作業内容は8月22日から続く旧ブログ(Seesaa)の記事検索用。全693個の過去記事から本文を切り出した(前回)のに続き、細かい整形をします。検索に不要なSTYLE属性を消したりプログラム中の<BR>を改行に変えたり。
ここでPHPみたいに正規表現に配列を使って一度にしたいところ、PostgreSQLの関数は一組の置換しかできないので、今日は再帰クエリWITH RECURSIVEを使いました。あと複数の正規表現を2次元配列にする際、配列型とJSON型で少し比較してます。
実行環境
• Windows7 x64 + Cygwin 2.5.1 + ConEmu 150813g
• Windows版PostgreSQL 9.5.3 + Cygwin版psql
• Windowsは管理者権限ユーザ、PostgreSQL接続はスーパーユーザ
作業中テーブルの現状
前回、HTMLの本文を切り出した後のテーブルは ↓ こうです。body列が本文で、今日はこれを整形。
# \d kenpg_seesaa_list
Table "public.kenpg_seesaa_list"
+-----------+------+-----------+
| Column | Type | Modifiers |
+-----------+------+-----------+
| ymd | date | not null |
| url | text | not null |
| title | text | not null |
| tags | text | not null |
| html_file | text | not null |
| html | text | not null |
| body | text | | <- extracted
+-----------+------+-----------+
Indexes:
"kenpg_seesaa_list_pkey" PRIMARY KEY, btree (ymd)
"kenpg_seesaa_list_url_idx" UNIQUE, btree (url)
 ↓ body列の中身の例。一時的に入れたSTYLE属性が結構あり、文字検索には不要なので消したいです。またコード部分の改行がBRタグなのも元に戻したい。
↓ body列の中身の例。一時的に入れたSTYLE属性が結構あり、文字検索には不要なので消したいです。またコード部分の改行がBRタグなのも元に戻したい。
# select ymd, left(body, 100)
from kenpg_seesaa_list
order by random();
+------------+-------------------------------------------------------------------------------------------------------------
| ymd | left
+------------+-------------------------------------------------------------------------------------------------------------
| 2013-08-11 | <div style="font-weight:bold; margin:5px 0">1. 今日やったこと</div>総務省の次世代統計利用システムのメッシュ
| 2014-03-02 | <a href="http://kenpg.seesaa.net/article/385859928.html">2014/01/22</a> 以降何回か紹介したように、東芝のノー
| 2014-03-06 | <a href="http://kenpg.seesaa.net/article/361225990.html">2013/05/23</a> と <a href="http://kenpg.sees
| 2014-09-23 | ↑ を昨年 <a href="https://www.postgresql.jp/events/jpug-pgcon2013">PostgreSQL カンファレンス 2013</a> での
| 2013-07-16 | <div style="border:red 1px solid; margin:0; padding:10px">追記(2015/01/29)<br />もっと簡単な方法がありまし
...
# select ymd, regexp_matches(body, 'SELECT.{100}')
from kenpg_seesaa_list
order by random();
+------------+-------------------------------------------------------------------------------------------------------------
| ymd | regexp_matche
+------------+-------------------------------------------------------------------------------------------------------------
| 2014-07-24 | {"SELECT 139.58 x -- 経度<br /> , 35.84 y -- 緯度<br /> , 4612 srid
| 2015-01-17 | {"SELECT ST_AsText(ST_Intersection(g1, g2))<br />FROM ST_GeomFromText('POLYGON((0 0, 0 2, 2 2, 2 0, 0 0))')
| 2015-01-20 | {"SELECT 2013 iso_year, 52 iso_week<br /> UNION ALL SELECT 2014, 1<br />), b AS (<br /> SELECT *<br
| 2015-01-12 | {"SELECT text '<br /> // ここに CSV を貼り付ける<br /> // 行頭インデントしたらクエリ内の正規表現で
| 2014-10-13 | {"SELECT now();¥n\";<br /> setupWindow(tr(\"QPg SQL Client\"));<br /> statusBar()->hide();<br /> cr
...
複数の文字列置換を一度に行うクエリ
ここではSELECT文で置換後の文字列を得るまでを考え、実データをUPDATEする部分は置いときます。
(1)置換する数が少なければ、原始的にregexp_replaceを入れ子にするのが ↓ 簡単。実際これで済ますことも結構あったり。
select
regexp_replace(
regexp_replace(
regexp_replace(column, pattern, rep, option),
pattern, rep, option),
pattern, rep, option)
from foo;
(2)上の難点は、「この置換は正規表現でなくreplace関数で済むので、変えたい」などの部分が出た時に面倒なこと。関数と引数が離れてるので。そこで置換操作をFROMの後に置くと ↓ それはし易くなります。
select t3
from foo,
regexp_replace(column, pattern, rep, option) as t1,
regexp_replace(t1, pattern, rep, option) as t2,
replace(t2, pattern, rep) as t3;
どちらにしても、置換パターンの追加・削除・入れ替えが面倒です。実際クエリを作っていく時、最も必要なのがそういう試行錯誤。
(3)そこで今回は ↓ こうしました。使う関数はregexp_replaceに一本化し、置換パターンを2次元配列に入れてWITH RECURSIVEで順番に実行。クエリは一気に長くなったけど、正規表現の試行錯誤が2次元配列の操作だけで楽にできます。
with recursive a (ary) as (
select array[
[pattern, rep, option],
[pattern, rep, option],
[pattern, rep, option]
]
), r (ary, len, rid, column) as (
select
ary, array_length(ary, 1), 0, column
from a, foo
union all
select
ary, len, rid + 1,
regexp_replace(column, ary[rid][1], ary[rid][2], ary[rid][3])
from r
where rid <= len + 1
)
select ymd, left(body, 100) from r
where rid = len + 1;
(4)上の2次元配列をJSONBに変換して行うと ↓ こんな感じ。配列型と違って2次元配列の要素を取り出すと1次元になるので、それを使ってます。添字がゼロ始まりなのも配列型と違う点(下記の赤い部分が変化)。
with recursive a (jsonb) as (
select to_jsonb(array[
[pattern, rep, option],
[pattern, rep, option],
[pattern, rep, option]
])
), r (jsonb, len, rid, column) as (
select
jsonb, jsonb_array_length(jsonb), 0, column
from a, foo
union all
select
jsonb, len, rid + 1,
regexp_replace(column, js->>0, js->>1, js->>2)
from r, cast(jsonb->rid as jsonb) as js
where rid <= len
)
select column from r
where rid = len;
再帰クエリはどうしても長くなりがち。普通にループを使えるストアド関数を作る方が簡単だけど、SQLだけでアドホックに実行できるのは利点です。
配列型とJSON型の比較(定義時の書きやすさ)
以下、JSONB型を含めてJSONと略します。定義の際、配列は正規表現パターンをシングルクォートするだけなので楽。JSONは全体をシングルで囲って文字列をダブルで囲むため、パターンがダブルクォートを含む場合(特に今回のHTML)はエスケープが必要になって見づらい。だから前項のクエリ(4)は、配列で定義した後to_jsonb関数で変換しました。この関数はとても有難い存在。
-- ARRAY
# select array['style="[^"]*"', ''] :: text[];
+-------------------------+
| {"style=\"[^\"]*\"",""} |
+-------------------------+
-- JSONB
# select '["style=\"[^\"]*\"", ""]' :: jsonb;
+--------------------------+
| ["style=\"[^\"]*\"", ""] |
+--------------------------+
配列型とJSON型の比較(多次元配列の扱い)
書きやすさは配列>JSONな一方、多次元配列の扱いは逆。というかPostgreSQLの多次元配列はちょっと異質で「要素を取り出しても次元は同じ」。普通はできる「2次元配列 → 各要素を取り出して1次元配列 → 添字1つで各要素にアクセス」ができません。
JSON型は普通と同じで ↓ 要素を取り出すごとに次元が下がっていきます。->はJSONの配列に添字でアクセスするPostgreSQLの演算子。
# select '[ [ "a", "b" ], [ "c", "d"] ]' :: jsonb;
+--------------------------+
| [["a", "b"], ["c", "d"]] |
+--------------------------+
# select '[ [ "a", "b" ], [ "c", "d"] ]' :: jsonb -> 0;
+------------+
| ["a", "b"] |
+------------+
# select '[ [ "a", "b" ], [ "c", "d"] ]' :: jsonb -> 0 -> 0;
+----------+
| "a" |
+----------+
一方、PostgreSQLの多次元配列は独特。例えば2次元配列から1レベル下を取り出す添字を[■:■][■:■]と書く必要があり、取り出しても次元は変わらず。[■][■]でアクセスして初めてスカラになります。↓
# select array[ [ 'a', 'b' ], [ 'c', 'd'] ];
+---------------+
| {{a,b},{c,d}} |
+---------------+
# select (array[ [ 'a', 'b' ], [ 'c', 'd'] ])[1]; -- NG
+-------+
| |
+-------+
# select (array[ [ 'a', 'b' ], [ 'c', 'd'] ])[1:1][1:2];
+---------+
| {{a,b}} |
+---------+
# select (array[ [ 'a', 'b' ], [ 'c', 'd'] ])[1:1][1];
+-------+
| {{a}} |
+-------+
# select (array[ [ 'a', 'b' ], [ 'c', 'd'] ])[1][1]);
+--------+
| a |
+--------+
今回はどちらでも大差なかったけど、途中で1次元配列も何らか使う場合はJSONの方が便利な気がします。
実際のクエリと結果
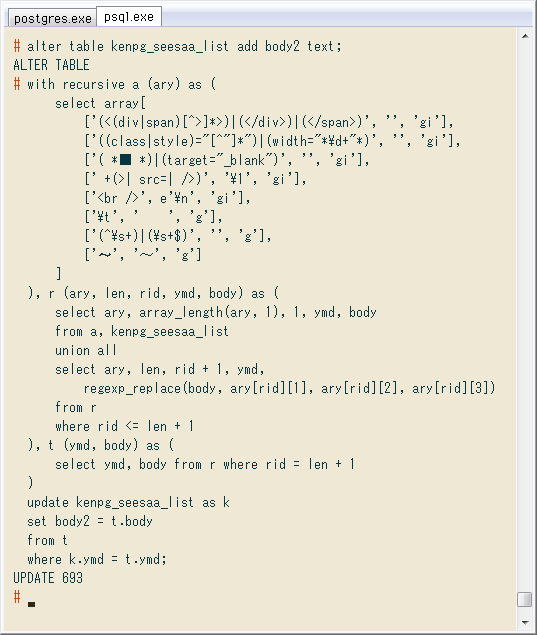
まずSELECT文で正規表現をいろいろ試し、かつ複数組の置換がきちんと行われているか確認します。↓ は元テーブルからランダムに1行取り出し、再帰クエリでの各行(元の文字列 + 一つ一つの置換結果)を出すもの。
# with recursive a (ary) as (
select array[
['(<(div|span)[^>]*>)|(</div>)|(</span>)', '', 'gi'],
['((class|style)="[^"]*")|(width="*\d+"*)', '', 'gi'],
['( *■ *)|(target="_blank")', '', 'gi'],
[' +(>| src=| />)', '\1', 'gi'],
['<br />', e'\n', 'gi'],
['\t', ' ', 'g'],
['(^\s+)|(\s+$)', '', 'g'],
['〜', '~', 'g']
]), r (ary, len, rid, ymd, body) as (
(select ary, array_length(ary, 1), 1, ymd, body
from a, kenpg_seesaa_list
order by random() limit 1)
union all
select ary, len, rid + 1, ymd,
regexp_replace(body, ary[rid][1], ary[rid][2], ary[rid][3])
from r
where rid <= len + 1
)
select rid, len, length(body), left(body, 100) from r;
+-----+-----+--------+-------------------------------------------------------------------
| rid | len | length |
+-----+-----+--------+-------------------------------------------------------------------
| 1 | 8 | 3877 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 2 | 8 | 3556 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 3 | 8 | 3454 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 4 | 8 | 3418 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 5 | 8 | 3413 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 6 | 8 | 3088 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 8 | 8 | 3145 | ある時系列データを処理する中、任意の年・月の全日付(初日〜末日)を
| 9 | 8 | 3145 | ある時系列データを処理する中、任意の年・月の全日付(初日~末日)を
| 10 | 8 | |
+-----+-----+--------+-------------------------------------------------------------------
(10 rows)
 見やすさのため、クエリの最後で文字長と先頭100字に絞って出力してます。正規表現パターンは8つあり、元の文字列を足した9行が出てます。最後の正規表現が「波ダッシュ → 全角チルダ」で、上の結果も確かにそのとおり。
とりあえず今回はこのパターンで良しとし、新しい列を作って置換結果を保存します。元テーブルとの結合は主キーymdで。
見やすさのため、クエリの最後で文字長と先頭100字に絞って出力してます。正規表現パターンは8つあり、元の文字列を足した9行が出てます。最後の正規表現が「波ダッシュ → 全角チルダ」で、上の結果も確かにそのとおり。
とりあえず今回はこのパターンで良しとし、新しい列を作って置換結果を保存します。元テーブルとの結合は主キーymdで。
# alter table kenpg_seesaa_list add body2 text;
# with recursive a (ary) as (
select array[
['(<(div|span)[^>]*>)|(</div>)|(</span>)', '', 'gi'],
['((class|style)="[^"]*")|(width="*\d+"*)', '', 'gi'],
['( *■ *)|(target="_blank")', '', 'gi'],
[' +(>| src=| />)', '\1', 'gi'],
['<br />', e'\n', 'gi'],
['\t', ' ', 'g'],
['(^\s+)|(\s+$)', '', 'g'],
['〜', '~', 'g']
]
), r (ary, len, rid, ymd, body) as (
select ary, array_length(ary, 1), 1, ymd, body
from a, kenpg_seesaa_list
union all
select ary, len, rid + 1, ymd,
regexp_replace(body, ary[rid][1], ary[rid][2], ary[rid][3])
from r
where rid <= len + 1
), t (ymd, body) as (
select ymd, body from r where rid = len + 1
)
update kenpg_seesaa_list as k
set body2 = t.body
from t
where k.ymd = t.ymd;
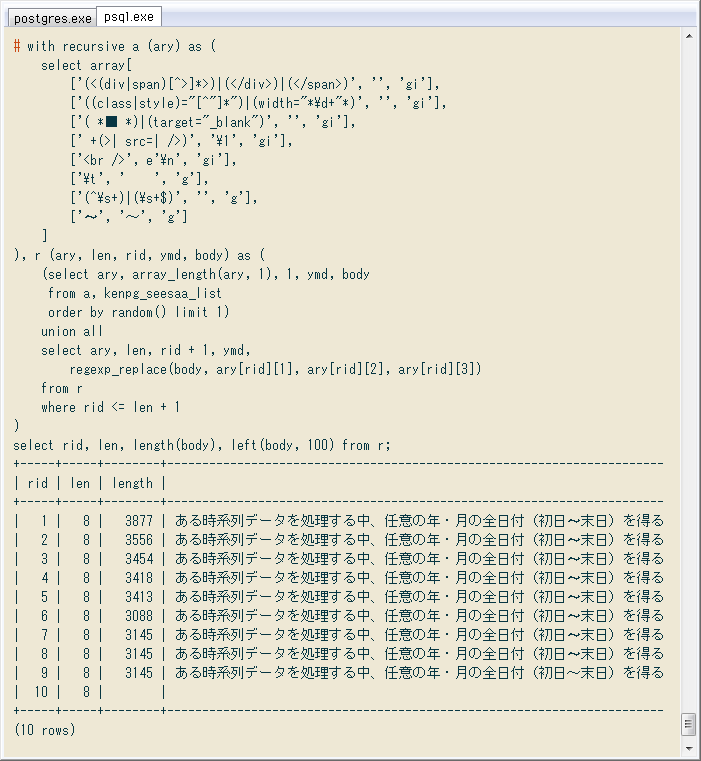
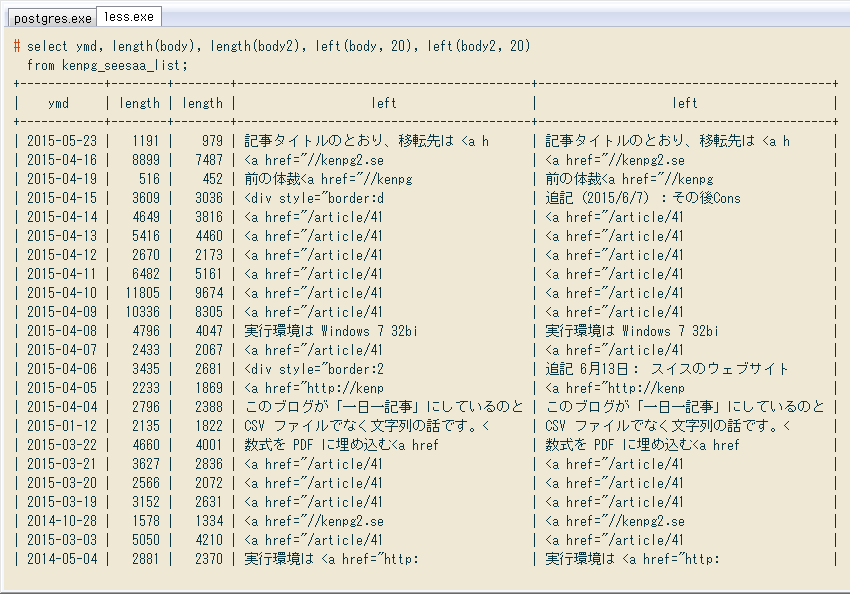
↓ 結果の確認。置換前後の列の文字数と先頭を出してます。
# select ymd, length(body), length(body2),
left(body2, 20), left(body2, 20)
from kenpg_seesaa_list;
+------------+--------+--------+--------------------------------------+--------------------------------------+
| ymd | length | length | left | left |
+------------+--------+--------+--------------------------------------+--------------------------------------+
| 2015-05-23 | 1191 | 979 | 記事タイトルのとおり、移転先は <a h | 記事タイトルのとおり、移転先は <a h |
| 2015-04-16 | 8899 | 7487 | <a href="//kenpg2.se | <a href="//kenpg2.se |
| 2015-04-19 | 516 | 452 | 前の体裁<a href="//kenpg | 前の体裁<a href="//kenpg |
| 2015-04-15 | 3609 | 3036 | <div style="border:d | 追記(2015/6/7):その後Cons |
| 2015-04-14 | 4649 | 3816 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-13 | 5416 | 4460 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-12 | 2670 | 2173 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-11 | 6482 | 5161 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-10 | 11805 | 9674 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-09 | 10336 | 8305 | <a href="/article/41 | <a href="/article/41 |
| 2015-04-08 | 4796 | 4047 | 実行環境は Windows 7 32bi | 実行環境は Windows 7 32bi |
...
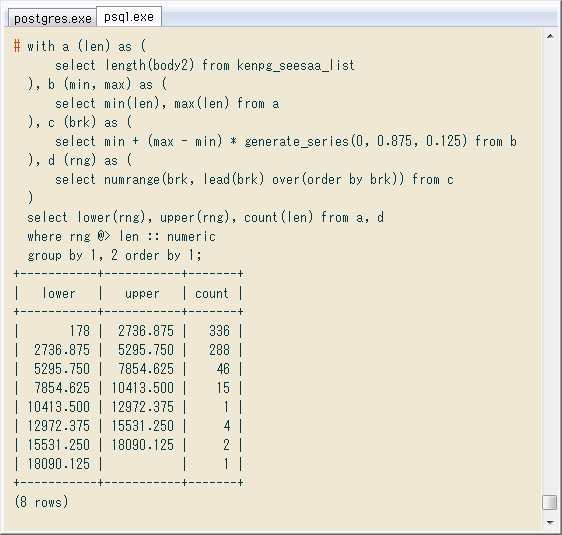
 前回の最後に出した文字数の度数分布を、置換後でもやってみました。↓ 予想どおり大勢は変わらず。最大の記事が21,000字 → 18,000字になったくらい。
前回の最後に出した文字数の度数分布を、置換後でもやってみました。↓ 予想どおり大勢は変わらず。最大の記事が21,000字 → 18,000字になったくらい。
# with a (len) as (
select length(body2) from kenpg_seesaa_list
), b (min, max) as (
select min(len), max(len) from a
), c (brk) as (
select min + (max - min) * generate_series(0, 0.875, 0.125) from b
), d (rng) as (
select numrange(brk, lead(brk) over(order by brk)) from c
)
select lower(rng), upper(rng), count(len) from a, d
where rng @> len :: numeric
group by 1, 2 order by 1;
+-----------+-----------+-------+
| lower | upper | count |
+-----------+-----------+-------+
| 178 | 2736.875 | 336 |
| 2736.875 | 5295.750 | 288 |
| 5295.750 | 7854.625 | 46 |
| 7854.625 | 10413.500 | 15 |
| 10413.500 | 12972.375 | 1 |
| 12972.375 | 15531.250 | 4 |
| 15531.250 | 18090.125 | 2 |
| 18090.125 | | 1 |
+-----------+-----------+-------+
(8 rows)
-- before replacement
-- http://kenpg.bitbucket.org/blog/201608/25.html
+-----------+-----------+-------+
| lower | upper | count |
+-----------+-----------+-------+
| 221 | 3228.625 | 314 |
| 3228.625 | 6236.250 | 298 |
| 6236.250 | 9243.875 | 56 |
| 9243.875 | 12251.500 | 16 |
| 12251.500 | 15259.125 | 2 |
| 15259.125 | 18266.750 | 2 |
| 18266.750 | 21274.375 | 4 |
| 21274.375 | | 1 |
+-----------+-----------+-------+
 これで、8月22日から続いてたHTMLの整理は一段落。ようやく記事検索の仕組みを検討するのに移ります。場合によっては今日の作業を、正規表現を修正してやり直すかもしれないけど、クエリの2次元配列を変えるだけなので気が楽です。
これで、8月22日から続いてたHTMLの整理は一段落。ようやく記事検索の仕組みを検討するのに移ります。場合によっては今日の作業を、正規表現を修正してやり直すかもしれないけど、クエリの2次元配列を変えるだけなので気が楽です。