as (
select min(len), max(len) from a
), c (brk) as (
select min + (max - min) * generate_series(0, 0.875, 0.125) from b
), d (rng) as (
select numrange(brk, lead(brk) over(order by brk)) from c
)
select lower(rng), upper(rng), count(len) from a, d
where rng @> len :: numeric
group by 1, 2 order by 1;
+-----------+-----------+-------+
| lower | upper | count |
+-----------+-----------+-------+
| 221 | 3228.625 | 314 |
| 3228.625 | 6236.250 | 298 |
| 6236.250 | 9243.875 | 56 |
| 9243.875 | 12251.500 | 16 |
| 12251.500 | 15259.125 | 2 |
| 15259.125 | 18266.750 | 2 |
| 18266.750 | 21274.375 | 4 |
| 21274.375 | | 1 |
+-----------+-----------+-------+
(8 rows)
最後の行は、本当は範囲の上限(全体での最大値)が入るべきところ、クエリがさらに面倒になるので省きました。これ見ると200~20000で右裾にかなり広いです。たまに1万字以上もあったり。たぶんQtアプリのソースをまとめて載せた回じゃないかな。
次回HTMLの不要部分を削除or置換したら、同様の度数分布を出してみます。まぁ大勢は変わらないと思いますけど。